Chronos-2 Beats Alibaba's Production Demand Forecasting System
Alibaba researchers tested Chronos-2, Moirai, and TimesFM against a real production retail forecasting system. Chronos-2 was the model that crossed the line: better monthly demand forecasts, stronger daily dynamics, and a much smaller feature surface than the incumbent stack.
Most time series foundation model claims still live in benchmark space. A model wins on GIFT-Eval, improves a zero-shot leaderboard, or beats a familiar public dataset. Those results matter, but retail demand planning has a different standard: can the model beat a production system that already carries years of domain work, custom features, and operational tuning?
A new paper from researchers at Taobao and Tmall Group and Cornell, A Bitter Lesson for Retail Demand Forecasting: Evidence from Fine-Tuning Foundation Models, gives one of the clearest answers so far. The study evaluates Chronos-2, Salesforce's Moirai-1.1-R, and Google's TimesFM-2.5 on large-scale proprietary Alibaba retail data. The baseline is not seasonal naive, ARIMA, or a public competition model. It is Alibaba's deep-learning production forecaster: an N-BEATS/N-BEATSx-style system with trend, seasonality, and promotion-event components, already used inside the retail forecasting pipeline.
The result is not that every foundation model wins. That would be too easy, and it would be wrong. The result is sharper: Chronos-2 is the model that beats the production baseline on Alibaba's primary monthly demand-planning metric, while Moirai and TimesFM do not cross that bar in this setup.
#The test was an industrial retail forecast
The datasets are the kind retail papers usually cannot publish. The first is Tmall Supermarket, a domestic online retail business covering roughly 70,000 to 100,000 SKUs in groceries and everyday essentials. The second is Tmall Global Direct Import, a cross-border retail segment with more than 20,000 SKUs and international-brand demand patterns.
Both datasets are daily, with around two years of history. The task is to forecast future item-level sales over a 93-day horizon, which roughly maps to quarterly supply-chain planning. Major retail events such as Double 11 and 618 require procurement, replenishment, and logistics decisions weeks or months ahead.
The paper evaluates forecasts over Alibaba's 2026 fiscal year, from April 1, 2025 through March 31, 2026. The primary metric is 1-WMAPE, computed on monthly aggregated demand. Higher is better. The authors also report daily 1-WMAPE to measure whether models capture the within-month shape of demand: weekday effects, local fluctuations, and promotion spikes.
The baseline is deliberately strong. Alibaba's incumbent model is a production deep-learning system based on the N-BEATS and N-BEATSx family, trained from scratch on domain data and structured around interpretable trend, seasonality, and promotional-event layers.
That is the right baseline. A foundation model becomes operationally interesting when it beats a system a retailer already trusts.
#The result: Chronos-2 wins monthly, not just daily
The monthly result is the clean headline. Fine-tuned Chronos-2 improves Alibaba's primary metric by 3.5% on Tmall Supermarket and 5.4% on Tmall Global Direct Import. The daily gains are larger: 3.9% and 8.2% respectively under full fine-tuning.
| Model | Setting | Tmall Supermarket monthly | Tmall Supermarket daily | Tmall Global monthly | Tmall Global daily |
|---|---|---|---|---|---|
| Moirai 1.1-R | Zero-shot | -2.5% | -0.5% | -4.1% | +0.8% |
| Moirai 1.1-R | Fine-tuned | -1.2% | +0.6% | -2.1% | +2.5% |
| TimesFM 2.5 | Zero-shot | -10.3% | +0.1% | -10.3% | +1.8% |
| TimesFM 2.5 | Fine-tuned | -1.1% | +1.4% | -4.4% | +4.7% |
| Chronos-2 | Zero-shot | -0.2% | +0.1% | +1.5% | +6.0% |
| Chronos-2 | Fine-tuned LoRA | +3.4% | +3.7% | +5.3% | +8.0% |
| Chronos-2 | Fine-tuned full | +3.5% | +3.9% | +5.4% | +8.2% |
Moirai and TimesFM are not bad models. They are strong public TSFMs and appear frequently in benchmark comparisons. But in this retail setting, they do not beat Alibaba's monthly production metric after fine-tuning. They improve daily accuracy, which suggests they learn useful short-term dynamics, but monthly aggregation is where the incumbent system remains harder to displace.
