ICLR 2026 TSFM Roundup: 87 Time Series Papers and What They Mean for the Field
ICLR 2026 accepted 87 time series papers — the first year with a dedicated TSALM workshop. Here's what the research community spent the year building: multimodal pretraining, elucidated diffusion, prototype-guided generation, and a renewed focus on rigorous evaluation.
ICLR 2026 wrapped up in Rio de Janeiro on April 27 with a record 5,359 papers accepted across all domains. Of those, roughly 87 are time series papers — a number that has grown every year but now feels qualitatively different. For the first time, ICLR hosted a dedicated Time Series in the Age of Large Models (TSALM) workshop, organized by researchers behind Lag-Llama, Chronos, Moment, Moirai, and TimesFM. The workshop's existence signals that the field has reached sufficient mass to warrant its own venue, not just a corner of a general ML program.
This post covers the themes, standout papers, and what they collectively suggest about where time series research is heading. It is a companion to our deeper dives on Aurora and TEDM, both also from ICLR 2026.
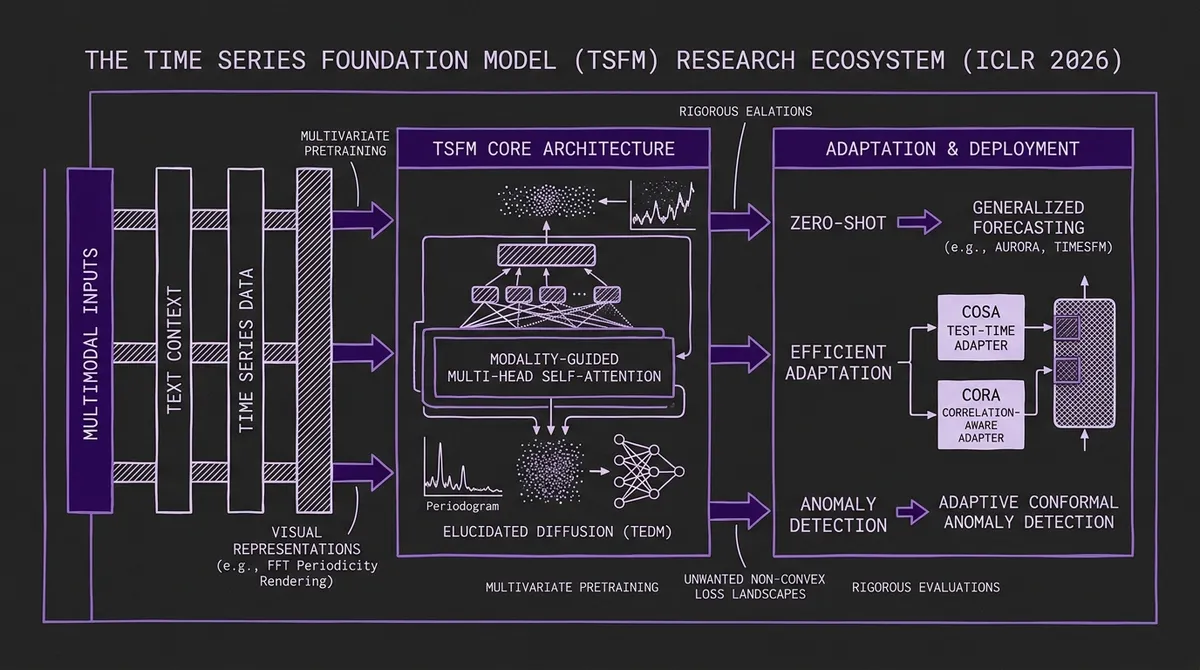
#Theme 1: Multimodal Pretraining Goes From Concept to Reality
Two years ago, multimodal time series forecasting was an emerging research direction with no released models. By ICLR 2026, at least three distinct papers tackle multimodal pretraining, and the most significant one — Aurora — has public weights on HuggingFace.
Aurora ("Towards Universal Generative Multimodal Time Series Forecasting") from East China Normal University is the most complete implementation: a 0.4B parameter model trained jointly on time series, synthesized visual representations (via FFT-based period rendering), and GPT-4-generated domain text. The multimodal angle is more subtle than it first appears — the "images" are internally generated from the series' periodic structure, not user-supplied — but the Modality-Guided Multi-Head Self-Attention that fuses all three streams is a genuine architectural contribution. Aurora beats Chronos, Moirai, and TimesFM on standard zero-shot benchmarks and wins seven of nine TimeMMD domains without any fine-tuning. See our full Aurora breakdown for architecture details and runnable code.
SE-LLM ("Semantic-Enhanced Time-Series Forecasting via Large Language Models") takes the LLM reprogramming approach further with a Temporal-Semantic Cross-Correlation module that eliminates the need for manually crafted auxiliary text descriptions. The time series and its semantic representation are learned jointly, removing the domain-expertise bottleneck that limited earlier text-conditioned approaches.
