How TSFM Research Evolved: A Data-Driven Look at 2021–2026
679 papers, 43 release records, five years. We pulled the publication record from OpenAlex and assembled the model release record from primary sources to trace how the time-series foundation model field actually evolved — month by month, model by model.
For most of the time series foundation model era, the field has been described in superlatives. "Exploding." "Cambrian." "Hockey stick." Those words feel right to anyone reading TSFM papers in 2026, but they are not measurements. This post replaces them with measurements.
We built a strict phrase- and alias-matched corpus of TSFM-relevant papers from OpenAlex covering May 2021 through May 21, 2026 — 679 papers after local post-filtering against an explicit inclusion-rule set, 360 of them arXiv-indexed. We assembled, from primary sources, 43 release records spanning that same window — counting paper releases, weight checkpoints, and major version bumps within model families. The result, charted four ways below, traces how the field actually evolved: from "nothing to read" to a single ten-week stretch in early 2024 that defined the modern model zoo, through eighteen months of follow-on work, to a hockey stick that is still climbing as of May 2026.
#The headline numbers
| Year | All venues | arXiv-indexed |
|---|---|---|
| 2021 | 3 | 2 |
| 2022 | 1 | 1 |
| 2023 | 10 | 8 |
| 2024 | 112 | 62 |
| 2025 | 297 | 135 |
| 2026 (Jan–May 21) | 256 | 152 |
Peak month: January 2026 with 66 papers. Three-month trailing average as of May 2026: ~45 papers per month, and still climbing.
(How we built the corpus: broad search across OpenAlex Works for TSFM phrases and model-name aliases, then a strict local post-filter requiring literal phrase membership in title or reconstructed abstract. Full inclusion rules, alias list, and known coverage gaps are in methodology.md and aliases.json alongside the raw chart data.)
#Era 0: Antecedents (2017 → 2022)
The TSFM era does not start in the publication record above. It starts in the architectural and pretraining lineage the field built up over the six years preceding it. Four pieces had to exist independently before they could be combined:
- The Transformer (2017). Attention Is All You Need (Vaswani et al., arXiv:1706.03762). Every TSFM in our timeline uses some variant of this architecture as its backbone.
- The pretraining paradigm (2018). BERT (Devlin et al., arXiv:1810.04805) established "pretrain on a large corpus, then transfer or zero-shot" as the dominant training pattern in modern ML.
- Time-series transformers (2020 → 2022). Informer (arXiv:2012.07436), Autoformer (arXiv:2106.13008), and FEDformer brought Transformer attention to long-horizon forecasting. TS2Vec (2022) and PatchTST (arXiv:2211.14730) explored masked/contrastive pretraining objectives, but always on a single dataset — they did not yet attempt the "trained on diverse time-series, evaluate zero-shot" move that defines a foundation model.
- The foundation-model concept (2021). On the Opportunities and Risks of Foundation Models (Bommasani et al., arXiv:2108.07258) — the Stanford CRFM paper that gave the field the term. TSFM inherits this framing wholesale.
By late 2022, the three technical ingredients (architecture, pretraining objective, single-domain time-series transformer) and the conceptual framing (foundation models) existed independently. Nobody had yet shipped a single set of weights pretrained on large, diverse time-series data and released it for download. That gap closed in late 2023, and our 679-paper corpus picks up the trail when it does.
For the architectural side of how that has played out since — what scaling looks like across the model families that emerged from this lineage — see our TSFM scaling laws synthesis.
#Era 1: The vocabulary appears (2021 → mid-2023)
For two and a half years, our corpus returns almost nothing per month — just a handful of precursors: Self-Supervised Pre-training for Time Series Classification (July 2021), Pre-training Enhanced Spatial-Temporal Graph Neural Network (August 2022), SimMTM (February 2023). The TSFM vocabulary exists; the released artifact does not. Through mid-2023, anyone wanting to "use a foundation model for time series" was reading methods papers and reimplementing pretraining objectives from scratch.
