TSFM vs LLM Research, Compared
We compared TSFM research against LLM research end-to-end — anchoring TSFM at Oct 2023 against LLM at Oct 2018, pulling publication-volume curves, model-release tempo, theme-by-theme alignment, and the published bibliometric record on both sides. The 5-year offset is real but the comparison is genuinely multi-axis: TSFMs are ahead on model releases and open weights, behind on publication velocity and scaling laws, and missing a ChatGPT-style consumer moment entirely.
The most common LLM-style framing of time-series foundation models right now is "TSFMs are where LLMs were a few years ago." It is a useful shorthand, but it is also under-specified. Which lifecycle position? Measured by what? On which axis? After a week pulling the bibliometric data for both fields, assembling a 96-record LLM model release timeline alongside our 43-record TSFM timeline, and reading the published LLM bibliometric record, we can give a sharper answer: the two fields trace a similar shape but no single axis lines up cleanly. Some axes are ahead; some are behind; some have no LLM analog at all.
This post lays out the comparison. It is a companion to How TSFM Research Evolved — that piece is the standalone TSFM study; this piece adds the LLM dimension.
The LLM side of the comparison is not just our own OpenAlex pull. Four published bibliometric studies frame what we know about LLM research growth, and our numbers are sanity-checked against them: Fan et al. (2024) (ACM TIST, 5,752 publications 2017–2023, identifies 2022 as the pivot), the 17K-paper arXiv trends analysis, the 16,193-paper 2024–2025 update (confirms LLM share of arXiv grew ~8× between 2022 and 2025), and the Stanford HAI 2025 AI Index R&D chapter (149 foundation models in 2023, 90% of notable 2024 models from industry, training compute doubling every five months). Where our absolute counts differ from theirs, we defer to theirs — they used curated venue lists and hand-validation; we used phrase matching against the OpenAlex Works index. The trajectory shape we measure matches what they report.
#Anchoring the comparison
Both fields share a deeper architectural lineage — the 2017 Transformer, masked-language pretraining, the foundation-model framing of Bommasani et al. 2021 — but those primitives existed long before either field had a recognizable model zoo. For a comparison to mean anything, we have to anchor each field at the moment a downloadable, label-able foundation model existed:
