Migas 1.5 and the Text-Conditioned Forecasting Stack
Synthefy's Migas 1.5 is a useful signal for the emerging text-plus-time-series model category: Chronos-2 handles the numerical forecast, language summaries carry context, and a small fusion layer decides how much the story should move the curve.
Synthefy's Migas 1.5 is a good moment to update the mental map for text-plus-time-series models. It is not just another zero-shot forecaster. It is a text-conditioned forecasting system: a numerical backbone produces a forecast, language context is summarized into structured signals, and a fusion layer decides how much that context should alter the forecast trajectory.
That makes Migas interesting. It also makes the category boundary messy.
Synthefy frames Migas 1.5 as a model that fuses text and time series. We would avoid turning that into a broad "first" claim, because several adjacent lines of work were already exploring language and time series before Migas: PromptCast turned forecasting into a prompt-based language task, Time-LLM reprogrammed frozen LLMs for forecasting, UniTime used language instructions for cross-domain forecasting, TimeCMA aligned LLM prompt embeddings with time-series embeddings, TaTS treated paired texts as auxiliary variables for forecasting and imputation, OpenTSLM integrated time series into LLMs for medical reasoning, and Archetype AI's Newton TimeFusion brought sensor-language fusion into a commercial physical-AI product. The more useful claim is narrower: Migas is one of the clearest open-weight examples of a production-shaped text-conditioned forecasting stack.
That distinction matters. "Fusing text and time series" can mean many different things. It can mean using text as a prompt, converting numbers into words, attaching domain instructions, adding cross-attention between modalities, answering questions about telemetry, or using a language model to summarize event context before a numerical forecaster runs. Migas sits in the last camp.
#What Migas 1.5 actually adds
The Migas model card describes Migas 1.5 as a multimodal late-fusion model built on top of a frozen Chronos-2 forecaster. Chronos-2 handles the numerical history. An LLM turns per-step text annotations into two structured sections: a factual history and forward-looking predictive signals. A text embedder encodes those summaries, and a gated attention module fuses them with the Chronos-2 forecast representation. The final head blends the base numerical forecast with the fused forecast.
This is not a from-scratch multimodal transformer trained to model every token and every value jointly. It is a modular correction system over a strong univariate forecaster. That is a practical design choice. A pure multimodal pretraining run would need aligned text-series data at scale, which remains scarce. Migas instead treats text as an exogenous signal that can correct a numerical baseline when the history alone is missing causal context.
The GitHub repository makes that workflow concrete. The quick start loads Synthefy/migas-1.5, passes a data frame with dates and values, and supplies a pre-written summary. No LLM server is needed for that path. If the user has per-step text instead of a precomputed summary, Migas can call an LLM to generate the summary first. The input convention is straightforward: t, y_t, and optional text.
That small API surface is the most important product signal in the release. Migas is not asking users to fine-tune a model, build a feature store, or encode every future event as a numeric covariate. It asks for the same kind of evidence an analyst already has: news, notes, explanations, earnings commentary, weather alerts, policy changes, or domain summaries.
#Why the "first" question is hard
The broad priority question probably has a simple answer: no, Migas is not the first model to combine text and time series. The narrower question is more interesting. Text-plus-time-series work has been splitting into multiple subfields, and Migas belongs to a specific one:
| System | What text does | Why it overlaps |
|---|---|---|
| PromptCast | Converts forecasting into a sentence-to-sentence prompting task | It made language the interface for forecasting before the current TSFM wave. |
| Time-LLM | Uses prompts and reprogrammed time-series patches with a frozen LLM | It aligns language-model representations with numerical sequences. |
| UniTime | Uses domain instructions inside a unified cross-domain forecasting model | It treats language instructions as a conditioning signal for forecast behavior. |
| TimeCMA | Aligns LLM prompt embeddings with disentangled time-series embeddings | It is explicitly cross-modal forecasting work before Migas. |
| TaTS | Treats paired texts as auxiliary variables for forecasting and imputation | It directly addresses time-series-paired text as a multimodal predictive input. |
| OpenTSLM | Adds time series as a native modality to LLMs for medical reasoning | Its released Gemma-3 checkpoints use a Flamingo-style architecture to splice time-series inputs into a pretrained LLM. |
| Aurora | Combines time-series modeling with text-conditioned task descriptions | It is closer to native multimodal TSFM research than late-fusion correction. |
| Toto QA / ARFBench | Evaluates question-answering over time-series data | It shifts the goal from forecasting numbers to answering natural-language questions. |
| Archetype AI Newton TimeFusion | Uses a shared token vocabulary for language and sensor time series | It is a commercial sensor-language model with forecasting, captioning, anomaly detection, and text-to-signal generation. |
| Migas 1.5 | Summarizes text context, embeds it, and fuses it with a Chronos-2 forecast | It is a forecast-first system where language moves the numerical curve. |
Those systems are related, but they are not the same category. A model that answers ECG questions from text and multivariate signals is a TSLM in a different sense from a model that adjusts a 16-step commodity forecast when OPEC news changes. A prompt-based sentence-to-sentence forecaster is different again. The field is too young for a single taxonomy to carry all of that.
