TiRex-2: Multivariate xLSTM Forecasting With Covariates and Streaming State
TiRex-2 turns NX-AI's compact xLSTM forecaster into a multivariate, covariate-aware, streaming time series foundation model.
NX-AI's original TiRex was interesting because it took a different path from the Transformer-heavy time series foundation model stack. Instead of flattening patches into attention blocks, it used xLSTM to make recurrent state tracking competitive for zero-shot forecasting. The tradeoff was narrowness: the public forecasting release was best understood as a compact univariate model with point and quantile outputs.
TiRex-2 changes that boundary. The new paper, TiRex-2: Generalizing TiRex to Multivariate Data and Streaming, was posted on July 1, 2026 and reframes the TiRex line around three capabilities that matter in production: joint multivariate forecasting, both past and future-known covariates, and streaming inference that updates a recurrent state instead of recomputing the full history. On TSFM.ai, the hosted NX-AI/TiRex-2 entry lists 38.4M active parameters in univariate mode, plus another 44.1M parameters when the multivariate path is engaged.
That makes TiRex-2 more than a larger TiRex checkpoint. It is a technical answer to a practical gap in the TSFM landscape: how do you keep the efficiency and statefulness of a recurrent model while adding the cross-variate reasoning and covariate handling that real forecasting systems need?
The closest existing TSFM.ai posts are our original TiRex overview, the covariates guide, and the state of multivariate forecasting. This post is distinct because it focuses on the TiRex-2 paper: the architecture changes, the target-causality trick, the synthetic multivariate pretraining pipeline, and what streaming xLSTM inference changes operationally.
#What Changed From TiRex
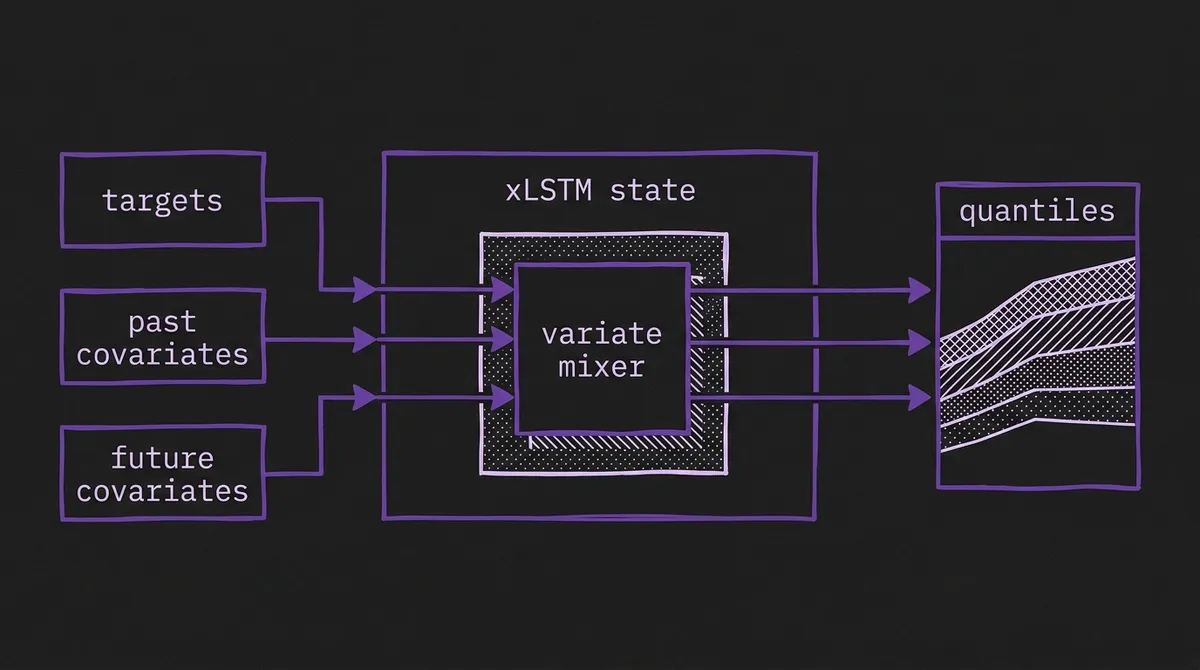
The original TiRex paper argued that recurrent state tracking remains useful for long-horizon forecasting and that xLSTM can recover enough in-context learning behavior to compete with Transformer TSFMs. TiRex-2 keeps that thesis, but the model surface is different.
