Cisco Time Series Model: Multiresolution Input as an Architecture Primitive
Cisco's CTSM 1.0 takes a different approach to long context: instead of extending the sequence length, it feeds the model two views of the same history at different resolutions — coarse hourly context for global patterns, fine minute-level context for local detail. On observability data the approach leads MASE by 16%, and on GIFT-Eval it lands third without test-set leakage.
Every time series foundation model faces the same context-length dilemma. A 1-minute-resolution metric from an observability platform generates 10,080 data points per week. A model with a 512-step context window sees only the last 8.5 hours — enough to capture intraday fluctuations, but not nearly enough to see the weekly periodicity or multi-week growth trends that drive capacity planning decisions. The standard response has been to extend the context window: TimesFM 2.5 now supports 16,384 steps, and other models have pushed into the thousands. More history, better forecasts — in theory.
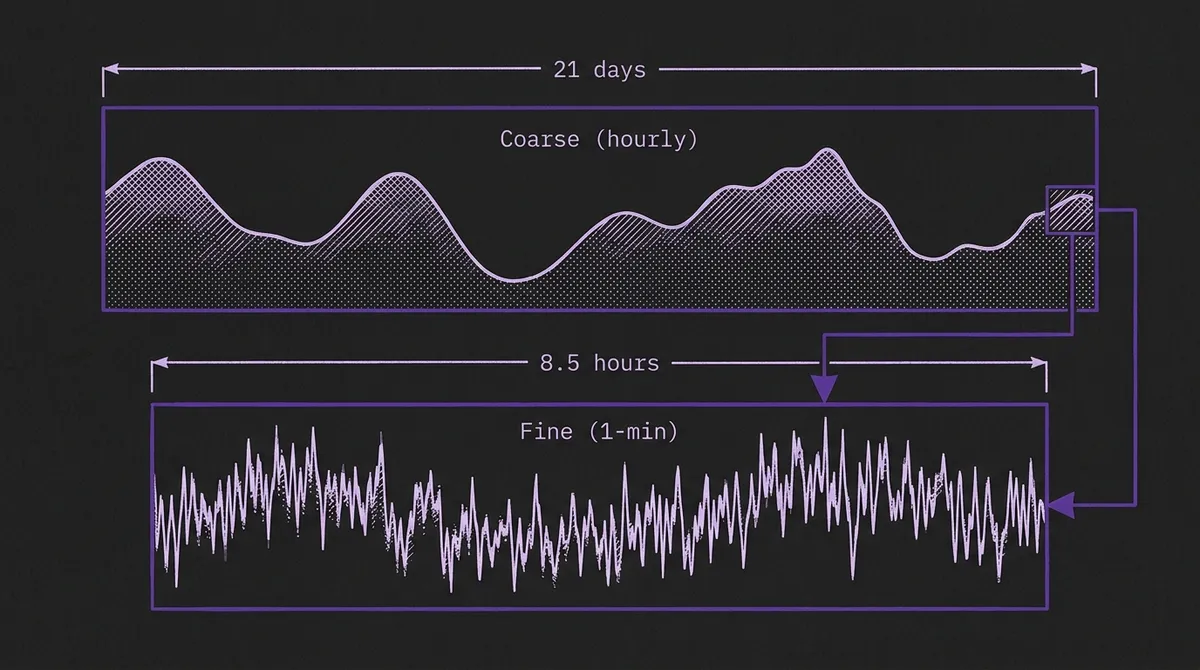
The Cisco Time Series Model (CTSM) takes a different approach. Instead of stretching a single-resolution context to cover more time, it feeds the model two views of the same history at two different resolutions simultaneously: a coarse context (e.g., 512 hourly data points covering ~21 days) and a fine context (e.g., 512 minute-level data points covering ~8.5 hours). The coarse view captures weekly patterns and growth trends. The fine view captures the immediate local dynamics needed for an accurate near-term forecast. With a combined 1,024 input patches, the model sees the same temporal range that a single-resolution model would need 30,720 steps to cover.
