TFRBench: The First Benchmark for Evaluating Reasoning in Forecasting Systems
Nearly every time series benchmark measures whether a model predicts the right numbers. TFRBench (arXiv:2604.05364, April 2026, Google Cloud AI Research) asks a different question: can the model explain *why*? According to its authors, TFRBench is the first benchmark designed to evaluate the reasoning capabilities of forecasting systems — covering cross-channel dependencies, trends, seasonality, and external events — finding that off-the-shelf LLMs consistently struggle with temporal reasoning, while models prompted with high-quality reasoning traces improve from about 40.2% to 56.6% on the share of series beating the naive baseline. The implications touch deployment design decisions across any organization asking forecasting systems to justify their outputs.
Nearly every major time series benchmark asks the same question: did the model predict the right numbers? MASE, MAE, CRPS — the metrics vary, but the evaluation target is invariant. You compare the predicted distribution against the observed outcome, and better numbers mean a better model.
This framing misses a growing category of forecasting system failure. In supply chain and operations, a model that generates a demand spike forecast without flagging the promotional event that drives it is generating a correct number from the wrong reasoning. In finance, a forecast for Apple's close price that doesn't account for the relationships between price channels, volume, and scheduled economic events is missing structure that a practitioner would notice immediately. In regulated industries — healthcare, energy trading, financial services — forecast explanations increasingly need to be accurate and defensible, not just plausible-sounding. The problem is not that the forecast is wrong — it is that the system is reasoning incorrectly about the world, and the accuracy metric cannot tell you that.
TFRBench (arXiv:2604.05364, April 2026, from Google Cloud AI Research and the University of Kentucky) is, according to its authors, the first benchmark designed to evaluate the reasoning capabilities of forecasting systems. It introduces a structured protocol for assessing how well a system analyzes cross-channel dependencies, trend structure, seasonality, and external events before generating a forecast. Its two headline findings are stark: off-the-shelf LLMs consistently fail to produce high-quality temporal reasoning, yet models prompted with high-quality reasoning traces dramatically improve their own forecasting accuracy — from about 40.2% to 56.6% on the share of series where the model beats the naive baseline.
#Why Reasoning Evaluation Is Different
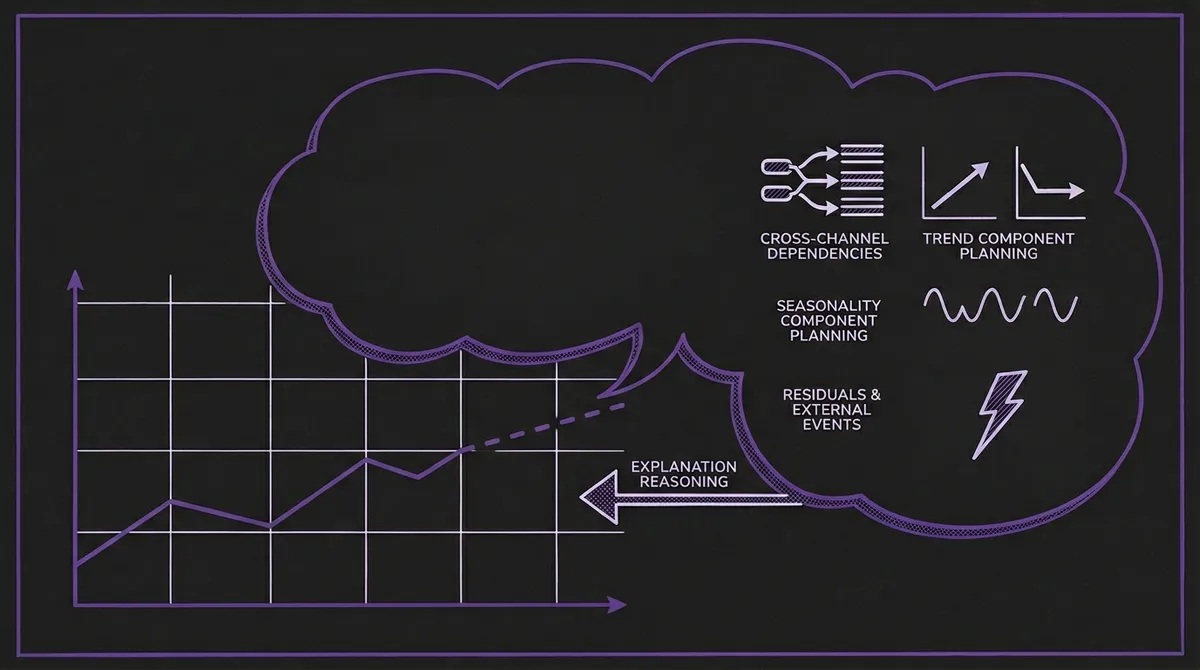
Time series foundation models generate predictions. They do not, as a rule, generate explanations. A model like Chronos or Moirai accepts a numerical context window and outputs a predictive distribution. It has no output channel for the reasoning it uses. You can probe its behavior — varying inputs, examining confidence intervals — but you cannot interrogate why it assigned a higher probability to one forecast trajectory over another.