| Capability | TiRex | TiRex-2 |
|---|---|---|
| Core backbone | xLSTM, primarily framed as compact zero-shot forecasting | xLSTM stack with alternating mLSTM and sLSTM blocks |
| Target shape | Univariate forecasting surface | Multivariate targets plus univariate fallback |
| Covariates | Not documented in the public forecasting release | Past covariates and future-known covariates |
| Cross-variate modeling | No native multivariate path in the public release | Asymmetric grouped-attention variate mixer |
| Streaming | Recurrent architecture, but not the paper's central deployment claim | Constant-cost state updates per patch under streaming |
| Output | Point and quantile forecasts | Quantile forecasts trained with pinball loss |
The most important row is covariates. In our covariates guide, TiRex was a cautionary example: a strong zero-shot model that should not be treated as covariate-capable unless the official release says so. TiRex-2 is the future version that earlier users were waiting for. It can condition on observed historical covariates, such as related sensors or past weather, and future-known covariates, such as calendar features, planned events, schedules, or promotion flags.
The second important row is streaming. Most hosted TSFMs are naturally batch systems: assemble a context window, run inference, emit a forecast, and do it again when the window advances. TiRex-2 is designed around an incremental state update. That makes it relevant to the real-time streaming inference problem, where the cost of refreshing a forecast every few seconds or minutes can matter as much as leaderboard accuracy.
#The Architecture: Time Mixer Plus Variate Mixer
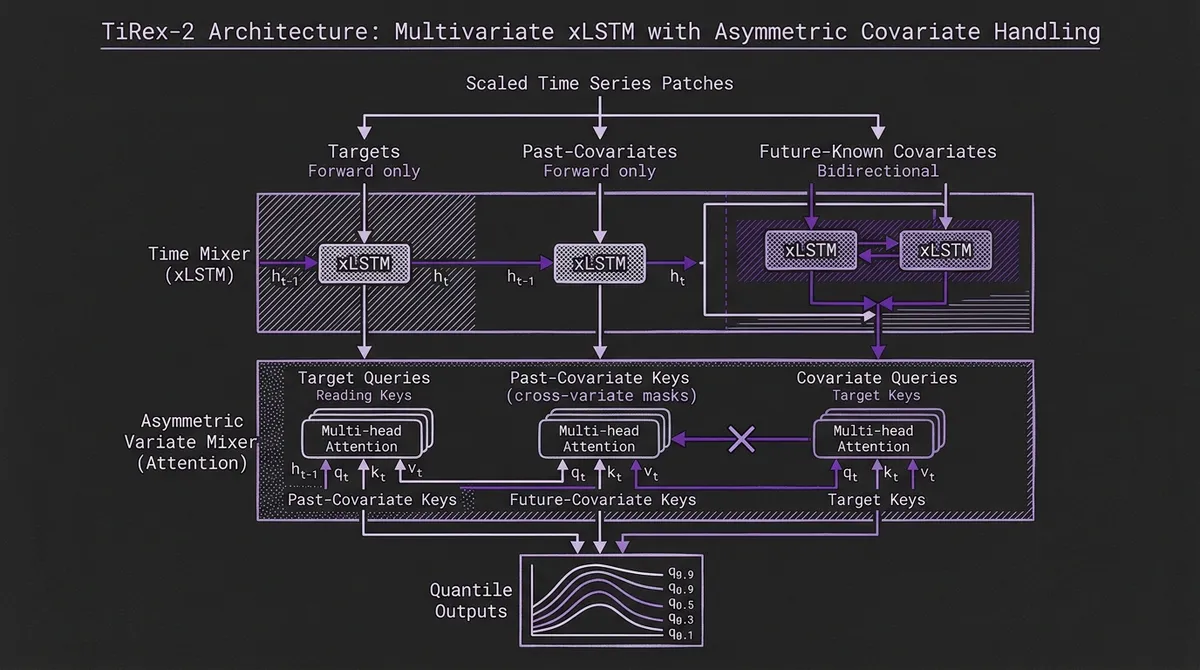
TiRex-2 splits the problem into two kinds of mixing.
