Aurora: What the First Multimodal Time Series Foundation Model Actually Does
Aurora (ICLR 2026) is the first pretrained TSFM to fuse text and visual structure at training time — and it benchmarks above Chronos, Moirai, and TimesFM on both deterministic and probabilistic metrics. Here's what the architecture actually does, what 'multimodal' means in practice, and how to run it today.
When we wrote about multimodal time series forecasting in February, the post was necessarily abstract. The field had promising research directions — LLM reprogramming, text-conditioned forecasting, retrieval-augmented series — but no single model that put all of it together and released weights. Aurora, presented at ICLR 2026 by the Decision Intelligence group at East China Normal University, changes that. It is the first pretrained time series foundation model designed from the ground up to consume multiple modalities, and it is available right now on HuggingFace under an MIT license (paper, code).
There is a catch, and it is worth stating plainly: "multimodal" in Aurora's case does not mean what most people will assume. Users do not pass in images. The model is not a vision-language system applied to charts. Understanding the actual architecture is essential both for using the model correctly and for grasping why it outperforms Chronos, Moirai, and TimesFM across three major benchmarks.
#What "Multimodal" Actually Means
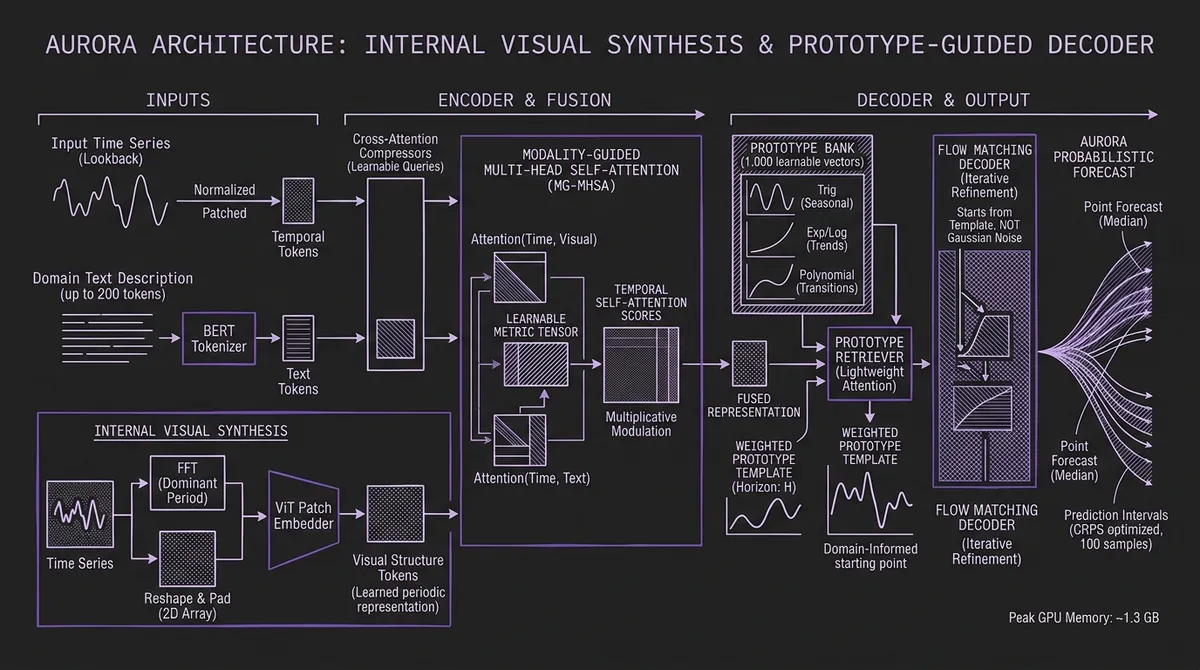
Aurora's encoder processes three input streams: time series, images, and text. The time series stream is straightforward — the input window is instance-normalized and patched into tokens in the standard way. The text stream accepts a free-form domain description, tokenized through BERT, up to 200 tokens. The image stream is where the architecture gets interesting.
Aurora does not accept user-provided images. Instead, it generates an image from the time series itself using a simple but principled process: run FFT on the input series to find its dominant frequency, pad the series to a multiple of that period, reshape it into a 2D array, replicate across three channels, and feed the result through a ViT-style patch embedder. The output is a learned visual representation of the series' periodic structure.
This matters because the image branch is not a cosmetic addition. It extracts information that numerical patching naturally misses. A series with a 52-week seasonal pattern and a 4-week secondary harmonic will produce a distinctive 2D texture that a ViT can encode into a compact vector, regardless of whether the absolute values are electricity consumption or web traffic. The image branch learns to recognize structural patterns — seasonality shape, harmonic relationships, trend inflection geometry — as spatial features.