- LLM year 0: October 2018. BERT was the first pretrained language model that became the field's primary research object; RoBERTa, XLNet, T5, and BART were all published against it within a year.
- TSFM year 0: October 2023. TimeGPT-1, Lag-Llama, and the TimesFM paper landed within ten days of one another — the start of the Cambrian months.
That anchoring gives a 5-year offset between the two fields, against which everything else can be measured. TSFM's current calendar (May 21, 2026) corresponds to +31 months from year 0, which on the LLM clock is May 2021 — before Codex, well before ChatGPT, in the "scale is the answer" phase but pre-consumer-breakthrough.
#The publication curve
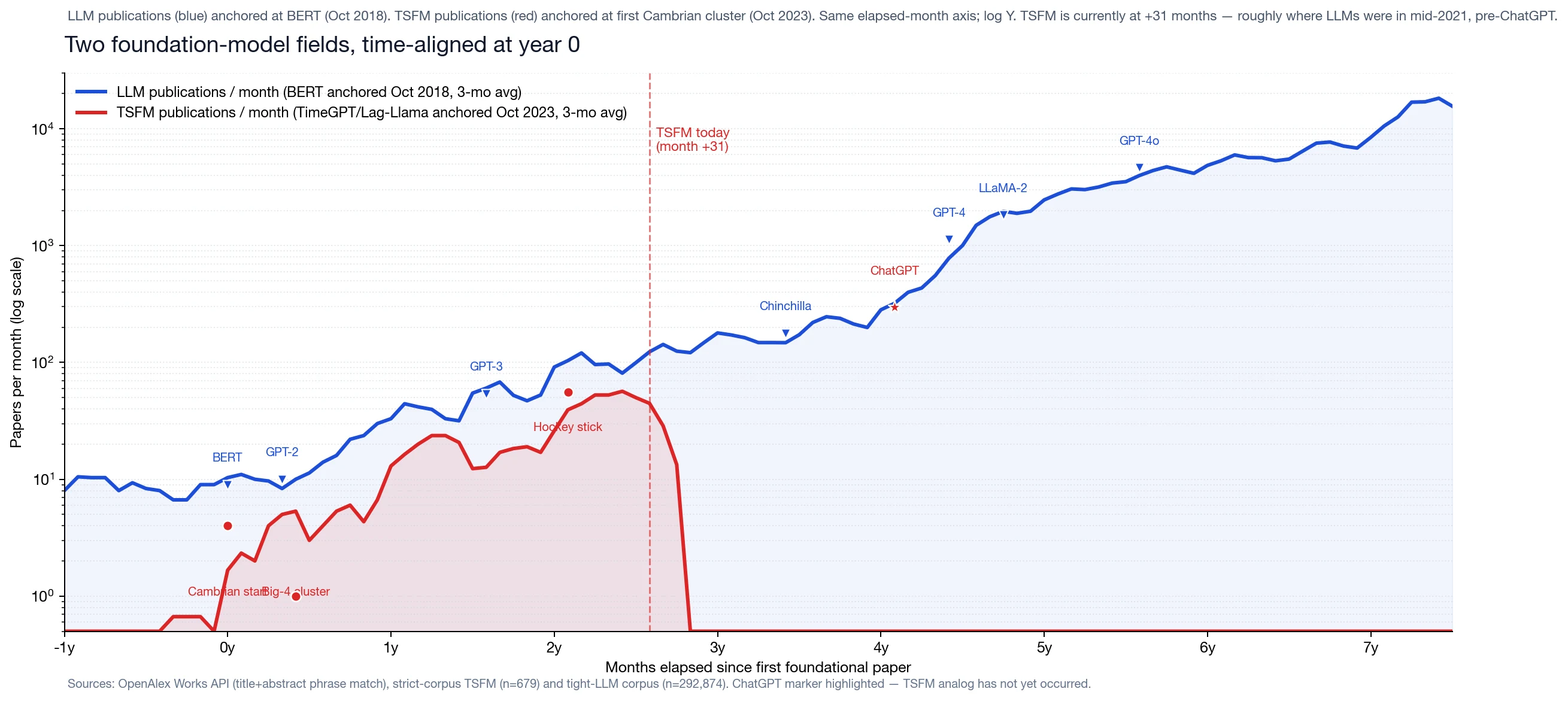
Time-aligned, the two publication curves track each other closely in the first three years — both fields ramp from near-zero to ~100 papers/month by month +24, then accelerate. Yearly cumulative comparison:
| Years since anchor | LLM (Oct 2018+) | TSFM (Oct 2023+) | Ratio |
|---|---|---|---|
| +0 (year of anchor) | 141 | 10 | 14× |
| +1 | 401 | 112 | 3.6× |
| +2 | 1,163 | 297 | 3.9× |
| +3 (partial — TSFM YTD) | 2,260 | 256 (~660 annualized) | 3.4× |
The ratio is converging. LLMs had roughly 14× the publication volume in year 0; by year +3 they had only 3-4× the volume. TSFMs are catching up in relative terms — they had a slower start, but the slope of their curve in years 1–3 closely matches LLMs in their years 1–3.
This understates the gap, though, because the LLM curve had ChatGPT at month +49 — a moment that multiplied the publication rate by ~7× within a year (4,021 papers in 2022 to 27,444 in 2023). TSFMs are at month +31, which on the LLM clock is mid-2021 — they have not yet reached the LLM analog of ChatGPT, and the question of whether they will is genuinely open. The single biggest disanalogy in our comparison is that there is no obvious universal-interface artifact for time-series forecasting. We come back to this at the end.
#The model release tempo
The publication curve is one axis. The model release tempo is a different one, and the data flips the conclusion.
