Kronos: A Domain-Specific Foundation Model for the Language of Financial Markets
Kronos is a decoder-only foundation model pre-trained on 12 billion K-line records from 45 global exchanges, with a specialized tokenizer that quantizes OHLCV bars into hierarchical coarse/fine subtokens. Accepted at AAAI 2026, the model reports 93% higher RankIC than the leading general-purpose TSFM on financial benchmarks and is open-sourced under MIT.
The general-purpose time series foundation model story has been a story about universal architectures: tokenize any series, pretrain on a broad corpus, ship one zero-shot model that does the rest. The 2026 picture is more layered. Toto is a TSFM purpose-built for observability metrics. The Cisco Time Series Model targets machine telemetry. And Kronos — accepted at AAAI 2026 — is the financial-markets entry in this new wave of domain-specialist TSFMs.
Kronos pretrains on over 12 billion K-line records from 45 global exchanges and uses a specialized tokenizer that quantizes OHLCV candlestick bars into hierarchical discrete tokens. The release ships four model sizes from 4.1M to 499M parameters, is MIT-licensed, and crossed 25K stars on GitHub in the first few months after the paper went public. On TSFM.ai we host the three open variants directly: Kronos-mini at 4.1M, Kronos-small at 24.7M, and Kronos-base at 102.3M.
#Why Finance Needed Its Own TSFM
General-purpose TSFMs — Chronos, Moirai, TimesFM, Time-MoE — pretrain across many domains and frequencies, and they generalize impressively. Financial K-lines push that generalization past where it works well. The statistical signature of candlestick data — heavy tails, volatility clustering, leverage effects, regime switches, and the very specific cross-asset correlation structure of equity, FX, and commodity markets, all of which we wrote about in Financial Time Series: Volatility Modeling and Risk Forecasting with TSFMs — is structurally different from what a model trained on a LOTSA blend of energy, retail, weather, and web traffic gets to see at pretraining time.
There is also a structural mismatch at the input level. An OHLCV bar is not one time series. It is four price readings per timestep tied by the inequality low ≤ open, close ≤ high, plus a volume channel that carries the trade-activity signal. General-purpose TSFMs either flatten this into a single channel (and lose information) or treat it as a generic multivariate input (and lose the OHLC inequality structure). Kronos's first design choice is to model OHLCV natively, in a way that respects what the bars actually are.
#The K-Line Tokenizer: Hierarchical, Binary-Spherical
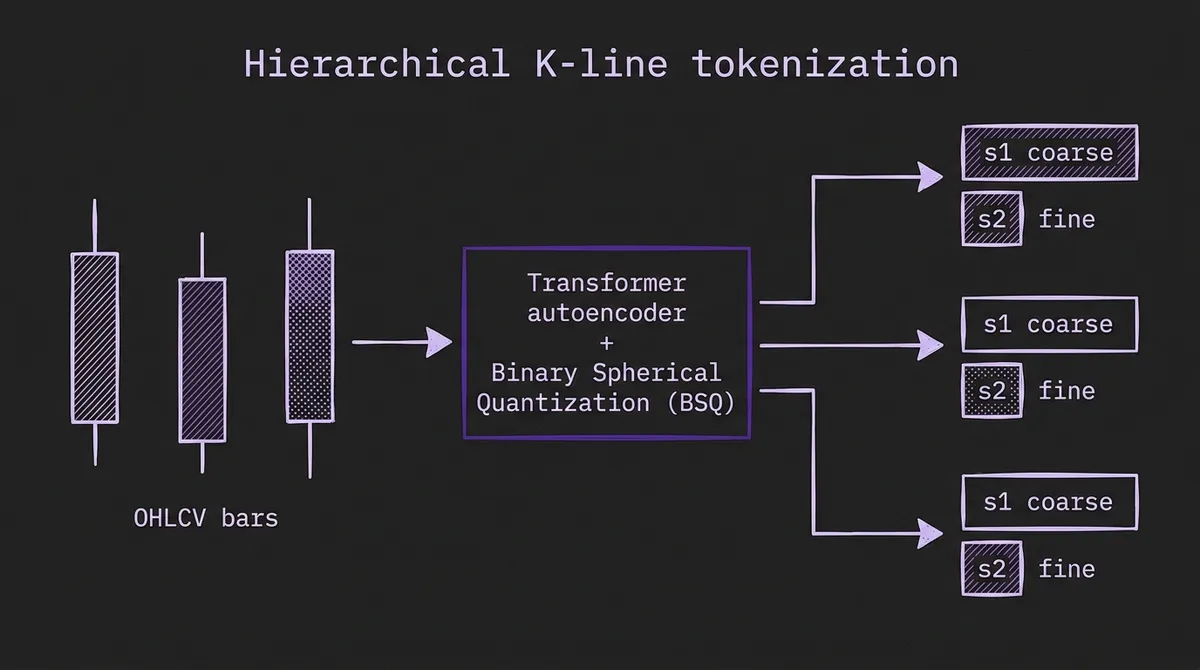
The Kronos tokenizer is the load-bearing technical idea. The authors frame K-line forecasting as language modeling over a discrete vocabulary — same spirit as Chronos's value tokenization, but specialized to OHLCV — and use a Transformer-based autoencoder with a Binary Spherical Quantization (BSQ) layer and a dual reconstruction objective.