This is by design. The TSF problem has been framed as a numerical prediction problem since its origins, and the architecture tradeoffs that define the field are optimized for that objective. But the landscape is shifting. Two threads are converging:
The LLM integration thread: As multimodal approaches advance and LLMs acquire time series capabilities (see Time-LLM, TimesFM in-context fine-tuning), the question of whether an LLM's textual reasoning about a time series is correct becomes a first-class deployment question. A system that produces a forecast accompanied by an incorrect trend analysis is actively misleading, regardless of whether the final number happens to be accurate.
The decision-support thread: The causal reasoning turn in TSFMs has framed the gap between observational prediction and interventional reasoning as the central frontier. A forecasting system that supports decision-making needs to explain the structure of the series to earn trust. Accuracy alone is insufficient for this role.
TFRBench aims to operationalize the evaluation of that explanation quality, giving it a concrete, reproducible score.
#What TFRBench Measures
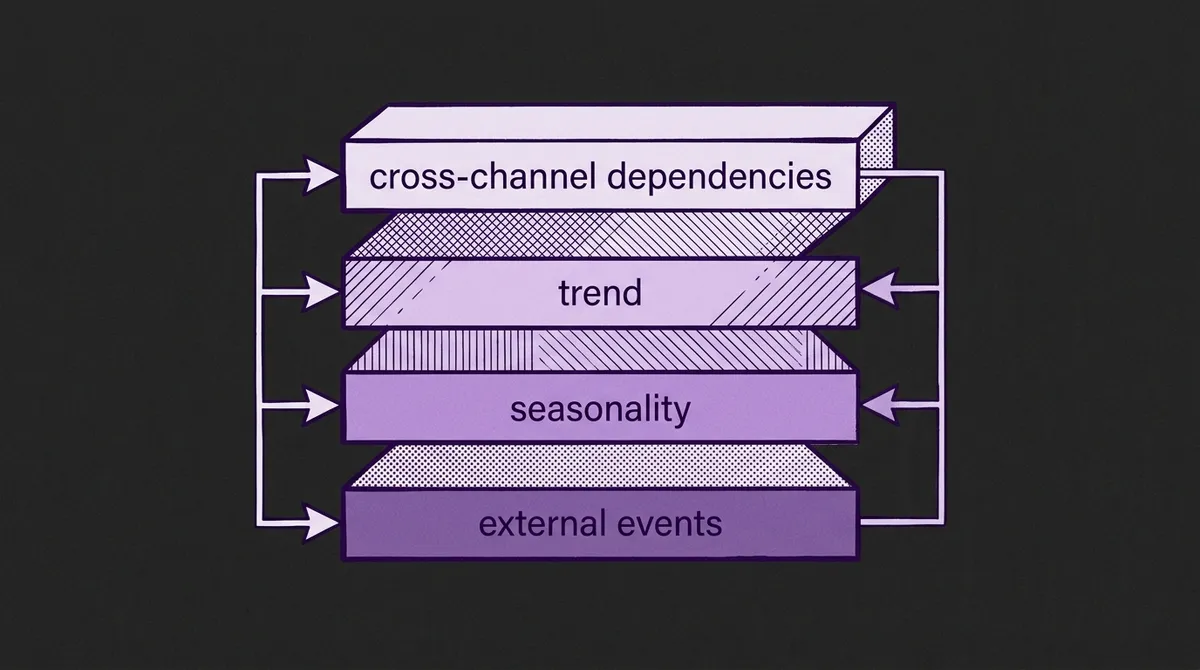
The benchmark defines four reasoning dimensions that any forecasting system's analysis should address:
Cross-channel dependencies: For multivariate series, does the system correctly identify how channels constrain and relate to each other? In the benchmark's Apple stock example, a correct analysis recognizes that the Close price must fall between the High and Low for every day; that Close anchors the next day's Open; and that a large Close move should be accompanied by increased Volume. A system that forecasts these channels independently without encoding these constraints is reasoning incorrectly about the data-generating process.