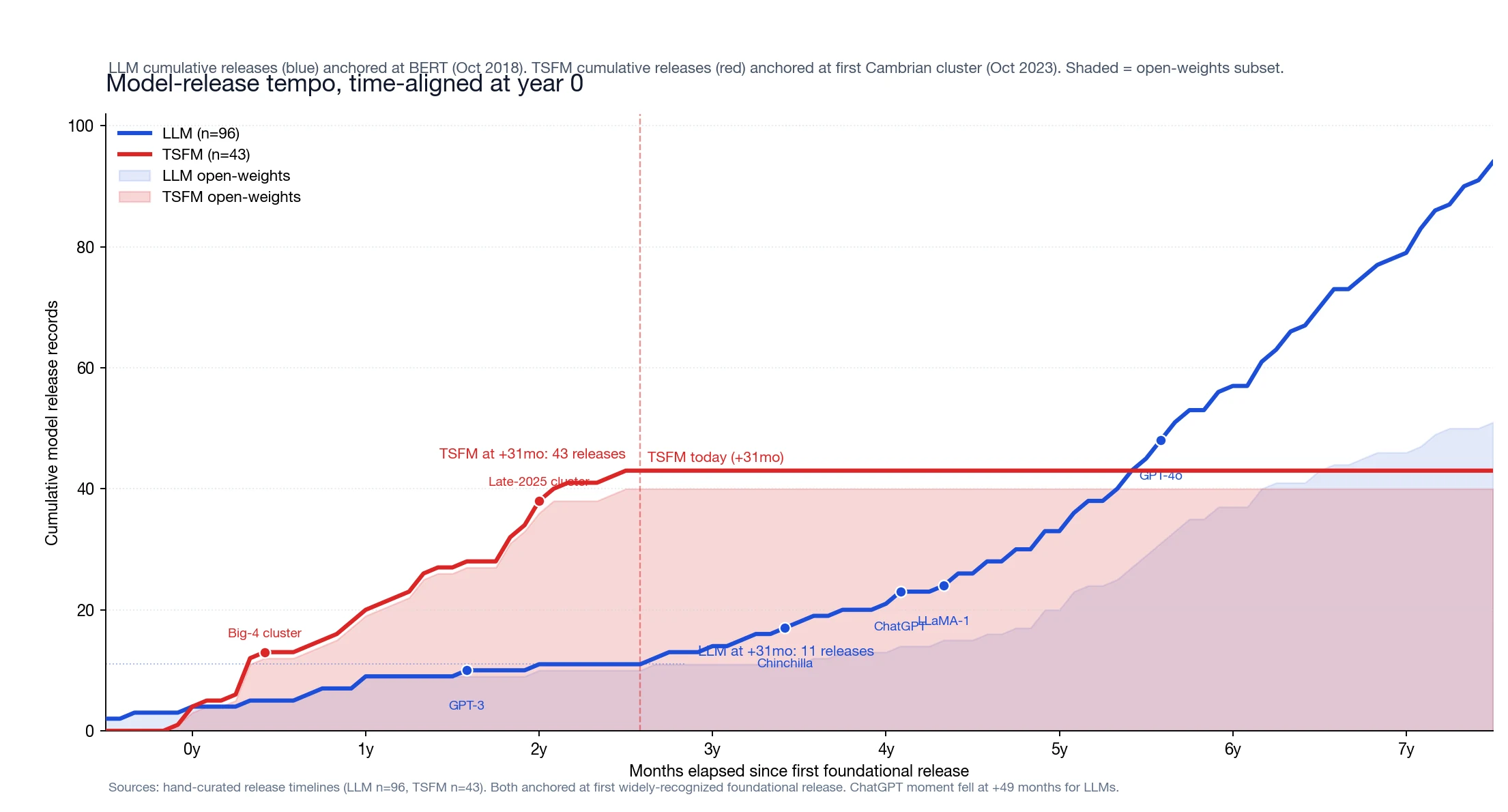
At +31 months from year 0:
- LLM had 11 model releases (BERT, GPT-2, RoBERTa, XLNet, T5, BART, GPT-3, mT5, MT-NLG, Gopher, Codex).
- TSFM has 43 release records (counting checkpoint variants and major version bumps within families — Moirai 1.0/1.1/MoE/2.0, Chronos/Bolt/2, TimesFM 1.0/1.0-200m/2.0/2.5).