The 1.0 release (March 2026) ships at 250M parameters, trained from scratch on over 300 billion data points. On Cisco's own observability benchmark it leads the field by 16% in MASE at 1-minute resolution. On GIFT-Eval, the standard general-purpose benchmark, it ranks third by MASE among models without test-set leakage — behind Chronos-2 and TimesFM-2.5, but ahead of Toto and Chronos-Bolt.
#Why Multiresolution, Not Longer Context
The practical motivation comes directly from how observability platforms store data. In production systems like Splunk Observability Cloud, fine-resolution data (1-minute granularity) is retained for a limited window — typically days to weeks — before being rolled up into coarser aggregates (hourly, daily) for long-term storage. This is not a limitation unique to Splunk; virtually every metrics platform applies the same retention tiering to manage storage costs.
This means that for a time series with months of history, a single-resolution model faces an impossible choice: use the recent fine-resolution data and lose the long-term patterns, or use the older coarse-resolution data and lose the local detail. Neither option is good. A multiresolution model eliminates this choice by consuming both views natively.
The architecture also provides a computational advantage. Covering 21 days at 1-minute resolution requires 30,720 data points — a context length no current TSFM supports in practice, and one that would impose significant memory and latency costs even if it did. CTSM covers the same temporal span with just 1,024 input patches (512 coarse + 512 fine), a 30× compression that keeps inference latency practical for production workloads.

This is a fundamentally different approach from prior multiscale work in the TSFM literature. Models like Pyraformer, Scaleformer, and Pathformer process the same input at multiple scales internally — they take a single-resolution sequence and build internal multi-scale representations. CTSM is distinct because it accepts pre-computed multi-resolution input from the data layer. The coarser context is not derived from the finer context through downsampling at inference time; it is a separate input stream that can come from a different storage tier entirely.
#Architecture: Resolution Embeddings and a Special Token
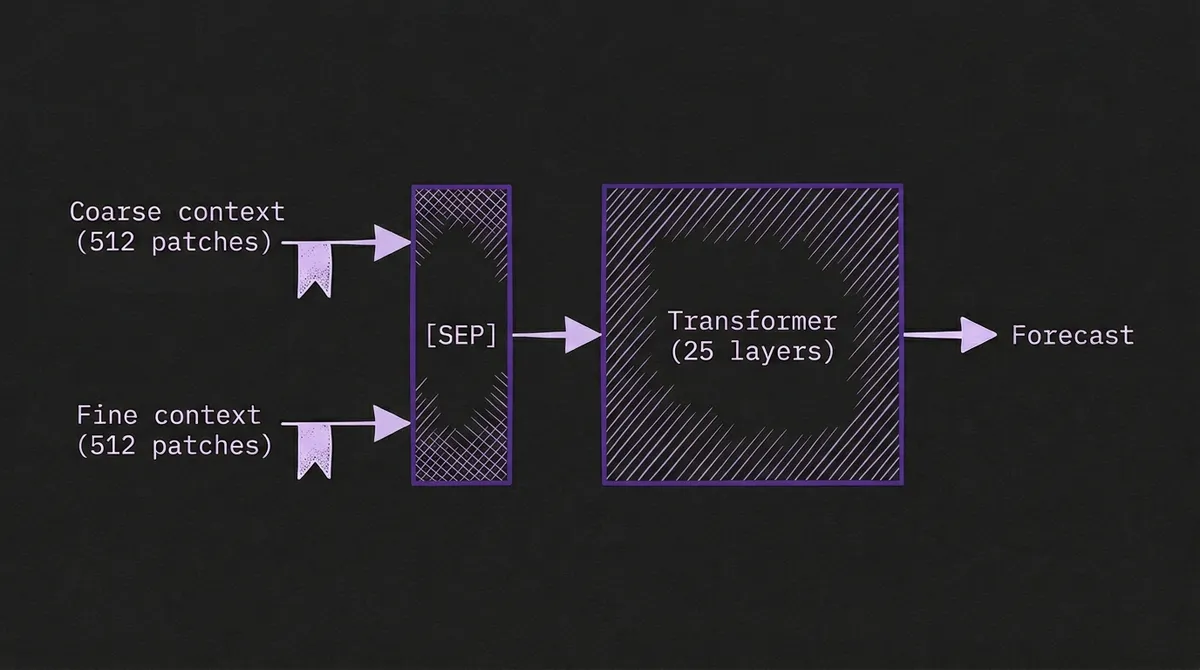
CTSM is built on the TimesFM decoder-only transformer architecture, with three key additions that enable multiresolution input.