Trend component plan: Does the system correctly decompose and project the trend? Beyond "the trend is up," a useful trend analysis specifies the shape of the trend, whether it is expected to continue, flatten, or reverse, and why. In the stock example, the correct analysis identifies a recent sharp decline and models stabilization — not aggressive downward extrapolation — because the velocity of decline itself signals a potential bottoming process.
Seasonality component plan: Does the system correctly identify and project recurring periodic patterns? For series with clear cyclical structure — daily demand curves, weekly traffic patterns, annual energy consumption — a useful seasonality analysis specifies the periodicity, expected amplitude, and whether the seasonal pattern is stable or evolving.
Residuals and external events: Does the system correctly identify which scheduled or unscheduled events are likely to affect the series, and in which direction and magnitude? This requires both domain knowledge (knowing that a political event in November 1983 would affect market sentiment) and calibrated specificity (the correct analysis notes that the Senate Bombing should produce a 2–4% downward price shock, not just "market uncertainty").
Each dimension is scored using an LLM-as-a-Judge protocol, where a separate model evaluates the reasoning for accuracy, specificity, and logical consistency. While the benchmark's primary contribution is evaluating reasoning quality, the authors also evaluate numerical forecasting performance — and find that off-the-shelf LLMs struggle with both. Importantly, the paper shows that these two dimensions are linked: high reasoning scores correlate with better final forecast accuracy, and injecting high-quality reasoning traces into a forecasting system consistently improves its numerical output.
#The Data Creation Pipeline
A central challenge in building a reasoning benchmark is that there are no ground-truth "correct" reasoning traces for real-world time series. TFRBench addresses this with a multi-agent synthesis pipeline that produces numerically grounded reasoning traces through an iterative verification loop.
The pipeline has three stages:
1. Context retrieval and assumption generation: Given a time series sample, a retrieval agent identifies relevant domain context — historical patterns, known seasonality, any scheduled events in the forecast window. A reasoning agent then proposes a decomposed analysis: trend plan, seasonality plan, cross-channel constraints (for multivariate), and event plan.
2. Numerical grounding verification: The proposed reasoning trace is converted to a forecast, and the forecast is evaluated against a naive seasonal baseline. If MASE ≥ 1.0 (the forecast is not even beating the naive baseline), the pipeline rejects the reasoning trace and sends it back to the reasoning agent with feedback. The loop iterates until the forecast beats the naive baseline.
3. LLM verifier scoring: A separate LLM judge evaluates the reasoning trace for quality independently of the forecast. Traces that beat the naive baseline but receive low reasoning quality scores are also rejected. This dual-gate process ensures the benchmark contains only traces that are both numerically grounded and logically coherent.
The output of this pipeline for each series is a reference reasoning trace — the benchmark's approximate ground truth — plus the associated forecast. Evaluating a new forecasting system on TFRBench means generating its own reasoning trace for the same series and comparing it against the reference using the LLM-as-a-Judge protocol.