TSFMs are running ~4× ahead of the LLM trajectory on model releases. The LLM curve only catches up around month +60, after ChatGPT triggered the open-weights wave. Two reasons compound: TSFMs inherited the pretrained-transformer infrastructure (HuggingFace, sharding, mixed-precision, FlashAttention) that LLMs had to invent over years, and TSFM families ship many sizes at once — Toto 2.0 at five sizes, Xihe HIBA at five, Chronos at five — each counted as one release.
But the same data reveals a reciprocal weakness:
| Metric | LLM (at +31 months) | TSFM (at +31 months) |
|---|---|---|
| Cumulative papers | 2,795 | 671 |
| Cumulative model releases | 11 | 43 |
| Papers per model | 254 | 16 |
LLMs averaged 254 papers per model at the same lifecycle position. TSFMs average 16. The TSFM community is model-dense and reader-sparse — partly because the field is younger, partly because individual TSFMs are less differentiated than the 2018–2020 LLMs were (most current TSFMs are variants on the same patched-transformer template, so a follow-on paper comparing against one is implicitly comparing against several).
#Theme by theme — what's the same, what's behind, what's missing
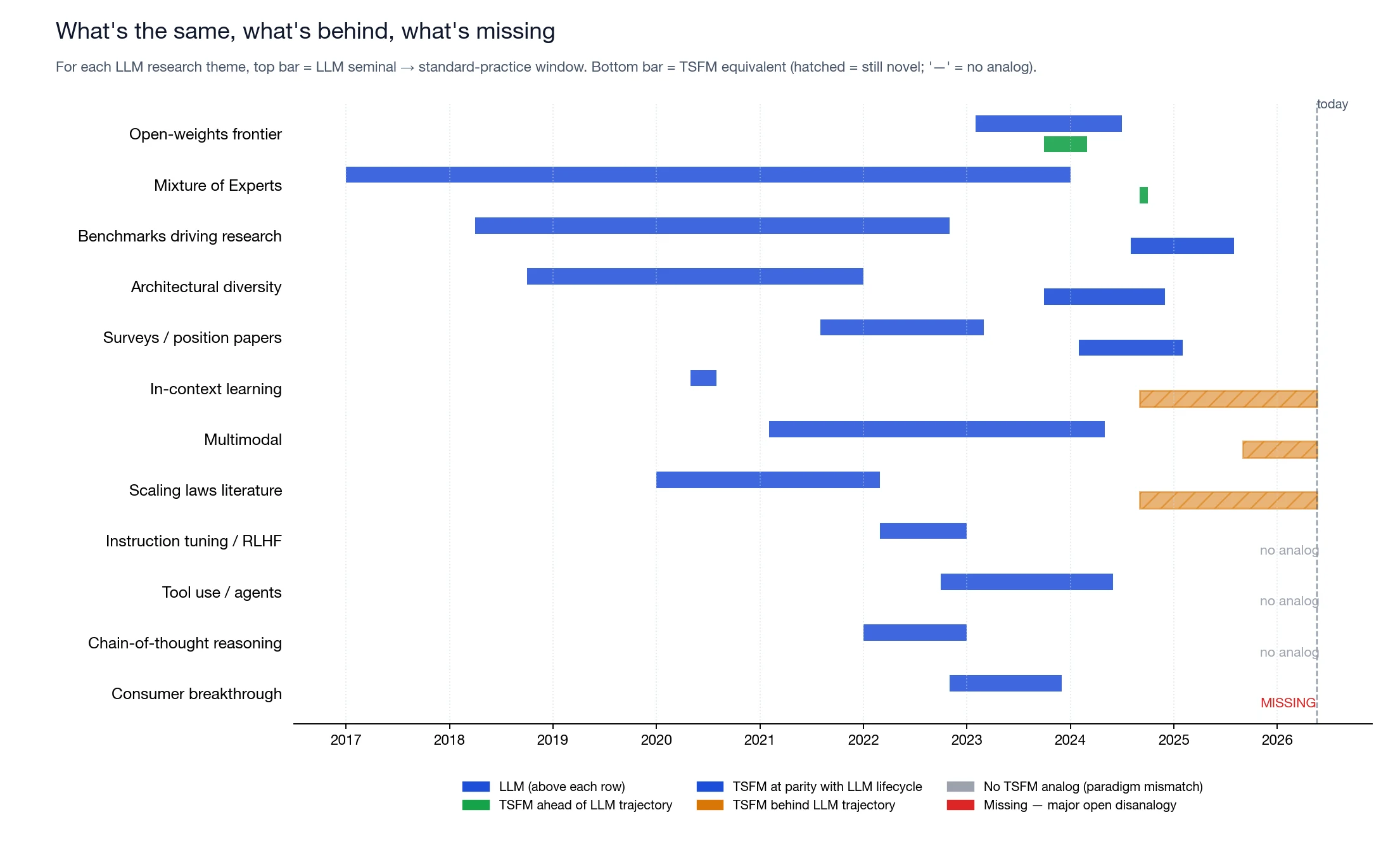
The aggregate curves are useful but they obscure the texture of the comparison. We mapped twelve LLM research themes (drawn from a careful read of the LLM bibliometric and methodological literature — full citations in the supplementary data) and identified where TSFMs sit on each one.