Resolution embeddings. Each input patch receives a learned embedding that indicates whether it belongs to the coarse or fine context. This is conceptually similar to the frequency embeddings in TimesFM, but the purpose is different: rather than encoding the sampling frequency metadata, the resolution embedding teaches the model that hourly and minute-level patches represent fundamentally different views of the data and should be interpreted differently.
Special token. A learned special token is inserted between the coarse and fine context sequences, analogous to [SEP] tokens in language models. This provides an explicit boundary signal that separates the two resolution streams before they enter the shared transformer stack.
Independent normalization. The coarse and fine contexts are standard-normalized independently. The mean and standard deviation of the fine context are used to normalize the output horizon. This matters because the statistical properties of the two resolution streams can differ substantially — an hourly aggregation smooths out the high-frequency noise present in minute-level data, so forcing them to share normalization parameters would distort one or both views.
The 1.0 release adds several improvements over the November 2025 preview:
- Trained from scratch rather than continued pretraining from TimesFM weights, eliminating any inherited biases from a single-resolution pretraining regime.
- Bidirectional coarse attention. The coarse context uses bidirectional attention (the model can attend to both past and future within the coarse context), while the fine context retains standard causal attention. The rationale is that the coarse context represents a fully observed historical summary — there is no information-leakage risk from bidirectional attention over already-completed hourly aggregations.
- Rotary positional embeddings (RoPE), replacing the original position-free design with explicit relative position encoding.
- Expanded quantile outputs — 15 quantile levels from 0.01 to 0.99, up from 9 in the preview.
- Parameter reduction from ~500M to ~250M (25 transformer layers instead of 50), achieved without accuracy loss on GIFT-Eval.
#Training: 300 Billion Points, Observability-Heavy
The training corpus reflects the domain thesis. The 1.0 release training mix is:
| Source | Share |
|---|---|
| Splunk Observability Cloud (1h, 1min) | 46.2% |
| Splunk Observability Cloud (5h, 5min) | 21.8% |
| GIFT-Eval Pretrain | 19.5% |
| Chronos datasets | 3.0% |
| Synthetic (KernelSynth-based) | 9.5% |
Over two-thirds of the training data is proprietary observability telemetry from Splunk's own platform — real CPU counters, request latencies, memory gauges, and error rates from production infrastructure. This is a heavier domain weighting than Toto, Datadog's observability TSFM, which also trained on production telemetry but balanced against a broader mix of public sources.
The data pipeline includes several operations worth noting for practitioners building domain-specific TSFMs:
Statistical deduplication. Observability datasets contain vast numbers of near-identical series (hundreds of hosts running the same workload produce nearly indistinguishable CPU traces). The CTSM team uses locality-sensitive hashing (SimHash) to cluster similar series, then applies within-cluster diversity sampling to prevent the model from memorizing a small number of dominant patterns. This is the time-series analogue of web-text deduplication in LLM pretraining.
Window-level filtering. Individual training windows are filtered based on flat-spot length (removing event-like data masquerading as metrics), unique value count, context-horizon deviation ratio (removing unpredictable regime changes), and spectral entropy (downsampling high-entropy noise windows). These heuristics operationalize a practical principle: don't train on data that no model could reasonably learn from.
Short-context training. One-third of training examples use a fine context length uniformly sampled from [10, 511] rather than always using the full 512 steps. This prevents the model from relying on always having a full fine-resolution context, improving robustness when deployed on series with limited recent history.