#The Dataset Composition
TFRBench spans ten datasets across five domains, selected to cover diverse temporal frequencies and channel structures:
| Domain | Dataset | Frequency | Window | Channels |
|---|---|---|---|---|
| Energy | Solar (GIFT-Eval) | Daily | 96 → 96 | 1 |
| Energy | Electricity (GIFT-Eval) | Daily | 96 → 96 | 1 |
| Sales | Car-parts (GIFT-Eval) | Monthly | 25 → 25 | 1 |
| Sales | Hierarchical Sales (GIFT-Eval) | Daily | 96 → 96 | 1 |
| Web/CloudOps | Bitbrains Fast Storage (GIFT-Eval) | Hourly | 96 → 96 | 2 |
| Web/CloudOps | Web Traffic (Monash) | Daily | 96 → 96 | 1 |
| Transportation | Traffic (Autoformer) | Hourly | 96 → 96 | 1 |
| Transportation | NYC Taxi (nyc.gov) | Hourly | 96 → 96 | 1 |
| Finance | Amazon pricing (Yahoo/Nasdaq) | Daily | 14 → 7 | 5 |
| Finance | Apple pricing (Yahoo/Nasdaq) | Daily | 14 → 7 | 5 |
The GIFT-Eval heritage of five out of ten datasets provides a deliberate connection to the existing TSFM evaluation ecosystem. Unlike pure accuracy benchmarks, TFRBench intentionally uses shorter context windows (14–96 steps) and shorter forecast horizons (7–96 steps), because these are the regimes where external event reasoning and cross-channel dependency analysis matter most — when the series is too short for pure pattern extrapolation to dominate.
The finance datasets are notably different in structure: five channels (Open, High, Low, Close, Volume) forecasted at a 7-day horizon from 14 days of context. This is exactly the configuration where cross-channel constraint reasoning is most clearly testable and most practically relevant.
#Finding 1: Off-the-Shelf LLMs Fail at Temporal Reasoning
The benchmark's evaluations reveal a consistent pattern: off-the-shelf large language models score poorly on TFRBench's reasoning metrics. The paper's finance example illustrates several characteristic failure modes:
Trend extrapolation errors: In the Apple stock example, the correct reasoning trace identifies a recent sharp decline and models stabilization, while LLM-generated traces tend to extrapolate the decline aggressively. The correct analysis requires decomposing the trend into a structural component and a momentum component and reasoning about which is likely to persist.
Cross-channel constraint violations: The benchmark's OHLCV finance datasets expose cases where models generate forecasts with the Close price falling outside the High-Low range — a logically impossible outcome that a human analyst would catch immediately. LLMs generate these because they do not encode channel ordering and statistical dependency constraints as hard rules.
Event attribution errors: The paper's example reasoning traces show calibrated event attribution (e.g., the Senate Bombing producing a 2–4% downward price shock), while LLM-generated traces tend to either over-attribute (treating minor events as major shocks) or under-attribute (ignoring events within the forecast window).
These failure modes are important for practitioners integrating LLMs into forecasting workflows. LLM-augmented forecasting systems may produce plausible-sounding reasoning that is technically incorrect and would mislead a practitioner who accepts it uncritically. TFRBench provides a standardized framework for detecting this.