#TSFM ahead of the LLM trajectory
Open-weights frontier. LLMs took roughly four years to reach competitive open weights — LLaMA-1 (Feb 2023) was the first widely useful open model, and LLaMA 3.1 (Jul 2024) was the first to be benchmark-competitive with frontier closed models. TSFMs were born open: Lag-Llama, Moirai, MOMENT, TimesFM, Chronos all shipped weights from day one. Of 43 TSFM release records, only 3 are closed-API (the Nixtla TimeGPT line); among LLMs in 2025 alone, 16 of 25 flagship releases are closed-API.
Mixture of Experts. Sparse-gated MoE was first published by Shazeer et al. in 2017. It took LLMs about seven years to put MoE into a flagship open model (Mixtral 8x7B, Dec 2023 / Jan 2024). The TSFM analog appeared inside six months of the field forming: Time-MoE in Sep 2024 and Moirai-MoE in Oct 2024. The infrastructure (sharded MoE training, all-to-all kernels, expert parallelism) was already a solved problem by the time TSFMs needed it.
#At parity
Three themes look roughly the same shape in both fields. Benchmarks became the load-bearing object — BIG-bench and HELM for LLMs in 2022, GIFT-Eval/FEV-Bench/BOOM for TSFMs in 2024–2025 (both ~4 years post anchor). Architectural diversity cycled the same way: LLMs went encoder/decoder/seq-to-seq/MoE over three years; TSFMs covered decoder, patched encoder, MoE, diffusion, SSM, and vision-as-TS within two. Surveys and position papers in both fields landed 12–18 months after the first model cluster stabilized.
#Behind the LLM trajectory
In-context learning. LLMs got it with GPT-3 in May 2020 and adopted it within months. TSFMs reached the milestone with TimesFM ICFT (Sep 2024) and Sundial (Feb 2025), but most still require a forecast call rather than a few-shot prompt — ~2 years behind.
Multimodal. CLIP was Feb 2021; multimodality was table stakes for LLM flagships by GPT-4o (May 2024). The TSFM analog is Aurora (Sep 2025) — early but moving fast. ~1–2 years behind.
Scaling laws. Kaplan 2020 and Chinchilla 2022 gave LLMs a clean scaling-laws literature by year +3.5. TSFMs got the first clean per-size CRPS-rank tables from Toto 2.0 and Xihe in May 2026, at month +31. ~1 year behind — but closing fast, and we expect a substantial TSFM scaling-laws literature in 2026–2027.
#No TSFM analog
InstructGPT made RLHF default for LLMs by 2023; TSFMs don't take natural-language prompts, so there's no preference signal to optimize. ReAct/Toolformer turned tool-use into a recognized subfield by 2024; TSFMs are called by agents, not framed as agents themselves. Chain-of-thought reasoning doesn't apply — time series doesn't decompose into reasoning steps.