#Benchmark Results: Domain Leader, General-Purpose Competitor
#Observability data
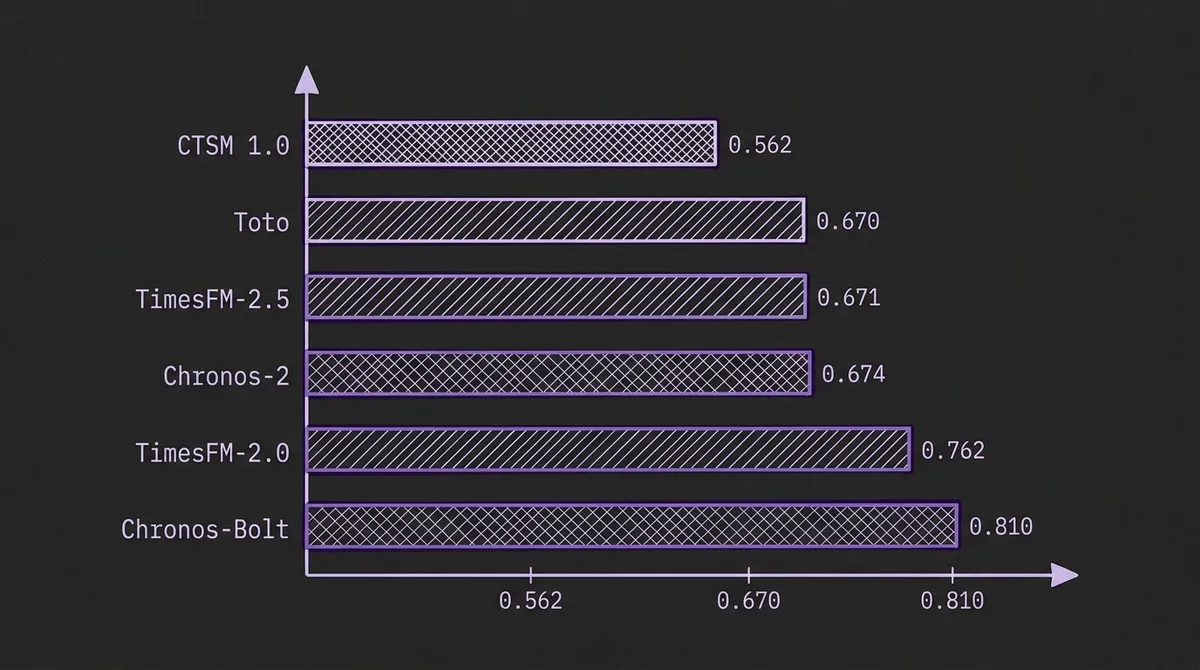
On Cisco's own out-of-domain, in-the-future observability benchmark, CTSM 1.0 leads every model by a wide margin:
1-minute resolution (MASE, lower is better):
| Model | MASE |
|---|---|
| CTSM 1.0 | 0.562 |
| Toto Open Base 1.0 | 0.670 |
| TimesFM-2.5 | 0.671 |
| Chronos-2 | 0.674 |
| TimesFM-2.0 | 0.762 |
| Chronos-Bolt Base | 0.810 |
The 16% MASE improvement over the second-best model (Toto) is substantial. At 5-minute resolution, the gap narrows slightly (0.543 vs 0.620 for the second-best, Chronos-2), but CTSM still leads by 12%.
These are self-reported results on Cisco's own evaluation data, which warrants the usual caveats about vendor benchmarks. However, the evaluation methodology is well-documented: the test series are both out-of-domain (not seen during training) and in-the-future (all test timestamps postdate the latest training timestamp), which is a stronger evaluation protocol than many self-reported comparisons offer.
#GIFT-Eval (general-purpose)
On GIFT-Eval with horizon capped at ≤128 and full context, CTSM 1.0 achieves a MASE of 0.715 — behind Chronos-2 (0.692) and TimesFM-2.5 (0.707), but ahead of TimesFM-2.0 (0.730), Toto (0.738), and Chronos-Bolt (0.749). Crucially, CTSM has no test-set leakage: the GIFT-Eval test set was explicitly excluded from training data. TimesFM-2.0 and Chronos-Bolt both have known leakage, and their reported MASE numbers should be read with that in mind.