Chronos-2 behaves differently. It is already close to the domestic production baseline in zero-shot mode and ahead on the international dataset before any task-specific training. Fine-tuning then turns a near-tie into a clear monthly gain.
That pattern lines up with the practical framework in Fine-Tuning vs. Zero-Shot. Zero-shot is the first test because it is cheap and often strong enough to establish whether the target distribution is in range. Fine-tuning becomes attractive when a few WMAPE points matter economically.
#The single covariate is the most important product detail
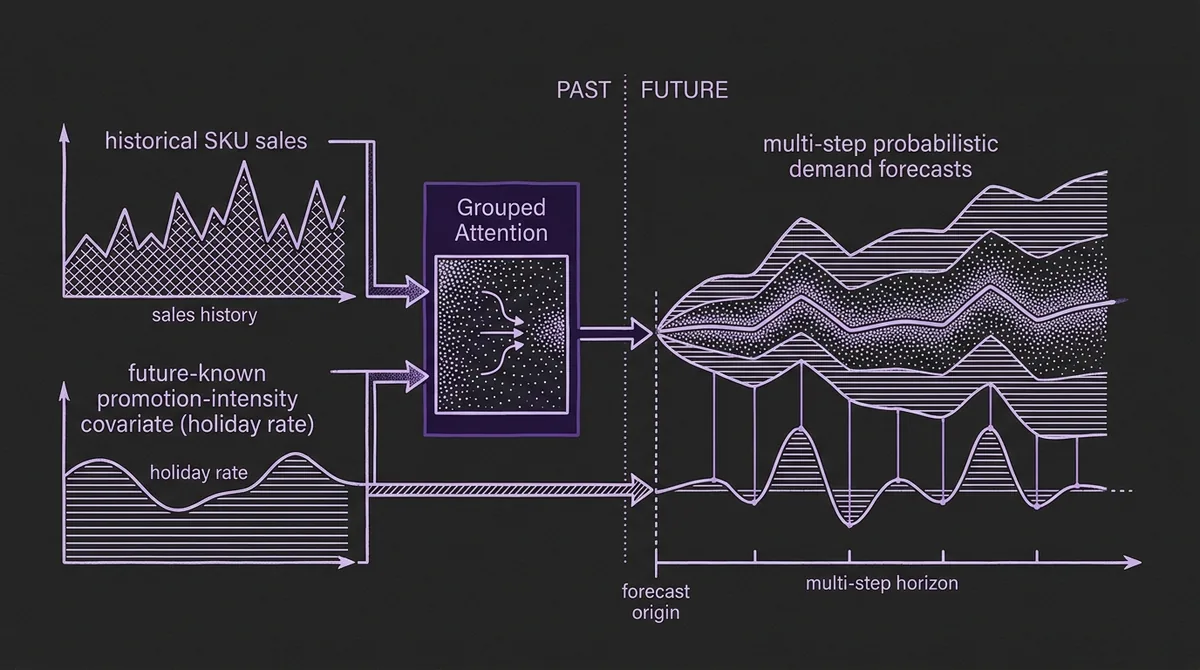
The most surprising part of the paper is not only that Chronos-2 wins. It is how little feature surface it needs to win.
Alibaba's production baseline uses a richer set of engineered signals. The Chronos-2 experiments use historical sales plus one future-known covariate: holiday rate, a numerical promotion-intensity feature. The authors construct it by fitting platform-level aggregate sales with Prophet, extracting the holiday component from a marketing calendar, and normalizing it onto an intensity scale where positive values represent promotional uplift and negative values represent suppressed demand.
That is very different from a holiday ID. A holiday ID says "this is Double 11" or "this is 618." A promotion-intensity covariate says "this future period is expected to be this strong." A categorical ID does not generalize well to a new campaign or a shifted promotion window. An intensity scale gives the model a common language for planned demand shocks.