The time mixer operates along the patch axis for each variate. Targets and past covariates are processed forward only, preserving causality. Future-known covariates get a bidirectional treatment: a forward xLSTM pass and a weight-tied reverse pass are fused so those covariate tokens can use information from both before and after their position. That is exactly what future-known covariates are for. A holiday flag or scheduled maintenance window is not secret future target data; it is known ahead of the forecast.
The variate mixer operates across variables at the same patch position. This is where TiRex-2 departs most sharply from the original TiRex. The paper uses multi-head self-attention along the variate axis, with block-diagonal grouping so different series in the batch do not leak into one another. Within each group, it applies an asymmetric mask: target queries may read covariate keys, but covariate queries cannot read target keys.
That asymmetry is the load-bearing idea. If future-known covariates can look backward and forward through time, then a naive symmetric cross-variate mixer could accidentally route future target information into a covariate token and then back into a target prediction. TiRex-2 blocks that path. Future-known covariates can inform targets, but covariates cannot read targets in a way that would create target leakage.
This lets the model use bidirectional covariate context while keeping target streams strictly causal in a single forward pass. In practical terms, it is the difference between "we support covariates" and "we support future-known covariates without cheating."
#Why Streaming Is a Real Architectural Claim
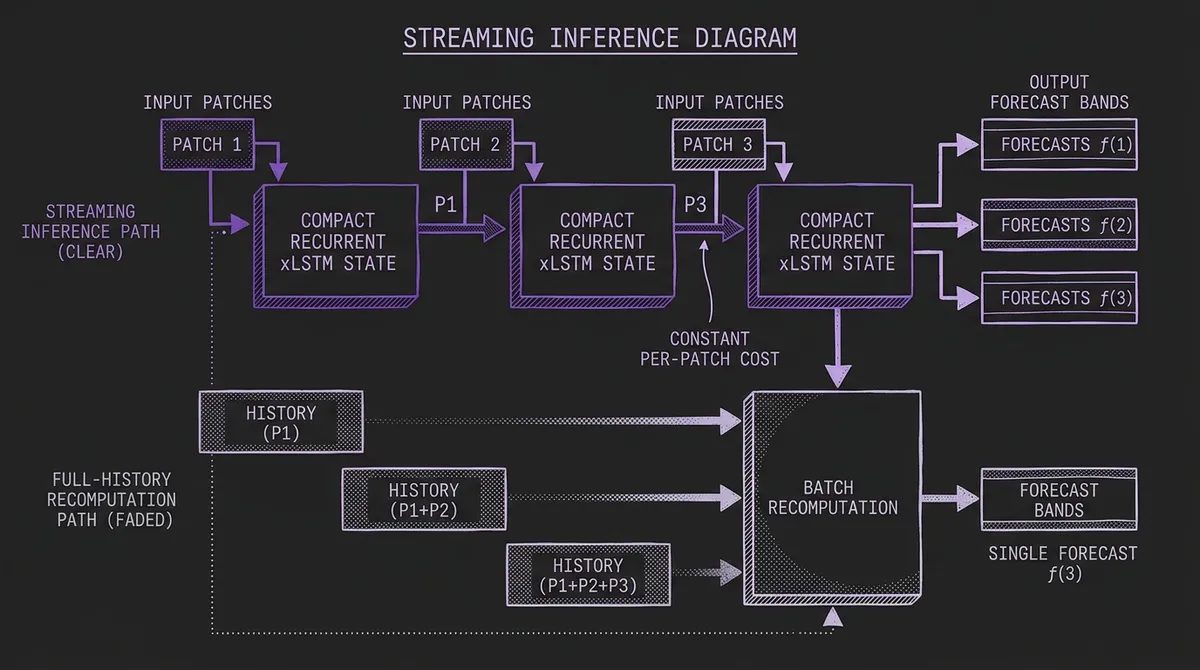
Streaming forecasting is not just low latency batch inference. In a batch design, every update usually re-encodes the rolling context window. Even if the newest observation is the only thing that changed, the model still pays most of the context-processing cost again. Attention-based models can reuse some cached state in some settings, but cross-variate and long-context forecasting still tends to make the serving path more expensive as context grows.