Each K-line ends up as two subtokens. The coarse subtoken (s1) captures broad market state: direction, regime, gross magnitude of the bar. The fine subtoken (s2) captures within-bar detail: wick structure, intra-bar volatility, volume profile. A hierarchical reconstruction loss explicitly forces s1 and s2 to model different levels of information rather than collapsing onto the same one. The decoder transformer is then pretrained to predict next-step subtokens autoregressively, which is the trick that gets the model both price-series forecasting (a sequence of next bars) and volatility forecasting (variance of fine-grained subtokens conditional on coarse context) out of a single objective.
Two tokenizer variants ship at launch. Kronos-Tokenizer-base runs 512 bars of context, which is the default for Kronos-small and Kronos-base. Kronos-Tokenizer-2k runs 2048 bars, paired with Kronos-mini for the longest-context use case. The 2K variant is more important than it sounds for intraday work — many strategies look at one to two weeks of 5-minute bars (roughly 1500–3000 bars), and most TSFM context budgets cut off well below that.
This is a different bet than Chronos's scaling-and-quantization-bins approach to value tokenization, and a different bet than Sundial's diffusion-over-continuous-values approach. Hierarchical discrete tokens give up some continuous-value fidelity to get autoregressive language-style generation over long horizons in return. For OHLCV, that trade lines up — bars are already a discrete-ish object, and the generation use cases (synthetic backtest data, Monte Carlo paths) benefit directly from autoregressive sampling.
#What 12 Billion K-Lines Buys
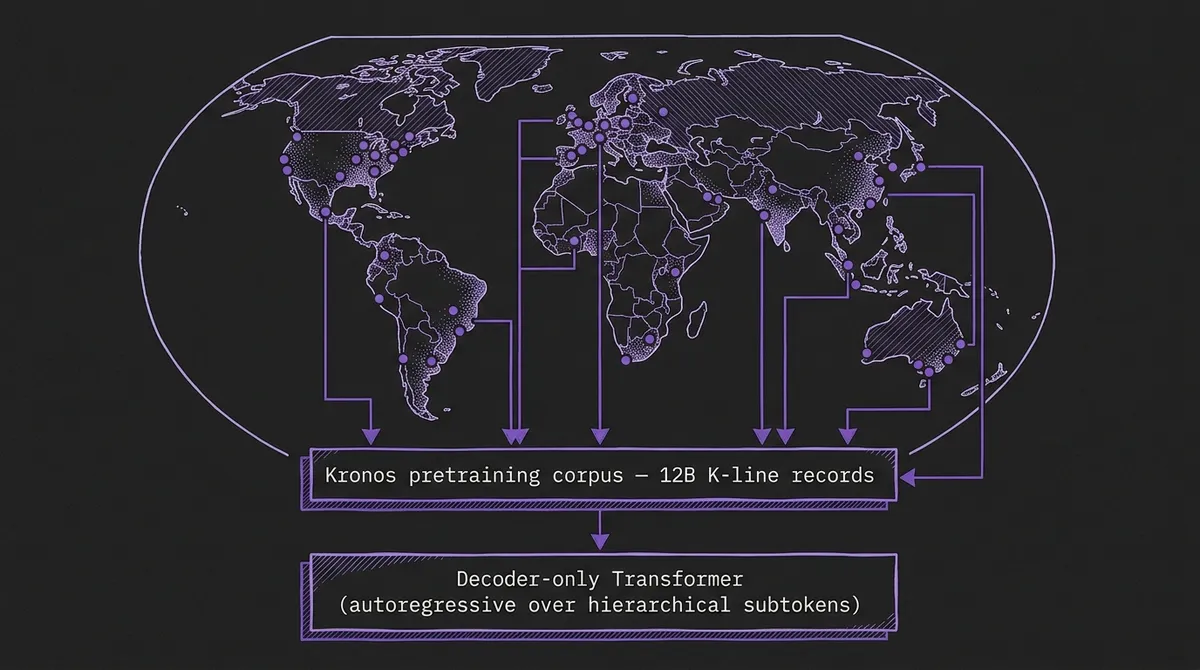
The pretraining data is the other half of the story. Kronos's 12B-record corpus spans equities, futures, FX, and crypto across 45 global exchanges and multiple frequencies. That scale is the real reason zero-shot performance on financial benchmarks moves: the model has seen the distribution it is being asked to forecast on.