The ablation makes that concrete:
| Dataset | Chronos-2 Base zero-shot covariate | Monthly improvement | Daily improvement |
|---|---|---|---|
| Tmall Supermarket | Holiday ID feature | -3.1% | -3.1% |
| Tmall Supermarket | Holiday rate | -0.2% | +0.1% |
| Tmall Global Direct Import | Holiday ID feature | -7.3% | +3.7% |
| Tmall Global Direct Import | Holiday rate | +1.5% | +6.0% |
This is the part retail teams should take most seriously. The old feature-engineering instinct is to add everything: promotion flags, campaign IDs, calendar effects, prices, discounts, category features, store clusters, stockout flags, vendor metadata, rolling lags, and interaction terms. Some may help. But the Alibaba result says the first high-value move may be narrower: identify the future-known covariate that actually drives demand and represent it in a way a foundation model can use.
That is exactly the direction modern covariate-aware TSFMs are moving. Chronos-2 supports multivariate and covariate-informed forecasting natively through group attention. The model card describes it as a 120M-parameter encoder-only model that can handle univariate, multivariate, and covariate-informed tasks in one architecture. Older Chronos and Chronos-Bolt checkpoints do not expose the same native future-covariate path.
For retail, that distinction is not academic. Promotions, holidays, lead times, and planned campaigns are known before the forecast horizon. A model that can condition directly on those future-known values has a structural advantage over one that has to bolt them on through a separate regressor.
#Why Chronos-2 was different
The paper points to three likely reasons Chronos-2 separated from Moirai and TimesFM in this experiment.
First, Chronos-2's group-attention mechanism lets targets and covariates sit in the same group so the model can learn their interactions directly. That is a natural fit for retail, where the same campaign affects many products, but not equally.
Second, Chronos-2 was designed around covariate-informed forecasting. Amazon's Chronos-2 technical report emphasizes univariate, multivariate, and covariate-informed tasks, with synthetic training data constructed to impose diverse multivariate structures on univariate series. The Amazon Science launch post makes the same product point: retail promotions and holiday schedules are exactly the sort of known future covariates the model is meant to consume.
Third, Chronos-2 may be better aligned with Alibaba's retail distribution. Amazon and Alibaba are different companies with different markets, but both are large-scale retail platforms. If Chronos-2 learned useful priors from retail-like pretraining tasks, that alignment would help. The full training data distributions are not public, so this remains an inference rather than a proven mechanism.
TimesFM 2.5's performance is also informative. The paper uses XReg to let TimesFM incorporate promotion information through an external ridge-regression adjustment. That helps daily accuracy, but it is not the same as end-to-end covariate integration inside the Transformer. For a 93-day retail horizon, a linear correction layer is a weaker interface than native group attention over targets and covariates.
This is why model selection cannot stop at "which TSFM is best on average?" A workload with future-known promotions needs a model whose input contract matches the business problem. Our 2026 TSFM toolkit makes the same point from the platform side: model routing should depend on latency, uncertainty needs, series count, and input structure, not just a global leaderboard rank.
#LoRA got nearly all of the gain
Another practical result is that LoRA fine-tuning almost matches full fine-tuning for Chronos-2.
On Tmall Supermarket, Chronos-2 LoRA improves monthly accuracy by 3.4% versus 3.5% for full fine-tuning. On Tmall Global Direct Import, LoRA reaches 5.3% versus 5.4% for full fine-tuning. Daily metrics show the same pattern: LoRA is within 0.2 percentage points of full fine-tuning in both datasets.
That is a useful production signal. Full fine-tuning updates the whole model, increases artifact management burden, and raises overfitting risk. LoRA adapts a small set of low-rank attention parameters while leaving the base model largely frozen. The paper uses rank 8 and alpha 16 adapters on attention projections, a configuration that matches the general guidance in our LoRA and PEFT guide.
The compute numbers are also modest. The paper reports that full Chronos-2 fine-tuning takes roughly 0.5 H20 GPU hours for five epochs on the Tmall Supermarket dataset, while LoRA takes about 0.3 GPU hours. Moirai and TimesFM take about 0.8 GPU hours each.
The lesson is not "always fine-tune." Chronos-2 zero-shot already looks useful, especially on Tmall Global. But when zero-shot is close and a few WMAPE points matter, LoRA may be the right middle path: enough adaptation to beat a specialized baseline, without rebuilding the whole forecasting stack.
#The daily-vs-monthly split tells you where TSFMs help first
The daily metrics are stronger than the monthly metrics across all three TSFM families. Even Moirai and TimesFM, which miss the monthly production baseline, improve daily forecasting after fine-tuning.