#Finding 2: Correct Reasoning Dramatically Improves Numerical Accuracy
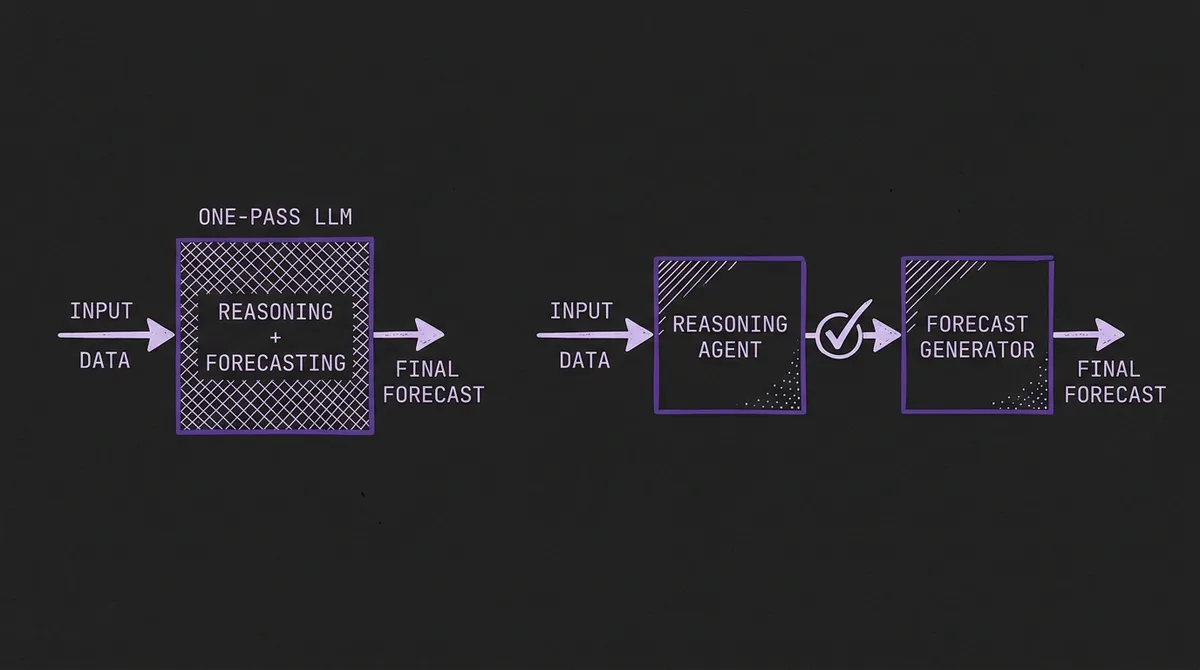
The flip side of the failure finding is the most actionable result in the paper. When LLMs are prompted with TFRBench's high-quality reasoning traces — rather than generating their own reasoning from scratch — the share of series where the model beats the naive baseline jumps from about 40.2% to 56.6%.
This 16-percentage-point gain is a large effect for a benchmarking intervention. It suggests that the bottleneck is not the LLM's numerical prediction capability — the model can produce good forecasts when reasoning is given to it — but rather its ability to independently generate correct temporal reasoning from the raw series and context.
The practical implication is a deployment design decision. A system that:
- Pre-generates structured reasoning traces from a specialized reasoning agent
- Validates those traces (trend analysis, channel constraints, event planning)
- Feeds the validated traces to an LLM for final forecast generation
...should significantly outperform a system that asks the LLM to do all three steps in one pass. This is the architecture that TFRBench's multi-agent synthesis pipeline uses internally, and in our view it parallels a pattern familiar from Retrieval-Augmented Generation (RAG) in the LLM world: separating retrieval/reasoning from generation tends to outperform end-to-end generation alone.
#Finding 3: Reasoning Quality Varies Across Domains
TFRBench's five-domain structure means reasoning difficulty is not uniform. The benchmark's dataset composition suggests some natural expectations about where LLM reasoning should struggle most:
Finance is structurally the most demanding: The multi-channel constraint structure and event sensitivity of OHLCV stock price series create the most surface area for reasoning failures. Cross-channel violations are immediately detectable (a Close outside High-Low is a logical impossibility), and the benchmark's finance examples demonstrate the kind of calibrated event attribution that LLMs tend to get wrong.
Seasonal domains offer more structure to exploit: Energy and sales series with strong, regular periodicity give trend-plus-seasonality reasoning a natural scaffold. Incorrect reasoning in these domains may still produce acceptable forecasts because the seasonal component dominates.
CloudOps and transportation sit between these extremes: Trend and seasonality patterns exist but are noisier, and external event attribution is less clearly defined.
This expected difficulty gradient has a natural parallel with the QuitoBench regime taxonomy: series with low forecastability and strong cross-variable dependencies (finance) should be harder for LLM reasoning than series with high forecastability and strong seasonality (energy). If confirmed by detailed per-domain results, this would mean the two benchmarks are evaluating complementary properties of the same underlying forecasting landscape.