The three token sequences are then distilled through cross-attention compressors with learnable query vectors, and fused through what the authors call Modality-Guided Multi-head Self-Attention. Rather than simply concatenating modality tokens, the fusion mechanism computes cross-modal attention matrices between the time and image representations and between the time and text representations, combines them via a learnable metric tensor, and injects the result directly into the temporal self-attention score matrix. Domain knowledge from text and periodic structure from the synthesized image shape which time steps attend to which — not as an additive bias but as a multiplicative modulation of attention weights.
Ablation results confirm this is load-bearing: removing the modality-guided attention alone raises MSE on the Climate domain from 0.865 to 1.176, a 36% degradation, even with the prototype decoder intact.
#The Decoder: Prototype-Guided Flow Matching
Most probabilistic TSFMs generate uncertainty by sampling from a Gaussian starting distribution — either through autoregressive token sampling (Chronos) or diffusion-style denoising from isotropic noise (Sundial, which we covered in our diffusion models post). Aurora's decoder takes a different starting point, literally.
The model maintains a Prototype Bank of 1,000 learnable vectors, initialized from explicit temporal basis functions: trigonometric sequences (capturing seasonality), exponential and logarithmic curves (trends), and polynomials (smooth transitions). Each prototype represents a qualitatively distinct temporal shape. The Prototype Retriever — a lightweight attention network that consumes the fused text and image representations — outputs a weighted distribution over all 1,000 prototypes, producing a per-horizon template that reflects the domain's expected structural behavior.
During inference, this prototype blend replaces random Gaussian noise as the starting point for flow matching. Instead of iteratively denoising from pure noise into a forecast, Aurora refines from a structured, domain-informed template. The flow-matching objective learns to correct the prototype — adjusting amplitude, phase, and irregular fluctuations — rather than generating structure from scratch.
The practical consequence is that Aurora needs far fewer denoising steps than Sundial or other diffusion models, because the starting distribution is already close to the target. And because the starting point is conditioned on the domain (via the Prototype Retriever, which consumes text and image tokens), the probabilistic samples are meaningfully anchored rather than scattered across all plausible temporal shapes.
The authors recommend drawing 100 samples per inference, which is the design target for the probabilistic output. This adds compute versus point-forecast models, but the peak GPU memory at inference is only ~1.3 GB, keeping it accessible on single-GPU deployments.
#Benchmark Results
Aurora is evaluated across three benchmarks covering deterministic, probabilistic, and multimodal zero-shot settings.
#TSFM-Bench: Deterministic Zero-Shot
On the standard long-term forecasting suite (ETT, Weather, Electricity, Traffic, Solar, PEMS08, Wind), Aurora outperforms Chronos, Moirai, and TimesFM on every dataset where they are all evaluated. The largest margins are on Solar (-48% MSE vs. Chronos), Traffic (-15% vs. Chronos), and PEMS08 (-67% vs. Chronos). On ETT, the average MSE is 0.331 versus 0.382 for Moirai and 0.442 for Chronos.
#ProbTS: Probabilistic Zero-Shot
On CRPS — the standard metric for evaluating distributional forecast quality — Aurora earns first place on ETT, Weather, Traffic, and Exchange-Rate. It narrowly trails Sundial on Electricity (0.085 vs. 0.081). The CRPS reduction versus Moirai averages 38%, and versus Chronos it averages roughly 20%. For context, see our discussion of prediction intervals and calibration for why CRPS is the right metric when you care about uncertainty coverage.
#TimeMMD: Multimodal Zero-Shot
TimeMMD is the only benchmark that provides paired time series and text metadata across nine domains (Agriculture, Climate, Economy, Energy, Environment, Health, Security, Social Good, Traffic). In fully zero-shot mode — no labeled downstream data — Aurora wins on seven of nine domains. The two exceptions are Security (where Sundial edges it out) and Health (where supervised models with 10% training data win, but Aurora leads among zero-shot baselines). Average MSE reduction versus Sundial across the nine domains is 27%, and versus VisionTS it is 31%.
The comparable models in the multimodal setting are largely supervised (GPT4MTS, CALF) and use 10% of downstream data, which Aurora matches or beats on most domains without any fine-tuning. This makes it the strongest zero-shot result on a multimodal time series benchmark reported to date.
#Model Comparison Summary
| Model | Params | Probabilistic | Text Input | Zero-Shot |
|---|---|---|---|---|
| Aurora | ~0.4B | Yes (flow matching) | Yes (BERT, 200 tok) | Yes |
| Sundial | 128M | Yes (flow matching) | No | Yes |
| Chronos-Large | 710M | Yes (autoregressive sampling) | No | Yes |
| Moirai-Large | 311M | Yes (mixture output) | No | Yes |
| TimesFM 1.0 | 200M | Partial (quantile) | No | Yes |
Aurora's text conditioning is the only user-facing multimodal feature among production TSFMs.