#Era 2: The Cambrian Months (September 2023 → March 2024)
Over a six-month window, the field's basic ontology was assembled. Ten release records — four from academic labs, six from major industry research orgs — shipped within twenty-four weeks. Where paper and weights/announcement dates differ, the bullets list the basis explicitly:
- 2023-09-13 — EarthPT: a time series foundation model for Earth Observation (arXiv:2309.07207). First paper in our dataset to use "time series foundation model" in the modern sense.
- 2023-10-05 — Nixtla's TimeGPT-1 paper (arXiv:2310.03589). Closed-weights, API-only.
- 2023-10-12 — Lag-Llama: Towards Foundation Models for Probabilistic Time Series Forecasting (arXiv:2310.08278). First open-weights probabilistic TSFM. See our Lag-Llama deep dive.
- 2023-10-14 — Google's A decoder-only foundation model for time-series forecasting paper (arXiv:2310.10688) — the TimesFM paper release. Google's public blog announcement and the initial 200m weights checkpoint followed on 2024-02-02 and 2024-02-12 respectively.
- 2024-01-08 — IBM's Tiny Time Mixers (TTM-r1) on Hugging Face. See our tiny-models writeup.
- 2024-02-04 — Salesforce's Moirai family paper (arXiv:2402.02592) and CC-BY-NC-4.0 weights.
- 2024-02-04 — Tsinghua's Timer, a generative pretrained transformer.
- 2024-02-06 — CMU's MOMENT (arXiv:2402.03885).
- 2024-02-29 — Harvard/MIT's UniTS.
- 2024-03-12 — Amazon's Chronos paper (arXiv:2403.07815).
In the publication record this is one connected event. October 2023 yields four papers (EarthPT, TimeGPT-1, Lag-Llama, the TimesFM paper); October–November six. The February–March 2024 cluster lands six further releases — paper, weights, or both — inside eight weeks. By April 2024, "a time series foundation model" has become a noun the field uses without qualification, and monthly publication count crosses ten for the first time.
#The model timeline, end to end
Stepping back to the full 33-month release record, the Cambrian months are the start of an arc that has not yet flattened:
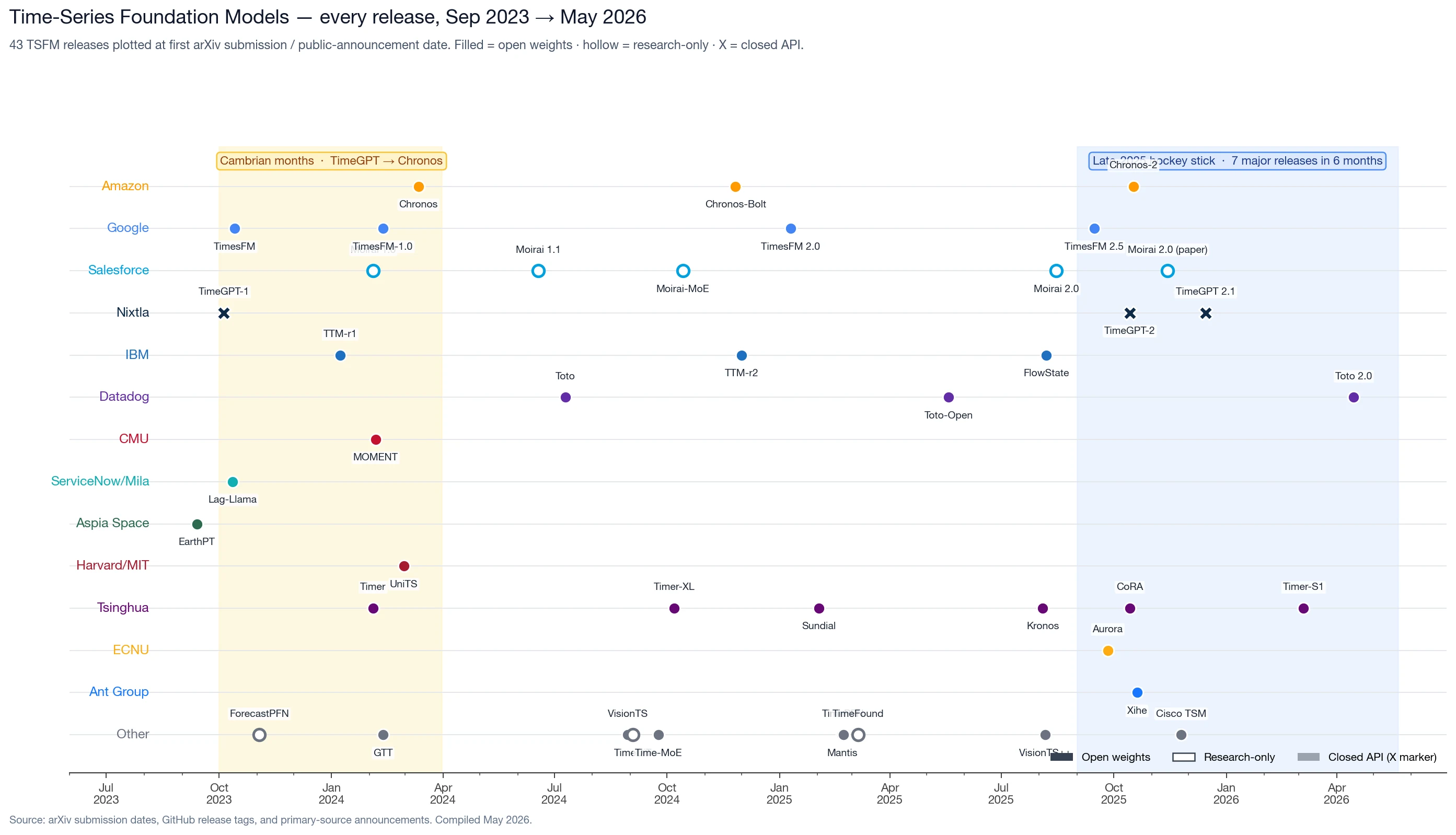