The safer way to say it: Migas 1.5 adds an important open-weight member to the early text-and-time-series model zoo. Its contribution is not being first in the broad sense. It is being especially clear as a forecast-first API design pattern.
#The model zoo is splitting into patterns
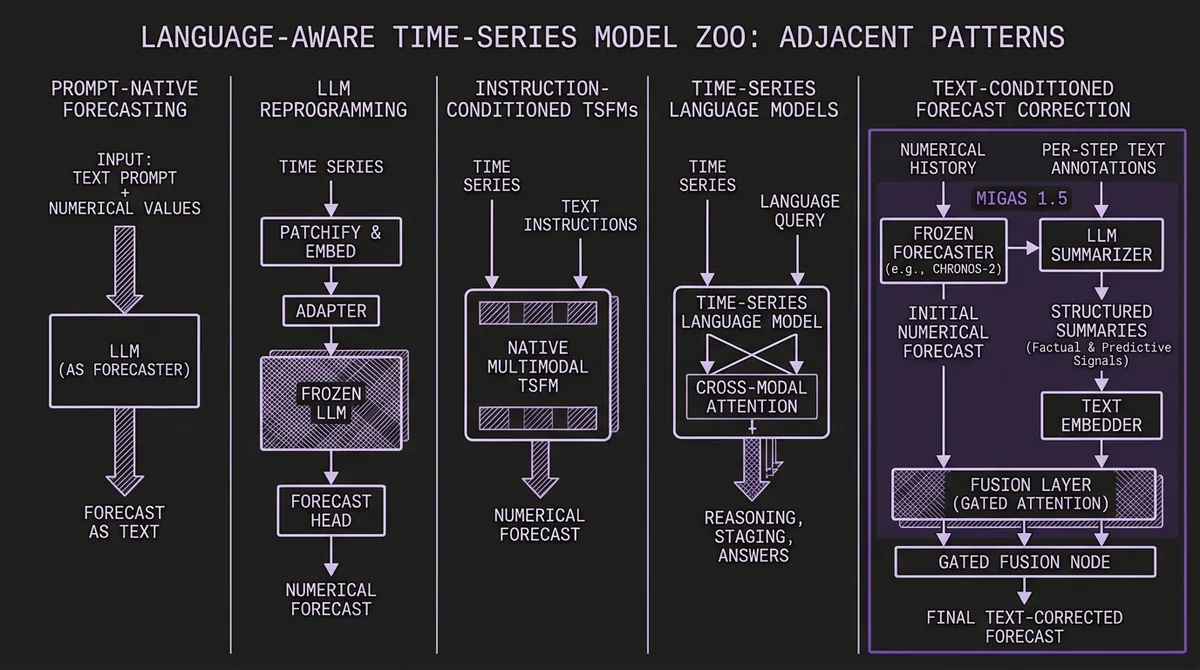
We now see at least five patterns in language-aware time-series systems.
LLM reprogramming keeps the LLM mostly intact and learns an adapter from numerical patches into language-model space. Time-LLM is the canonical example. This line is attractive because it borrows world knowledge and instruction-following behavior from LLMs, but it inherits LLM cost and can be awkward when the output must be a calibrated numeric distribution.
Prompt-native forecasting turns time series into text and asks a language model to produce the future. PromptCast showed the idea early. This is conceptually clean, but it scales poorly when precision, horizon length, or probabilistic calibration matter.
Instruction-conditioned TSFMs use natural language to identify the task, domain, or data source while keeping the forecast head numerical. UniTime and parts of Aurora fit here. This pattern is close to multimodal time series forecasting as a native model capability.
Time-series language models make time series a first-class modality for language-model-style reasoning. OpenTSLM is the clearest named open research example: its Hugging Face checkpoints include Gemma-3 variants trained with a Flamingo-style cross-attention architecture. These systems are not just forecasting; they can classify, explain, stage, answer, or reason over physiological and sensor traces.
Sensor-language foundation models push the same idea into physical systems. Archetype AI's Newton TimeFusion uses a joint token vocabulary for natural language and sensor streams, then exposes signal-to-text, text-to-signal, forecasting, imputation, and anomaly detection. It is more physical-AI platform than forecast API, but it is directly relevant to the broad "text plus time series" category.
Text-conditioned forecast correction is where Migas lands. A numerical TSFM remains the backbone. Text is processed into a compact signal. The model learns how much to adjust the numeric baseline. This is less grand than a single universal multimodal model, but it is easier to ship.
