TSFMs vs World Models: Two Philosophies of Prediction
Yann LeCun's AMI Labs just raised $1B to build world models. DeepMind shipped Genie 3. Researchers are adapting JEPA for time series. Should practitioners care — or is this a different field solving a different problem? Here's a technical comparison of the two prediction paradigms.
Yann LeCun has spent the last two years arguing that next-token prediction is a dead end. In January 2026, he co-founded AMI Labs and raised $1.03 billion to prove it, building what he calls "world models" — AI systems that learn an internal representation of how reality works, then use that representation to predict, plan, and reason. Google DeepMind released Genie 3. Meta shipped V-JEPA 2. NVIDIA launched Cosmos, pretrained on 20 million hours of video.
Meanwhile, time series foundation models are quietly doing what practitioners need: producing calibrated probabilistic forecasts on arbitrary numerical series, zero-shot, in production, at scale. These two research programs are both predicting the future from sequential data. But they disagree — fundamentally — about what prediction requires.
#The Core Split
The disagreement traces back to LeCun's 2022 position paper, "A Path Towards Autonomous Machine Intelligence". Autoregressive models (including TSFMs) predict the next value by maximizing the likelihood of observed data — powerful pattern matching that captures trends and seasonality, but operates entirely in observation space without modeling why patterns occur. World models, following Ha & Schmidhuber (2018), instead learn compressed representations of underlying system state and predict how that state evolves. LeCun's JEPA refines this: predict in abstract latent space rather than pixel or value space, capturing structure rather than surface detail.
For practitioners, this maps to a concrete question: is forecasting about learning statistical patterns from sequences, or about learning causal models of the systems that generate them?
#Architecture: Side by Side
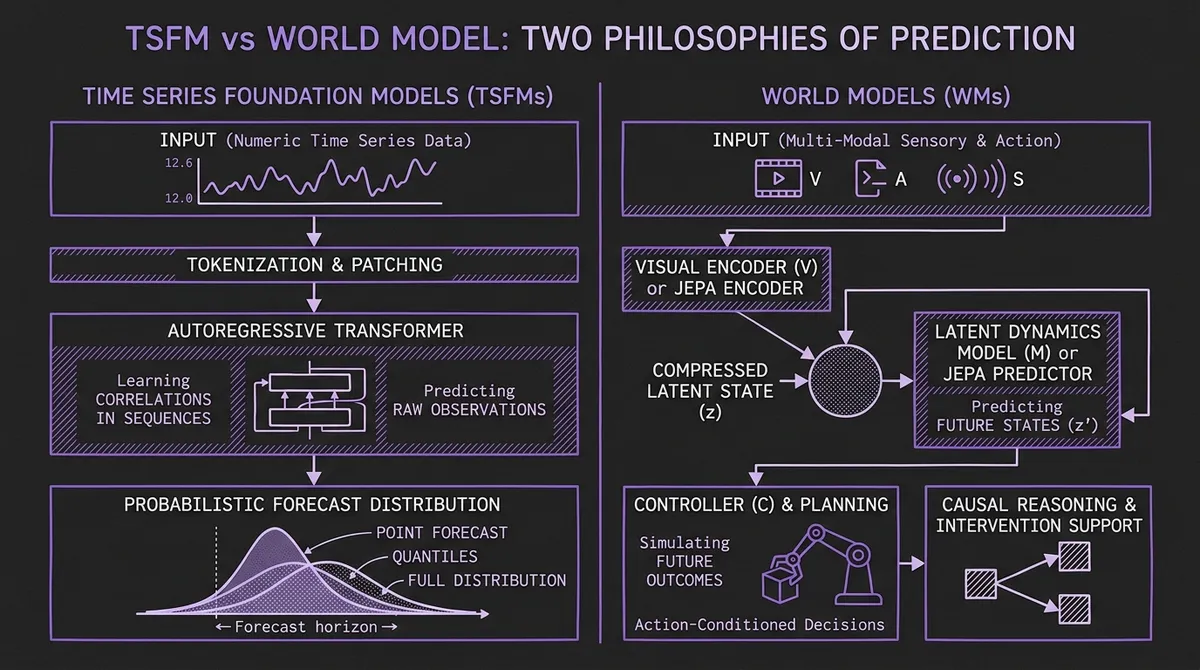
| Dimension | Time Series Foundation Models | World Models |
|---|---|---|
| Input | Numeric time series (univariate/multivariate) | Multi-modal: video, images, sensors, actions |
| Prediction space | Raw values (point forecasts, quantiles, distributions) | Learned latent representations |
| Action-conditioned? | No — purely observational | Yes — "what happens if I do X?" |
| Core architecture | Transformers, SSMs, diffusion | Latent predictors (Genie), JEPA, model-based RL (Dreamer, TD-MPC2) |
| Training data | Billions of real-world time points | Video, embodied interaction logs, simulated environments |
| Inference output | Forecast horizon with uncertainty estimates | Simulated future states enabling planning |
#Where TSFMs Win
For forecasting numerical time series in production, TSFMs have decisive advantages.