A few patterns that the timeline makes visible but a list of releases would not:
Open and research-available weights dominate follow-on work. Of the 43 release records, 32 are open-weights, 8 are research-only or non-commercial (Salesforce's Moirai family ships under CC-BY-NC-4.0 and is the dominant case), and 3 are closed-API (the Nixtla TimeGPT line). Closed-API models still draw substantial attention — TimeGPT is the third-most-mentioned model in our corpus, ahead of every weights-available model except TimesFM and Chronos — but mentions of TimeGPT concentrate in benchmark and application papers, where the API is consumed, and are notably absent from adaptation and fine-tuning papers, where weights are required. The adapter, fine-tuning, and checkpoint ecosystem is concentrated around models with downloadable weights.
Family lineages dominate by 2025. The largest single-family release lines are: Tsinghua THUML's six-model arc (Timer → Timer-XL → Sundial → Kronos → CoRA → Timer-S1), Salesforce's five-release Moirai arc (1.0 → 1.1 → Moirai-MoE → 2.0 weights → 2.0 paper), Google's four-release TimesFM arc (1.0 paper → 1.0-200m → 2.0-500m → 2.5-200m, the last one deliberately smaller), and tied trios at Amazon (Chronos → Bolt → 2), Nixtla (TimeGPT-1 → 2 → 2.1), Datadog (Toto → Open → 2.0), and IBM (TTM-r1 → r2 → FlowState). The single-model releases from 2023 have largely become the multi-checkpoint families of 2025.
Late-2025 was a unique cluster. Between September and December 2025, seven major model families released either a new generation or a flagship variant: TimesFM 2.5, Aurora, Moirai 2.0, CoRA, TimeGPT-2, Chronos-2, and Xihe. That had not happened before in the field's history.
#Era 3: Scale-Up (mid-2024 → Q3 2025)
For the fifteen months following the Cambrian cluster, monthly publication count climbed steadily but unevenly: 5 in May 2024, 12 in September, 24 in October, 23 in December. 2025 opened with a 35-paper January, dropped into the teens for Q2, and settled around 20–25/month through Q3.