#Using Aurora Today
The model is available via pip install aurora-model==0.2.0 and weights are on HuggingFace at DecisionIntelligence/Aurora. The inference API uses channel-independence: each variable in a multivariate series is processed as an independent row.
Unimodal (time series only):
from aurora import load_model
import torch
model = load_model()
# One variable per row: (batch × n_vars, lookback_length)
seqs = torch.randn(1, 528).cuda()
output = model.generate(
inputs=seqs,
max_output_length=96, # forecast horizon
num_samples=100, # draw 100 probabilistic samples
inference_token_len=48, # set to your series' dominant period length
)
# output: (batch, horizon, 100) — 100 sample trajectories
With text conditioning:
from aurora import load_model
from einops import rearrange
import torch
model = load_model()
tokenizer = model.tokenizer
seqs = torch.randn(1, 528, 10).cuda() # batch=1, lookback=528, n_vars=10
text = "Daily electricity demand for a manufacturing facility in Central Europe, 2019-2024."
tok = tokenizer(text, padding='max_length', truncation=True,
max_length=200, return_tensors="pt")
n_vars = 10
batch_x = rearrange(seqs, "b l c -> (b c) l") # channel-independence
input_ids = tok['input_ids'].repeat(n_vars, 1).cuda()
attn_mask = tok['attention_mask'].repeat(n_vars, 1).cuda()
output = model.generate(
inputs=batch_x,
text_input_ids=input_ids,
text_attention_mask=attn_mask,
max_output_length=96,
num_samples=100,
inference_token_len=48,
)
The inference_token_len parameter deserves attention. It controls the patch size for both the temporal tokenizer and the FFT-based image renderer. Setting it to the dominant period of your series — 7 for daily data with weekly seasonality, 24 for hourly with daily cycles — gives the model the right inductive bias. The authors use 48 for energy datasets and 12 for health data. If you do not know the period, the model degrades gracefully but you leave performance on the table.
Text descriptions can be brief or detailed. The tokenizer truncates at 200 BERT tokens, so a sentence describing the domain, geography, and approximate frequency is sufficient. More specific descriptions of known events or regime changes can help, but Aurora has not been benchmarked on adversarial or misleading text inputs — treat text conditioning as a hint, not a guarantee.
#What This Changes
Aurora's release is significant for several reasons that go beyond its benchmark numbers.
First, it is the first foundation model to demonstrate that text conditioning at pretraining time — not post-hoc LLM reprogramming — improves zero-shot accuracy across multiple domains. The LLM reprogramming approaches we have covered previously adapt a frozen language model at inference time. Aurora learns the cross-modal fusion jointly, which the ablations suggest is qualitatively different.
Second, the prototype bank approach offers a principled alternative to Gaussian-start diffusion that is specifically tailored to time series. The insight — that forecast distributions should start near known temporal shapes, not random noise — is simple and extensible. It would be surprising if this design choice does not appear in subsequent models.
Third, the model is practically accessible. MIT license, HuggingFace weights, pip install, 1.3 GB peak memory, no proprietary API dependency. For teams evaluating TSFMs today, Aurora belongs in the same comparison set as Chronos and Moirai. Our model selection guide will be updated to reflect it.
#Limitations to Keep in Mind
Aurora's text conditioning is trained on GPT-4-generated descriptions, not organic human-written metadata. How well it transfers to real-world domain notes, system documentation, or terse internal labels is untested. The benchmark text descriptions are carefully crafted; production text annotations rarely are.
The probabilistic output requires 100 samples for full quality — which is 100 forward passes through a 0.4B parameter model. For latency-sensitive applications where zero-shot forecasting needs to run in milliseconds, that is a hard constraint. The authors report 83.5ms per sample on a single A800, implying ~8 seconds for the full 100-sample draw, which is viable for batch workloads but not real-time streaming inference.
And despite the multimodal framing, users cannot supply their own images. The visual pathway is entirely internal. Researchers hoping to feed in time series visualizations, chart screenshots, or satellite imagery will need to build that capability themselves — it is not in the current release.
#Looking Ahead
Aurora is part of a broader emerging pattern: the same Decision Intelligence group has also released CoRA, a plug-and-play adapter for adding cross-channel correlation to any channel-independent TSFM. The two models are complementary — Aurora as a generalist foundation, CoRA as a fine-grained adaptation mechanism. Together they represent a coherent research program aimed at closing the remaining accuracy gap between foundation models and specialized supervised forecasters.
At ICLR 2026, the TSALM workshop (Time Series in the Age of Large Models) ran for the first time, organized by teams behind Lag-Llama, Chronos, Moment, Moirai, and TimesFM. Aurora's reception there signals that multimodal pretraining is now a serious research direction, not a speculative one. Expect to see text-conditioned pretraining adopted by other major TSFM labs in the next 12 months.
For now: the model is on HuggingFace, the license is MIT, and the results are meaningful. It is worth running on your data.