Multi-Scale Hypergraph Meets LLMs proposes hypergraph-based multi-scale alignment to bridge time series representations with LLM embedding spaces — a structurally different approach to the same cross-modal alignment problem.
Together these papers establish that text conditioning at pretraining time (not just post-hoc LLM prompting) is a viable research direction. The practical gap remains: no production TSFM API currently exposes a context text field. That gap will close.
#Theme 2: Diffusion Models Mature Beyond DDPM
Our Sundial post from 2025 covered flow matching as an alternative to DDPM-style diffusion for time series. ICLR 2026 shows this space continuing to evolve in multiple directions.
TEDM ("Time Series Forecasting with Elucidated Diffusion Models") applies Karras et al.'s EDM design-space framework to time series, replacing hand-crafted noise schedules with data-derived covariance estimates. The result: O(H) linear inference complexity (one network evaluation per forecast step), fastest training time among all diffusion baselines at 0.004 seconds per batch, and competitive or best MSE on four of eight evaluated datasets. The trade-off is weak probabilistic calibration via SDE sampling, though a novel ODE-based quantile method shows early promise. Full details in our TEDM deep-dive.
"Bridging Past and Future: Distribution-Aware Alignment for Time Series Forecasting" addresses the distributional shift between historical and future windows — a core failure mode for models trained on stationary assumptions but deployed on non-stationary series.
"Reliable Probabilistic Forecasting of Irregular Time Series through Marginalization-Consistent Flows" extends normalizing flows to handle irregular observation times while preserving marginalization consistency — critical for correctly computing marginal uncertainty at individual time points from a joint distribution.
"Conditionally Whitened Generative Models for Probabilistic Time Series Forecasting" introduces conditional whitening as a preprocessing step inside a generative model, improving distributional coverage on heavy-tailed series where standard Gaussian assumptions underperform.
The pattern across these papers is that the diffusion and flow-matching community has shifted from "can we apply this to time series?" to "what properties should probabilistic time series models have, and how do we engineer them?" — a more mature framing.
#Theme 3: Foundation Model Adaptation
The TSFM landscape now includes 18+ pretrained models, and a growing body of research focuses on how to adapt them efficiently rather than training new ones from scratch. ICLR 2026 has several papers in this vein.
CoRA ("Correlation-Aware Adapter for TSFMs") — which we covered separately at /blog/cora-correlation-aware-adapter-tsfms — adds lightweight cross-channel correlation awareness to channel-independent TSFMs like Timer and TimesFM via a low-rank adapter. From the same Decision Intelligence group as Aurora, it complements the base model by addressing the specific weakness of channel-independence: the inability to model interactions between time series variables.
FORMED ("Repurposing Foundation Model for Generalizable Medical Time Series Classification") shows that a generic TSFM, fine-tuned with only 0.1% of parameters via a label-query training scheme, can achieve up to 35% absolute F1-score improvement over specialized medical baselines on five ECG and clinical datasets. This is a meaningful result for practitioners in health AI: you do not need a domain-specific pretrained model if you adapt the right way.
COSA ("Context-aware Output-Space Adapter for Test-Time Adaptation") addresses the non-stationarity problem at inference time. Rather than adapting model weights, COSA adapts the output space of any pretrained forecaster at test time — a practical approach that requires no fine-tuning access to the model internals. This is particularly relevant for closed-source or API-served models.
"Lost in the Non-convex Loss Landscape: How to Fine-tune the Large Time Series Model?" is the paper in this group that every practitioner who has tried fine-tuning a TSFM should read. It provides an empirical and theoretical analysis of why fine-tuning large TSFMs is difficult — specifically characterizing the non-convex loss landscape features that cause fine-tuning runs to diverge or underperform zero-shot baselines — and proposes concrete mitigation strategies.
#Theme 4: Anomaly Detection With and Beyond TSFMs
Anomaly detection continues to be a growth area for time series research, and ICLR 2026 sees the TSFM paradigm explicitly applied to it.
"Adaptive Conformal Anomaly Detection with Time Series Foundation Models for Signal Monitoring" uses a pre-trained TSFM as a prediction engine and wraps it with adaptive conformal prediction to produce anomaly scores with valid coverage guarantees — no fine-tuning required. This is the right architecture for production monitoring: swap in any foundation model, get calibrated detection without domain-specific training.
ALoRa-T ("Low Rank Transformer for Multivariate Time Series Anomaly Detection and Localization") introduces low-rank regularization to self-attention for anomaly detection, with a companion module ALoRa-Loc for variable-level anomaly localization. The variable-level localization is practical: knowing that an anomaly occurred in a 137-channel multivariate series is less useful than knowing which two channels are anomalous.