Zero-shot generalization. Moirai handles variable frequencies and prediction lengths. Chronos-Bolt achieves sub-100ms latency. No world model offers anything comparable for arbitrary numerical data.
Calibrated uncertainty. TSFMs produce prediction intervals and full distributions. World models predict latent states, not calibrated probabilities over observable values.
Production readiness. Mature serving infrastructure, GPU optimization, benchmark suites. You can call a TSFM through an API today. You cannot do the same with Genie 3.
Efficiency. Granite TTM packs competitive accuracy into ~1M parameters. FlowState tops GIFT-Eval with under 10M. World models are orders of magnitude more expensive.
#Where World Models Offer Something TSFMs Can't
Causal reasoning. TSFMs learn correlations, not causes. World models represent causal structure, enabling counterfactual questions like "what if we raised prices 5%?" Early bridging work — Interventional Time Series Priors and time2time — is trying to add causal intervention to TSFMs, but it remains nascent.
Multi-modal context. TSFMs are beginning to incorporate text, but world models natively consume video, images, text, and actions simultaneously.
Planning. If forecasting serves decision-making — supply chain optimization, robotic control — a model that simulates outcomes of different actions is fundamentally more useful than a passive predictor. This is the bet AMI Labs is making with its $1 billion.
#The Convergence Zone
The most interesting development is not the competition but the convergence. Three JEPA-for-time-series papers have appeared in rapid succession: LaT-PFN (arXiv:2405.10093) combines JEPA with Prior-data Fitted Networks for zero-shot latent-space forecasting; TS-JEPA (arXiv:2509.25449) adapts JEPA for self-supervised time series representation learning with competitive forecasting results; and MTS-JEPA (arXiv:2602.04643) extends this to multi-resolution anomaly prediction.
State-space models are another bridge. SSMs like S4 and Mamba are discretized dynamical systems (dx/dt = Ax + Bu) — the same formalism used in physics-based world models — but deployed for TSFM forecasting tasks. Mamba4Cast achieves zero-shot forecasting at significantly lower cost than transformers.
Weather forecasting provides the clearest proof that these aren't separate problems. DeepMind's GenCast (Nature, 2024) outperforms operational weather ensembles on 97.4% of targets. Google's NeuralGCM (Nature, 2024) — a hybrid world model with a differentiable physics solver — tracks climate accurately for decades. These are world models applied to multivariate time series, already outperforming both physics models and pure TSFMs.
Meanwhile, "A Causal World Model Underlying Next Token Prediction" (ICML 2025) shows that autoregressive transformers implicitly learn causal structures — raising the question of whether TSFMs already contain embryonic world models. No paper has demonstrated this for time series specifically, but the Othello-GPT line of research (replicated across 7 LLMs) suggests the boundary between "pattern matcher" and "world model" may be blurrier than the philosophical framing implies.
#A Practitioner's Framework
Use a TSFM if you need forecasts on numerical time series, calibrated uncertainty, zero-shot generalization, and production-grade latency. This covers the vast majority of workloads.
Watch world models if your problem involves decision-making under multiple interventions, multi-modal data, or causal reasoning about outcomes. Robotics, autonomous systems, and physical simulation are the natural domains.
#What Happens Next
TSFMs remain the right tool for time series forecasting today. But the intellectual pressure from world models — causal reasoning, multi-modal context, intervention-aware prediction — is shaping what the next generation of TSFMs will become. The convergence zone (JEPA for time series, SSMs, causal interventions in TSFM hidden states) is where the most interesting work is happening. The best forecasting models of 2027 will likely borrow from both traditions.
Explore the current generation in our model catalog and 2026 toolkit guide.