The content shifted from "introducing a TSFM" to:
- Follow-on variants: Chronos-Bolt, Moirai-MoE, TimesFM 2.0, Granite TTM r2
- Benchmarks: GIFT-Eval, FEV-Bench, BOOM, Time-Bench, ARFBench
- Adaptation methods: LoRA / PEFT, CoRA, in-context fine-tuning, reprogramming
- New architectures: diffusion, mixture-of-experts, SSM-based, vision-as-time-series
- New families: Datadog's Toto → Toto-Open-Base; Tsinghua's Sundial; Bilkent's TimePFN; UIUC's TimeFound
This is the "normal science" phase: the basic toolbox is fixed, the open questions are concrete, and the publication rhythm aligns with the NeurIPS, ICML, and ICLR submission calendars. It is also when the kind of paper being written changed materially.
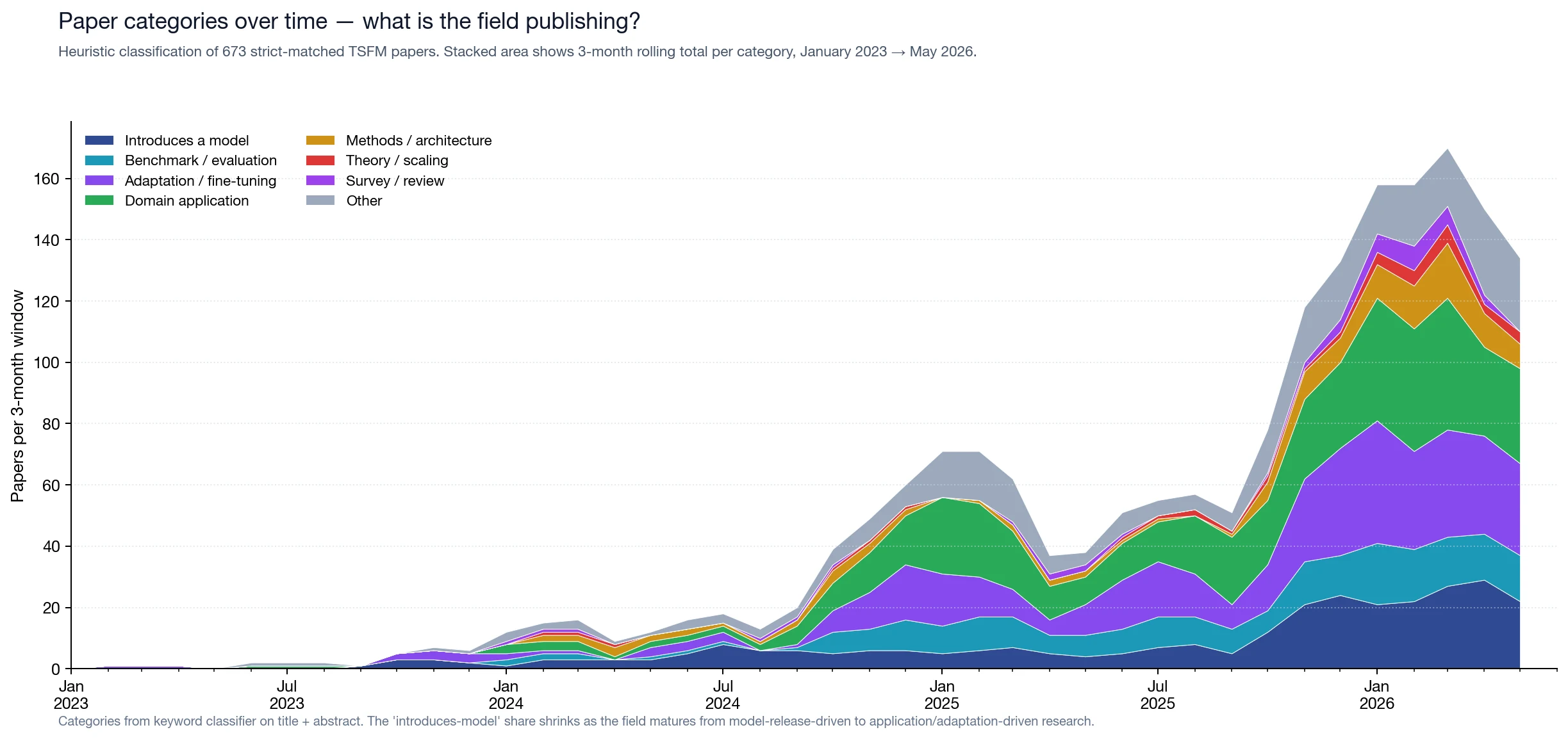
#What the field is publishing — and how that has changed
We tagged each of the 679 papers heuristically by category. The shift in mix is the cleanest signal of how the field has matured:
| Category | Papers | Share |
|---|---|---|
| Domain application | 170 | 25% |
| Adaptation / fine-tuning | 146 | 22% |
| Introduces a model | 104 | 15% |
| Benchmark / evaluation | 83 | 12% |
| Methods / architecture | 43 | 6% |
| Survey / review | 16 | 2% |
| Theory / scaling | 14 | 2% |
| Other | 103 | 15% |
Through 2023 and the first half of 2024, "introduces a model" was the single largest category — when the artifact set is small, every new paper is a new artifact. By the second half of 2024, application and adaptation had each overtaken model-introduction in absolute terms. By early 2026 the introduction share is below 15%, even as the field still ships 5–10 new model variants per month in absolute terms.