That is not a contradiction. Monthly aggregation smooths away many timing errors. A model can miss the exact day of a promotion spike but still get the total monthly volume roughly right. Alibaba's production system is already calibrated for aggregate planning, so there is less room to improve on monthly totals. Daily forecasting leaves more room because it tests whether the model captures the shape of demand inside the month.
For retail operations, that difference matters. Monthly demand supports procurement and budgeting. Daily demand supports replenishment timing, promotion execution, fulfillment staffing, and inventory positioning.
Evaluation should mirror the decision that consumes the forecast. A model picked for monthly S&OP planning might not be the same model picked for daily replenishment triggers. We have made a similar argument in The Challenges of Benchmarking TSFMs: aggregate scores hide the operational question.
#The bitter lesson, translated carefully
The paper borrows Richard Sutton's "bitter lesson" framing: over the long run, methods that scale with computation and data tend to beat systems built around handcrafted domain structure.
For retail forecasting, the bitter version is not that domain knowledge stops mattering. The Alibaba result actually depends on domain knowledge: someone still had to turn the promotion calendar into a useful holiday rate covariate. The bitter version is narrower and more plausible: the marginal gains may shift away from increasingly elaborate bespoke forecasting architectures and toward adapting pretrained models well.
That changes what a demand-forecasting team optimizes for.
The old stack asks: which model family should we train, which features should we engineer, which hyperparameters should we tune, and how do we maintain the pipeline indefinitely? The foundation-model stack asks: which pretrained model matches this workload, which future-known covariates matter, do we need zero-shot or LoRA, and how do we evaluate against the operational metric?
That is a different operating model. It does not eliminate forecasting expertise. It moves forecasting expertise closer to data representation, model selection, backtesting design, and downstream decision value.
This also clarifies the role of TSFM.ai. The valuable product surface is not only "call a forecast API." It is the ability to run the same retail series through hosted model families such as Chronos-2, Moirai, and TimesFM, test zero-shot before adaptation, add high-signal covariates, and promote a LoRA-adapted model only when it clears the incumbent baseline.
#Forecasting is only the first use
The paper ends with a more provocative direction: TSFMs as simulators for operations. If a model can generate realistic demand trajectories, it can be used to stress-test inventory policies, pricing rules, and promotion calendars.
This is where prediction intervals become more than a reporting feature. Operations decisions need distributions, not just point estimates. Stockouts, overstock, and service-level failures are tail events. A TSFM that can produce calibrated quantiles and plausible synthetic paths becomes a decision-system component, not just a forecaster.
There are hard caveats. Retail demand is censored by stockouts. Historical trajectories reflect historical policies. Better WMAPE does not automatically imply better inventory performance. A policy trained on synthetic demand can still optimize the wrong objective if the simulator misses substitution, cannibalization, or supply constraints.
But the direction is right. Once foundation models can beat a production retail forecaster on a real demand-planning metric, the next question is not only "can they forecast?" It is "can they improve the decisions that forecasts feed?"
#What retail teams should take from this
The Alibaba paper is not a blanket endorsement of every TSFM. It is a specific, useful result:
Chronos-2 deserves to be a default candidate for retail demand forecasting, especially when the workload includes related SKUs, future-known promotions, and a need for probabilistic multi-step forecasts.
Zero-shot is a serious baseline. On the international dataset, zero-shot Chronos-2 already beats the production monthly metric. On the domestic dataset, it nearly matches it.
Fine-tuning matters when the incumbent is strong. LoRA and full fine-tuning turn Chronos-2 from "near production" into "better than production" in this study. The gain is in the 3-5% range on the primary metric, exactly the range retail teams care about when forecasts feed procurement and inventory.
Covariate representation is the new feature engineering. The winning feature was not a giant feature set. It was a single promotion-intensity covariate represented on a scale the model could generalize across campaigns.
Model routing still matters. Moirai and TimesFM did not win monthly here. They may win elsewhere. The conclusion is not "always use Chronos-2." The conclusion is "evaluate the model whose architecture matches the operating problem, then measure it against the incumbent metric."
That is the real shift. Retail forecasting used to start with building a forecasting system. Increasingly, it starts with testing whether a pretrained temporal model already knows enough to challenge one.