The contrast with general-purpose TSFMs is sharp. For Chronos or TimesFM, zero-shot on financial benchmarks is genuinely out-of-domain — those models were never told markets exist. Kronos has effectively seen the structural shape of every major liquid market. The analogous situation is Toto on observability, or Time-MoE on agricultural commodity prices where its commodity-heavy pretraining mix turned out to dominate the benchmark. Domain specialization pays off cleanly when the target distribution is structurally different from the pretraining mix.
#The Family and How to Run It
Kronos releases as a small family rather than a single hero checkpoint:
| Variant | Tokenizer | Context | Parameters | Where to run |
|---|---|---|---|---|
| Kronos-mini | Kronos-Tokenizer-2k | 2048 | 4.1M | Hosted on TSFM.ai; small enough for CPU |
| Kronos-small | Kronos-Tokenizer-base | 512 | 24.7M | Hosted on TSFM.ai; per-symbol production default |
| Kronos-base | Kronos-Tokenizer-base | 512 | 102.3M | Hosted on TSFM.ai; largest public checkpoint |
| Kronos-large | Kronos-Tokenizer-base | 512 | 499.2M | Paper-only; weights not released |
All three open variants are served on TSFM.ai at the same pricing as our other hosted models, and the upstream weights live under the NeoQuasar/ namespace on Hugging Face for teams that prefer to self-host. The quickstart is small enough to drop into a notebook:
from model import Kronos, KronosTokenizer, KronosPredictor
tokenizer = KronosTokenizer.from_pretrained("NeoQuasar/Kronos-Tokenizer-base")
model = Kronos.from_pretrained("NeoQuasar/Kronos-small")
predictor = KronosPredictor(model, tokenizer, max_context=512)
pred_df = predictor.predict(
df=x_df, x_timestamp=x_timestamp, y_timestamp=y_timestamp, pred_len=120
)
A 24.7M-parameter model that can predict 120 future bars from 512 historical bars on commodity hardware fits comfortably in a per-symbol forecasting pipeline without provisioning frontier GPUs. Kronos-mini at 4.1M is small enough that CPU inference becomes a real option when latency is the binding constraint.
#What the Paper Reports
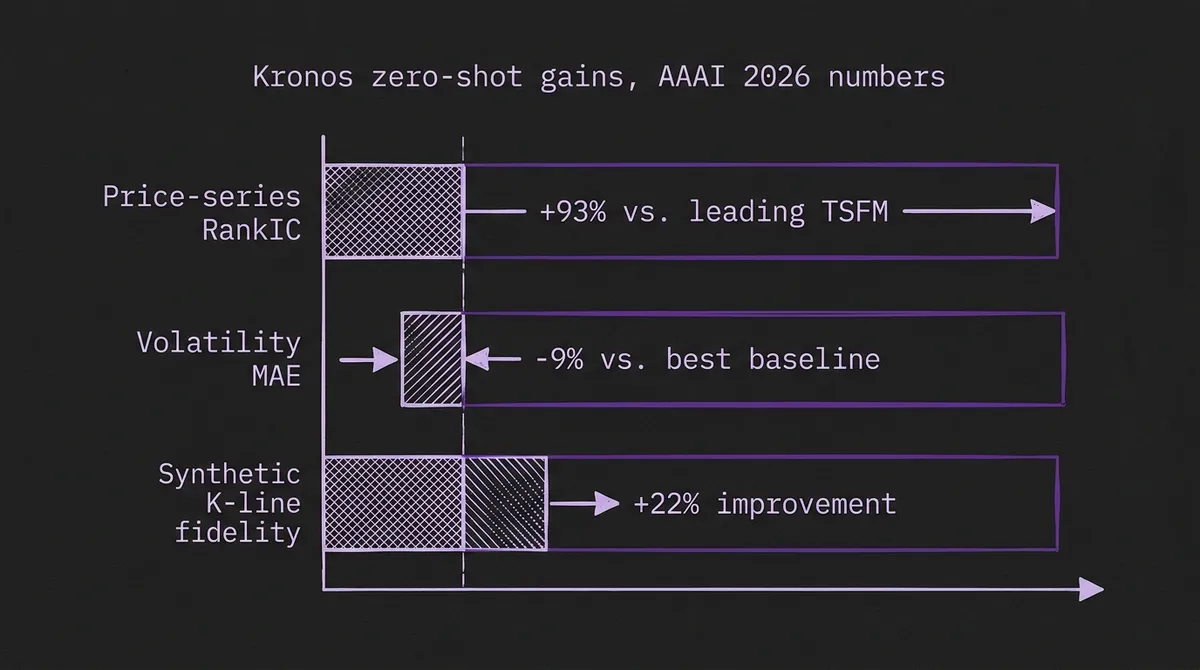
Kronos targets three financial tasks at once: price-series forecasting, volatility forecasting, and synthetic K-line generation. The headline zero-shot numbers in the AAAI 2026 result are a 93% lift in price-series RankIC over the leading general-purpose TSFM on the same benchmark suite (87% over the strongest non-pretrained baseline), a 9% reduction in volatility-forecasting MAE versus the strongest baseline, and a 22% improvement in generative fidelity for synthetic K-line sequences — directly relevant for backtest augmentation and Monte Carlo risk scenarios.