#What TFRBench Means for TSFM Practitioners
TFRBench raises several deployment-level questions that practitioners should now be able to test empirically:
Question 1: Does your forecasting system produce reasoning output?
If you are deploying a pure numerical TSFM (Chronos, Moirai, TimesFM, Timer-S1), the answer is no by default. You can build reasoning wrappers around these models using the covariate and exogenous regressor patterns as a starting point, but the base models do not natively explain their outputs. TFRBench establishes a protocol for measuring the quality of any reasoning wrapper you add.
Question 2: If you are using an LLM-augmented forecasting system, is the reasoning correct?
TFRBench's LLM-as-a-Judge protocol provides a concrete way to audit the reasoning quality of LLM-generated forecasting analyses. This is particularly important in regulated sectors (healthcare, finance, energy trading) where forecast explanations must be accurate and defensible, not just plausible-sounding.
Question 3: Should you separate reasoning from generation?
The 40.2% → 56.6% accuracy improvement from pre-computed reasoning traces is a strong signal for multi-stage pipeline design. If your LLM-based forecasting system produces inconsistent reasoning quality, separating the reasoning stage (with its own validation loop) from the final numerical generation stage is likely to yield significant accuracy gains — TFRBench gives you a benchmark to measure that improvement.
Question 4: What is the right evaluation framework for reasoning-capable systems?
As the TSFMs vs world models debate continues and more systems claim reasoning capabilities, TFRBench provides a standardized framework for evaluating those claims. Pure accuracy metrics reward correct numbers from correct or incorrect reasoning alike. TFRBench separates the two, which is essential for deploying forecasting systems in contexts where the reasoning matters as much as the output.
#Novelty and Limitations
TFRBench's central novelty — scoring reasoning quality rather than numerical accuracy — creates a meaningful gap with all prior TSFM evaluation work, including GIFT-Eval, BOOM, FEV Bench, and QuitoBench. None of those benchmarks ask whether the reasoning behind a forecast is correct.
The main methodological limitation is the LLM-as-a-Judge protocol itself. Evaluating reasoning quality with another language model introduces circular dependency risk: the judge may prefer reasoning styles that match its own pretraining distribution, not reasoning styles that are objectively correct. The paper addresses this by using the dual-gate validation (the trace must also improve numerical forecast accuracy over the naive baseline), but the problem is not eliminated. As better external event knowledge bases and formal constraint checkers become available, they should augment or replace the LLM judge in future iterations.
The dataset scale is also modest — 10 datasets, 5 domains, shorter horizons. The benchmark is best understood as an existence proof and protocol proposal rather than a comprehensive evaluation corpus. Extension to longer horizons, more domains (observability/CloudOps at scale, macroeconomic, climate), and the specialized TSFMs rather than just off-the-shelf LLMs would substantially strengthen the results.
#Bottom Line
TFRBench opens a new evaluation dimension for time series forecasting systems. The field has spent years optimizing accuracy on standardized benchmarks. TFRBench asks a question the field has not formally answered before: can the system explain its reasoning, and is that explanation correct?
The results are sobering for practitioners hoping to deploy LLM-based forecasting systems as-is. Off-the-shelf LLMs fail systematically at cross-channel constraint reasoning, trend decomposition, and event attribution on TFRBench's domains. But the results are also constructive: the gap between self-generated reasoning (40.2% beat rate) and reasoning-assisted forecasting (56.6% beat rate) identifies a concrete architectural intervention — pre-compute and validate reasoning traces before generating forecasts — that practitioners can implement today.
As TSFMs accumulate richer output capabilities and as LLM integration deepens, the ability to evaluate not just what a model predicts but why it predicts it will shift from a nice-to-have to a deployment requirement. TFRBench establishes a standardized protocol for that evaluation.
Primary sources: TFRBench paper (arXiv:2604.05364), TFRBench project website, GIFT-Eval benchmark.