TiRex-2's recurrent time mixer gives the paper a stronger claim: ingest patches sequentially, update the model state, and emit refreshed forecasts at constant per-patch cost. The paper evaluates this by streaming a long autoregressive process with a lagged noisy covariate and reports stable quality even far beyond the post-training context boundary.
That matters for several workloads:
- industrial sensors, where the model should update as readings arrive;
- grid and energy telemetry, where load, price, generation, and weather move together;
- observability metrics, where forecasts should refresh as services change state;
- logistics and transportation, where related route or station series arrive continuously.
This does not mean every TiRex-2 deployment should be true per-event streaming. Most teams should still start with micro-batches and measure actual decision latency. But the architecture gives TiRex-2 a different scaling profile from a model that must repeatedly attend over the whole context.
#Synthetic Multivariate Coupling
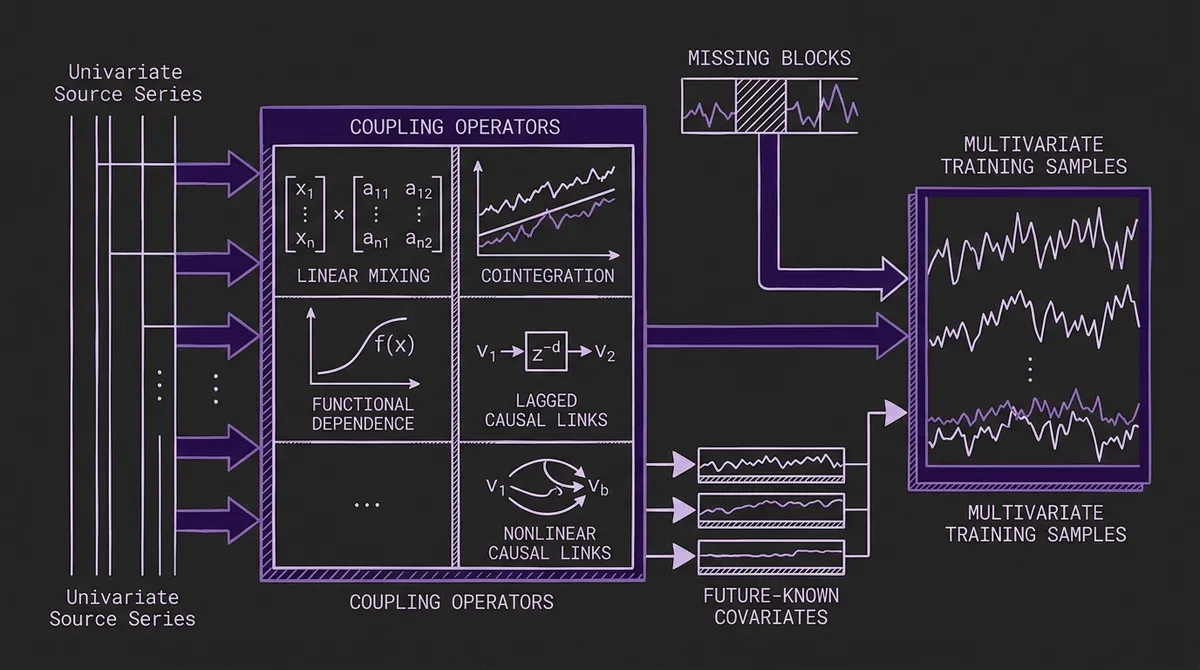
The hardest part of training a multivariate TSFM is not only the model. It is the data. Large univariate corpora exist; clean, diverse, leakage-controlled multivariate corpora with covariates are much harder to assemble.
TiRex-2 addresses that with a synthetic coupling pipeline. Instead of relying only on naturally multivariate datasets, the paper constructs multivariate training instances on the fly from univariate sources. The coupling mechanisms include independent noise, functional relationships, linear mixing, cointegration, lagged linear structural causal models, and nonlinear structural causal models. The generated samples are then enriched with covariate-like structure: variate permutation, smooth time warping, contiguous missing blocks, partial future observability, and discretized values or time steps.