For production forecasting, the last pattern may be the most immediately useful. It keeps a strong forecaster in the loop, keeps text optional, and can run with precomputed summaries. It also gives users a natural counterfactual interface: hold the same price history fixed, change the narrative, and inspect how the forecast moves.
#Why Migas is practically interesting
The first practical point is that Migas is small enough to inspect. The Hugging Face model is open-weight under Apache-2.0, and the released checkpoint is tiny by foundation-model standards. The expensive parts are not the Migas fusion weights; they are the numerical backbone, the text embedder, and the optional LLM summarization layer.
The second point is that Migas can operate in an offline-summary mode. The repository examples explicitly support passing summaries= directly. That means a service does not have to put an LLM in the hot path for every forecast. A user or upstream agent can prepare the factual summary and predictive signals, then the forecast model can consume those strings deterministically.
The third point is that Migas makes the evaluation problem visible. Synthefy reports results on multimodal datasets spanning finance, macroeconomics, retail, and energy, with held-out windows and text annotations. The released dataset includes aligned t, y_t, and text fields. That is useful, but it also underlines the hard part: the quality of a text-conditioned forecast depends on the quality, timing, and provenance of the text.
A numeric-only benchmark asks a clean question: given this history, what is the forecast? A text-conditioned benchmark asks a messier one: given this history and this narrative, should the model believe the narrative, ignore it, or partially discount it? If the text is generated after the fact, was it written with future knowledge? If it is retrieved from news, what publication time is allowed? If it is user-provided, how do we detect hallucinated or strategically biased context?
Those questions are not reasons to ignore the category. They are reasons to be precise about evaluation. We made a similar point in TFRBench and reasoning evaluation: once models consume language, the benchmark is no longer just a table of values. It is a specification of the information boundary.
#What it means for forecast APIs
The obvious API extension is a context or summaries field alongside the numerical payload. But the details matter.
A forecast API should distinguish at least four text modes:
- static series description, such as "daily crude oil price in USD per barrel";
- historical per-step annotations, such as aligned news or event notes;
- forward-looking known events, such as planned outages, holidays, promotions, or policy changes;
- model-ready summaries, such as "FACTUAL SUMMARY" and "PREDICTIVE SIGNALS".
Those modes have different leakage risks. A static description can usually be trusted. Historical annotations require timestamp discipline. Forward-looking events are legitimate if they were known at forecast time. Model-ready summaries are powerful but need provenance, because they can smuggle future information into the request.
This is why text-conditioned forecasting is not just "covariates, but in prose." Structured covariates have typed columns, known availability, and explicit future values. Text context is richer and less constrained. It can carry facts, causal hypotheses, uncertainty, and speculation in one paragraph. That is exactly why it can help. It is also why a production system needs guardrails.
For TSFM.ai, the right near-term framing is experimental model support rather than treating Migas as a drop-in replacement for existing numerical models. Hosted numeric TSFMs such as Chronos-2, TimesFM, Toto, and other numeric models can remain the default workhorses. Text-conditioned models should enter the catalog with explicit input semantics, horizon constraints, and benchmark notes.
#Limits to keep in view
Migas 1.5 has clear constraints. The public examples focus on 16-step predictions. The released evaluation is primarily financial and economic. Automatic summarization requires an LLM or precomputed summaries. The default text embedder has to match the training configuration. And the public examples appear to produce point forecasts, whereas many operational forecasting systems need quantiles or full predictive distributions.
There is also a more subtle limitation: text can move the forecast for the wrong reason. If the summary overstates an event, repeats stale news, or encodes an analyst's bias, a text-conditioned model may faithfully incorporate that bad signal. Numeric-only models miss external context; text-conditioned models can overreact to context. The better system is not the one that always listens to the narrative. It is the one that learns when the narrative is worth discounting.
That is why the most important baseline for Migas is not only Chronos-2 without text. It is Chronos-2 plus disciplined structured covariates, plus a leakage-controlled text pipeline, plus ablations where the narrative is perturbed. The counterfactual examples in the repository are compelling because they show controllability. The next benchmark layer should test robustness.
#The takeaway
Migas 1.5 is a useful release because it makes text-conditioned forecasting feel less abstract. The architecture is understandable. The input format is close to what users already have. The open weights and notebooks make it testable. And the design points toward a practical middle ground between numeric TSFMs and full time-series language models.
We should still be careful with category claims. The early TSLM model zoo already includes prompt-based forecasting, LLM reprogramming, instruction-conditioned models, medical time-series reasoning models, sensor-language systems, and telemetry QA systems. Migas does not erase that history. It adds a concrete, forecast-first pattern to it: use a strong numerical backbone, summarize the context, fuse the two, and let the story move the curve only when it should.
That is enough to matter.