The 93% RankIC lift is the figure worth dwelling on. RankIC — rank information coefficient — is the metric quantitative researchers actually use to judge whether a model's forecasts carry signal, because it measures the cross-sectional rank correlation between predicted and realized returns rather than an absolute error number. A near-doubling of RankIC versus the leading general-purpose TSFM is large, and it is the cleanest indicator that domain specialization is doing real work here rather than reshuffling cosmetic error metrics.
The usual benchmarking caveats apply. RankIC is dataset-dependent, the comparison set is the one the authors picked, and zero-shot rankings shift as new models ship. Independent replication across additional financial benchmarks — and ideally a finance-specific suite analogous to what GIFT-Eval is for general-purpose forecasting — is what will turn the AAAI result into a durable benchmark fact rather than a single-paper claim.
#Where Kronos Fits in a Forecasting Stack
The way to think about Kronos in production is as a specialist that slots in alongside the rest of the stack, not as a replacement for it. The model's home turf is zero-shot OHLCV forecasting and synthetic K-line generation at horizons of minutes to days — the regimes where the domain pretraining is doing the most work. Downstream P&L and risk consumers usually want calibrated quantiles rather than raw token distributions, which is exactly the job conformal wrappers are for: turn token-level predictions into honest p10/p50/p90 bands without retraining.
If finance is one of several domains a single platform forecasts across, Kronos belongs behind a model router, playing the same role Toto plays for observability and TTM plays for lightweight univariate workloads. And classical methods still have territory. GARCH and its variants remain highly effective volatility models for single-asset, low-data regimes; statistical factor models still beat foundation models on cross-sectional factor exposures. The 9%-lower-MAE result is real but is not an argument for ripping out every existing volatility model on day one.
The other consideration is leakage. Pretraining on 12B K-lines from 45 exchanges means Kronos has very likely seen many of the historical periods a quant team would naturally want to evaluate on. Out-of-distribution validation — recent unseen windows, instruments outside the training mix, regime-shift periods, anything that postdates the pretraining cutoff — is the only honest way to estimate how the model behaves on live data. This is the same evaluation hygiene the field has been converging on for general-purpose TSFMs, just applied at a domain where the financial cost of getting it wrong is more visible.
#What the AAAI 2026 Acceptance Means for the Field
The bigger signal in the Kronos release is that domain-specific TSFMs are now an established category, not a one-off curiosity. Toto for observability, Kronos for finance, and the Cisco Time Series Model for machine data are three pretrained checkpoints whose corpora are deliberately narrow, and they all win on their target distribution. The natural next entries are healthcare, manufacturing predictive maintenance, and climate and weather — and the Kronos pattern suggests similar gains should be available there.
Tokenizer design is now a first-class research direction. The hierarchical BSQ tokenizer here, Kairos's mixture-of-size tokenization, and the patching schemes used by Sundial and TiRex are all serious arguments about how to discretize a continuous signal. That used to be a footnote in TSFM papers; it is increasingly the difference between models.
The deployment story sits with the open release. A 4.1M / 24.7M / 102.3M weights matrix under MIT, with HF-published weights, a simple KronosPredictor API, and hosted inference at Kronos-mini, Kronos-small, and Kronos-base, is what makes a model actually used. The 499M closed variant is interesting for benchmarks; the open variants are the ones that will land in production.
For teams working on financial volatility and risk, supply chain cost forecasting with commodity exposure, or agricultural price workflows where futures bars matter, Kronos is the new strong default for zero-shot OHLCV. The question is no longer whether a TSFM can compete with traditional financial models on candlestick data — Kronos's AAAI 2026 result settles that. The question is which specialist sits in which slot of a heterogeneous forecasting stack, and how to evaluate that choice cleanly on a particular team's data.