This is not decorative augmentation. It is an attempt to teach the model the kinds of cross-variable relationships that show up in real systems:
- shared latent drivers, as in macro factors or regional weather;
- long-run equilibria, as in cointegrated economic or energy series;
- direct sensor redundancy, where one channel is a transformed version of another;
- lagged causal effects, where one variable leads another by a few steps;
- sparse binary covariates, such as schedules, duty cycles, or event flags.
That pipeline is also why practitioners should evaluate TiRex-2 on their own dependency structure. A synthetic pretraining distribution can cover more dependency shapes than a small benchmark suite, but it is still a prior. The question in production is whether that prior matches the correlations, lags, missingness, and covariate reliability in your data.
#Evaluation: Strong Benchmarks, Careful Caveats
The TiRex-2 paper evaluates zero-shot forecasting on FEV Bench and GIFT-Eval. It reports state-of-the-art results on both: FEV Bench for covariate-aware zero-shot forecasting, and GIFT-Eval for broader probabilistic generalization across domains, frequencies, and horizons.
One detail is worth calling out: the authors train separate benchmark-specific checkpoints with overlapping datasets removed from the relevant training corpus. That is the right instinct. TSFM benchmark leakage is easy to create and hard to diagnose, especially when pretraining draws from public forecasting archives. A high score is more meaningful when the paper is explicit about which evaluation data was excluded from pretraining.
The comparison set also matters. On FEV Bench, the paper compares against Chronos-Bolt, Moirai-2, Toto-1.0, TiRex, TimesFM-2.5, and Chronos-2. On GIFT-Eval, it compares against Chronos-2-Synth, PatchTST-FM-r1, TiRex, TimesFM-2.5, FlowState-r1.1, and related variants. The point is not that TiRex-2 makes those models obsolete. It is that a compact recurrent model can now compete in the part of the benchmark space that used to favor Transformer-style multivariate and covariate handling.
The paper's sensitivity tests are just as important as the leaderboard panels. TiRex-2 is evaluated under streaming updates, long-horizon chaotic systems, and shifted covariates. Those are closer to production failure modes than a single aggregate score. In particular, the covariate-shift experiment asks whether a model can keep using a lagged or misaligned covariate after the alignment changes. That is a realistic problem: weather, traffic, load, and operational metrics rarely line up perfectly with the target.
#Where TiRex-2 Fits
TiRex-2 is now one of the most interesting options when your forecasting problem has three properties at once: related target series, useful covariates, and a need for frequent refreshes. That combination appears in industrial telemetry, infrastructure monitoring, power systems, fleet operations, and high-frequency demand sensing.
It is a weaker fit when the problem is a simple univariate series, the context is short, and the forecast cadence is slow. In that case, the original TiRex, a small Chronos-Bolt checkpoint, or a tiny model such as Granite TTM may be easier to justify operationally. It is also not a reason to skip basic model selection. If your covariates are noisy, unavailable in the future, or only weakly related to the target, a simpler channel-independent baseline may still win. The multivariate lesson from our model routing work is consistent: route based on the input distribution, not the model's headline capability.
For teams already evaluating Chronos-2, TiRex-2 is the clean comparison to add when covariates and multivariate targets are central. Chronos-2 is the stronger known Transformer-family reference point for covariate-aware forecasting. TiRex-2 asks whether a recurrent, memory-centric architecture can deliver similar or better accuracy with a better streaming profile.
#The Broader Takeaway
TiRex-2 is important because it narrows a real architectural gap. First-generation recurrent TSFMs were efficient and stateful, but narrow. Multivariate Transformer TSFMs were flexible, but expensive to refresh continuously. TiRex-2 combines a recurrent xLSTM time path with an attention-based variate path and a target-causal mask, so it can condition on the covariates practitioners actually have without giving up the state-update story.
That is the technical point to watch. If TiRex-2's benchmark results transfer to production telemetry, the next generation of TSFM serving will not be a simple choice between "small recurrent" and "large attention." The more useful split will be by workload: univariate batch forecasts, covariate-aware multivariate forecasts, and continuously refreshed streaming forecasts. TiRex-2 gives the recurrent side of that map a much stronger claim than it had before.
Primary sources: TiRex-2 paper, original TiRex paper, xLSTM paper, NX-AI TiRex repository, FEV Bench leaderboard, GIFT-Eval leaderboard.