The general-purpose results carry an important interpretive note. GIFT-Eval is a single-resolution benchmark — it provides each model with a single time series at one resolution. CTSM constructs its multiresolution input by aggregating the provided series into a coarse context via non-overlapping averaging, then using the tail as the fine context. This is the correct way to evaluate multiresolution against single-resolution models, but it means CTSM is constructing its advantage (separate long-range and short-range views) from the same underlying data, rather than from truly separate storage tiers as it would in a production observability deployment.
#What Practitioners Should Take Away
Multiresolution input is an architecture-level idea, not just a Cisco feature. The technical report explicitly notes that the multiresolution pattern — special token, resolution embeddings, independent normalization — "can be applied to many TSFMs." Any decoder-only or encoder-decoder model that accepts patched input could, in principle, be extended to accept dual-resolution streams. If you are building or fine-tuning a domain-specific TSFM for data that naturally exists at multiple retention tiers (observability, IoT sensor data with edge aggregation, financial tick-to-bar data), this is a pattern worth considering.
Domain specialization continues to pay off for observability. CTSM joins Toto in demonstrating that training heavily on observability data produces substantially better results on observability workloads than general-purpose models achieve. Both CTSM and Toto outperform broader models on their respective observability benchmarks. The practical question for observability teams building model routing strategies is which domain-specialized model to use — and the answer may depend on whether multiresolution input is available in their data pipeline.
The parameter efficiency story is notable. CTSM 1.0 achieves its observability results at 250M parameters — larger than Granite TTM but smaller than Chronos-2, TimesFM-2.0, and many other competitors. The reduction from 500M (preview) to 250M (1.0) with no accuracy loss on GIFT-Eval and improved observability results suggests that the multiresolution architecture is extracting more signal per parameter than a larger single-resolution model would.
Quantile outputs are not yet calibrated. The model page notes explicitly that the 15 quantile outputs "have not been calibrated or rigorously evaluated." For point forecasting, this is irrelevant. For teams that need calibrated prediction intervals, this is a meaningful limitation. Conformal prediction wrappers could provide calibrated intervals post-hoc, but native calibration would be a welcome addition.
Univariate only. CTSM is a univariate model — it processes one metric at a time. For observability workloads where cross-metric correlations matter (CPU and memory and error rate moving together), you lose the multivariate signal that models like Toto capture through factorized channel attention. The choice between CTSM's multiresolution temporal depth and Toto's multivariate breadth is a real deployment tradeoff.
#Open Artifacts
CTSM 1.0 is released under Apache 2.0 with full open access:
- Try it on TSFM.ai: cisco-ai/cisco-time-series-model-1.0 — hosted inference, no setup required
- Model weights: cisco-ai/cisco-time-series-model-1.0 on Hugging Face
- Inference code: splunk/cisco-time-series-model on GitHub
- PyPI package:
cisco-tsm— install withpip install cisco-tsm - Technical report: arXiv:2511.19841
The model accepts any single-resolution time series up to 30,720 points and automatically constructs the multiresolution context internally, so no manual resolution splitting is required at inference time.
#Where CTSM Fits in the Landscape
The observability TSFM space is becoming a two-vendor race with meaningfully different architectures. Toto bets on multivariate factorized attention trained at massive scale on Datadog's observability corpus. CTSM bets on multiresolution temporal input trained on Splunk's observability corpus. Both substantially outperform general-purpose models on their home turf.
For practitioners, the multiresolution architecture is the more transferable idea. It addresses a real data-layer constraint — retention tiering — that exists in nearly every operational metrics platform. As context length continues to be a limiting factor in TSFM deployment, feeding models pre-aggregated coarse history alongside recent fine-grained data is a pragmatic way to extend effective temporal coverage without the compute cost of processing 30,000-step sequences.
Whether other model families adopt multiresolution input natively, or whether it remains a Cisco-specific innovation, will depend on whether the community treats it as a general architectural primitive or a domain-specific optimization. The evidence from the 1.0 release suggests it deserves consideration as the former.