PGRF-Net ("Prototype-Guided Relational Fusion Network") generates four types of anomaly evidence from a relational graph structure and fuses them via a gated network, providing both detection performance and four interpretable evidence signals per anomaly. This explainability angle addresses a consistent practitioner complaint about black-box anomaly detectors. For more on anomaly detection generally, see our earlier post.
"When Foundation Models are One-Liners" takes a critical perspective — examining gaps between foundation model capabilities and real-world anomaly detection requirements, and identifying research directions the community has not yet addressed. This kind of audit paper is valuable precisely because the anomaly detection literature tends toward benchmark optimization rather than deployment reality.
#Theme 5: Evaluation Gets More Rigorous
The benchmarking problem in time series ML has been well-documented. ICLR 2026 brings several papers that push toward more credible evaluation.
"Global Temporal Retrieval (GTR)" addresses a specific evaluation blindspot: standard fixed lookback windows miss long-range periodic patterns that extend beyond the context. GTR is a plug-and-play module that retrieves globally periodic patterns from the full training history — effectively giving any forecaster memory that extends beyond its context window. Performance gains are measured on benchmarks specifically designed to expose this limitation, making the comparison cleaner than typical benchmark results.
MoVE ("Mixture of Temporal and Cross-Variable Experts") and PHAT ("Period Heterogeneity for Multivariate Time Series Forecasting") both address the assumption that all channels share the same dominant periodicity — a common modeling convenience that is routinely violated in real multivariate datasets. PHAT explicitly models per-channel periodicity; MoVE uses a mixture-of-experts to separate temporal and cross-variable processing.
TimeSliver is the explainability entry of the roundup: symbolic-linear decomposition for time series classification that produces segment-level attributions independent of sequence length. It outperforms post-hoc attribution methods by 11% on seven datasets while staying within 2% of SOTA accuracy on the 26-dataset UEA benchmark. Explainability and accuracy at the same time, on real benchmarks — notable.
MambaSL ("Single-Layer Mamba for Time Series Classification") shows that a carefully designed single-layer Mamba, guided by four classification-specific inductive bias hypotheses, achieves SOTA on the UEA30 benchmark. The result matters less for the Mamba angle than for what it implies: classification benchmarks may not require the depth that forecasting benchmarks seem to.
#What the TSALM Workshop Signals
The TSALM workshop being organized by teams behind Lag-Llama, Chronos, Moment, Moirai, and TimesFM simultaneously suggests both community maturity and healthy competition. These are not collaborating institutions — they are competing labs who agreed to share a workshop venue because the community around time series foundation models is now large enough to warrant one.
The workshop's stated research agenda — context-informed predictions, LLM agents for time series, interpretability, rigorous evaluation — maps almost exactly to the gaps we identified in our 2026 TSFM outlook: covariate handling, uncertainty quantification, and benchmark validity. The fact that the workshop organizers named these as priority areas suggests they are the consensus gaps, not just our read of the field.
#The Papers to Track
Across 87 papers, a handful stand out as most likely to influence the next 12 months:
Aurora — because it is the first multimodal TSFM with released weights, and multimodal pretraining is the next obvious frontier.
TEDM — because the EDM design-space analysis is a methodological tool that other diffusion-based forecasting work can build on, independent of TEDM's specific numbers.
"Lost in the Non-convex Loss Landscape" — because fine-tuning is a problem that affects every practitioner trying to adapt a TSFM to their data, and this paper names the failure mechanism precisely.
CoRA and the adapter family — because the practical path for most production deployments is adapting an existing model, not training a new one, and ICLR 2026 significantly advances the adapter toolkit.
Adaptive Conformal with TSFMs — because monitoring applications need calibrated detection guarantees, and this paper shows you can get them on top of any pretrained foundation model without fine-tuning.
#What Is Still Missing
For all the progress, ICLR 2026 reflects the field's remaining blind spots as much as its advances. No paper in the time series track addresses real-time streaming inference at production scale. The streaming inference challenges we have discussed — context window management, stateful inference, latency constraints — remain largely unaddressed in the academic literature. Every benchmark involves batch offline evaluation.
The multimodal papers are exciting, but all train on GPT-4-generated synthetic text. No paper presents evaluation on real-world domain annotations — the kind of terse, inconsistent, often wrong metadata that actually lives in production databases. The performance on carefully crafted benchmark descriptions may not transfer.
And despite progress on evaluation methods, the benchmarking challenges are not solved. Different papers evaluate at different horizons, with different normalization, on different train/test splits, making direct comparison difficult. The TIME benchmark and GIFT-Eval frameworks we have covered previously are steps toward standardization; ICLR 2026 does not yet build on them uniformly.
The field is maturing. The TSALM workshop, the 87 papers, Aurora's released weights, TEDM's efficiency numbers — these are signs of a community that has moved from exploration to execution. The gaps that remain are harder to close, which is why they remain.