#Missing — the major open disanalogy
Consumer breakthrough (ChatGPT). This is the single biggest unknown. ChatGPT hit at LLM month +49 and multiplied the field's publication rate by 7× in the following year. There is no obvious universal-interface artifact for time-series forecasting. The closest candidates are conversational forecasting APIs (TimeGPT's API is the early example), but a true ChatGPT-equivalent — a product that makes time-series forecasting feel intuitive to non-specialists at scale — does not yet exist. Whether it will is the field's most important open product question, and the answer is unknowable from publication data.
If TSFMs do get a consumer-breakthrough analog, the publication trajectory predicts an inflection around 2027 — that's TSFM month +49, the LLM-equivalent ChatGPT timing. If they don't, the curves diverge: LLMs hockey-sticked after consumer adoption pulled in adjacent research; TSFMs without that catalyst would continue their current slope but never reach LLM-scale publication volume.
#What this implies for the next 12–24 months
If the LLM trajectory is even approximately predictive of TSFMs, three things follow:
-
Scaling-laws literature explodes by mid-2027. The Kaplan → Chinchilla → Beyond-Chinchilla LLM lineage took roughly 24 months. TSFMs are at the equivalent of "Kaplan just landed." Expect a Chinchilla-equivalent paper from one of the major TSFM labs by Q2–Q4 2027.
-
Multimodal TSFMs become the new flagship default. Aurora is the early example; expect every late-2026 / 2027 TSFM family to ship a multimodal variant by default. The vision-as-time-series and text-conditioned-forecasting branches converge.
-
A consumer or operational interface attempt is the open question. The next 24 months will either produce a ChatGPT-shaped breakthrough (a universal forecasting product that makes the category obvious to non-specialists) or they won't. If they don't, the publication curve continues on its current slope — high quality, smaller community, slower compounding — but stays well below LLM-scale velocity.
#Caveats and disanalogies
Five things this comparison does not establish:
- The 5-year offset is not destiny. Different fields move at different speeds for structural reasons (compute economics, data availability, application demand). Anchoring at "field-formation moment" is a useful narrative device, not a forecast.
- Model release count and paper count measure different things. TSFMs lead on releases, lag on papers, and the papers-per-model ratio is the right derived metric. We're not claiming any single metric tells the whole story.
- Heuristic classification has not been validated. As in the underlying TSFM publication study, we did not formally audit our category labels. The trend shapes are likely robust to noise; specific counts are approximate.
- The LLM corpus uses unambiguous phrases. We used a tight phrase set ("large language model", "ChatGPT", "GPT-3/4", "InstructGPT", etc.) and the
title_and_abstract.searchfilter to keep noise down. The candidate set is still BM25-ranked and includes some marginal matches; the curve shape is right but absolute counts should be treated as approximate. - Time-series-specific application domains add a layer. Energy forecasting, observability, finance, healthcare, and supply-chain operations each have their own publication cycles. Aggregate TSFM volume is the sum of these — a domain that has not yet absorbed TSFMs (e.g., legal time-series, parts of healthcare) could add a step-function in publication volume even without a ChatGPT-style consumer breakthrough.
#Reproducibility
Supporting data files alongside this post:
llm_monthly_tight.json (monthly LLM counts 2017–2026),
llm_models.json (96 LLM release records),
llm_themes.md (11-theme analysis with seminal→standard windows + lag table),
llm_citations.json (41 key LLM papers, machine-readable).
TSFM-side data lives in the companion study's data folder.
The single number to remember: TSFM is at LLM-month +31. By that clock, ChatGPT is eighteen months in the TSFM future analog — Q4 2027. Whether that future happens is the field's most important open question.
Citations: arXiv:1810.04805 (BERT), arXiv:2005.14165 (GPT-3), arXiv:2001.08361 (Kaplan scaling laws), arXiv:2203.15556 (Chinchilla), arXiv:2203.02155 (InstructGPT), arXiv:2103.00020 (CLIP), arXiv:2206.07682 (Emergent abilities), arXiv:2304.02020 (LLM bibliometric review). Data source: OpenAlex Works API + hand-curated release timelines. Analysis date: 2026-05-22.