Two observations worth pulling out:
The shift to applications signals maturity, not stagnation. When a paper applying Chronos to clinical glucose forecasting becomes possible without explaining what Chronos is, the model is no longer the story — the use case is. Application is now the fastest-growing band, accounting for a quarter of all 2024–2026 work in our set.
Theory and scaling laws remain a tiny share — under 3%. This is genuinely surprising. The LLM field had a substantial scaling-laws literature within 24 months of GPT-2. TSFMs are reaching that milestone only now: Toto 2.0 and Xihe are among the clearest early examples of per-size TSFM scaling evidence on real benchmarks, but a fully developed scaling-laws literature is still missing. We expect this band to grow meaningfully in late 2026 and 2027.
#Era 4: The Hockey Stick (Q4 2025 → Q2 2026)
October 2025 lands 41 papers. November jumps to 56. December takes the only breath in the curve at 36. January 2026 sets the monthly record at 66, February holds at 56, March 48, April 46, and May (partial through the 21st) at 40 — running about even with prior months on a daily basis.
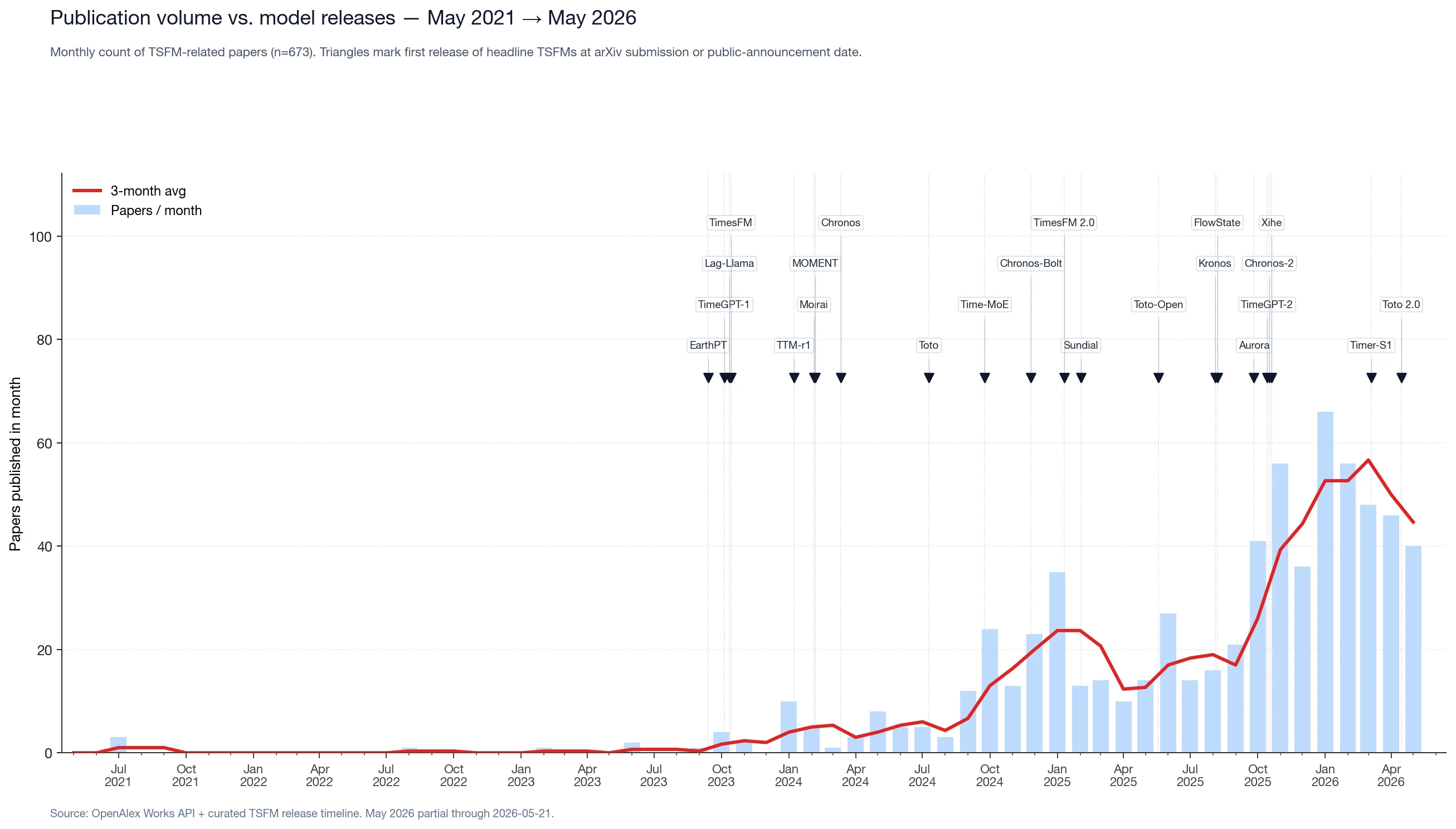
Several drivers compound in this window. Some are visible in the data; some require external knowledge:
- ICLR 2026's submission and acceptance cycle. Our ICLR 2026 TSFM roundup tabulates the time-series cohort at ICLR 2026 based on a title- and abstract-level review of the OpenReview-listed acceptance set; many of those preprints landed on arXiv in October–November 2025.
- The TSALM workshop circuit. ICLR 2026 hosted the first dedicated Time Series in the Age of Large Models workshop on 2026-04-26, drawing submissions that previously had no natural venue.
- Late-2025 scaling families. Toto 2.0, Xihe HIBA, and Timer-S1 each shipped multiple model sizes, which produces multiple companion papers per release.
- Adjacent fields catching up. Causal inference, anomaly detection, observability, and earth-system modeling have each absorbed TSFMs as a tool in the past twelve months. See Aurora for the multimodal extension.
A mechanical extrapolation of the January 1–May 21 daily rate gives roughly 660 TSFM-related papers in calendar 2026 — more than 2024 and 2025 combined. Because the early-2026 rate is shaped by ICLR submission windows, arXiv-cross-listing patterns, and OpenAlex indexing cycles, this is a scenario, not a forecast.
The model-marker overlay also shows that publication response to a release is not automatic. Some releases (EarthPT in Sep 2023, Toto-Open in May 2025) had no immediate follow-on surge; others (TimeGPT and Lag-Llama in Oct 2023, the Feb–Mar 2024 cluster) produced sustained ramps. The pattern lines up directionally with weights status — releases with downloadable weights show larger and longer follow-on waves than closed-API ones — but the n is small and the ICLR/ICML calendar is a confounder.
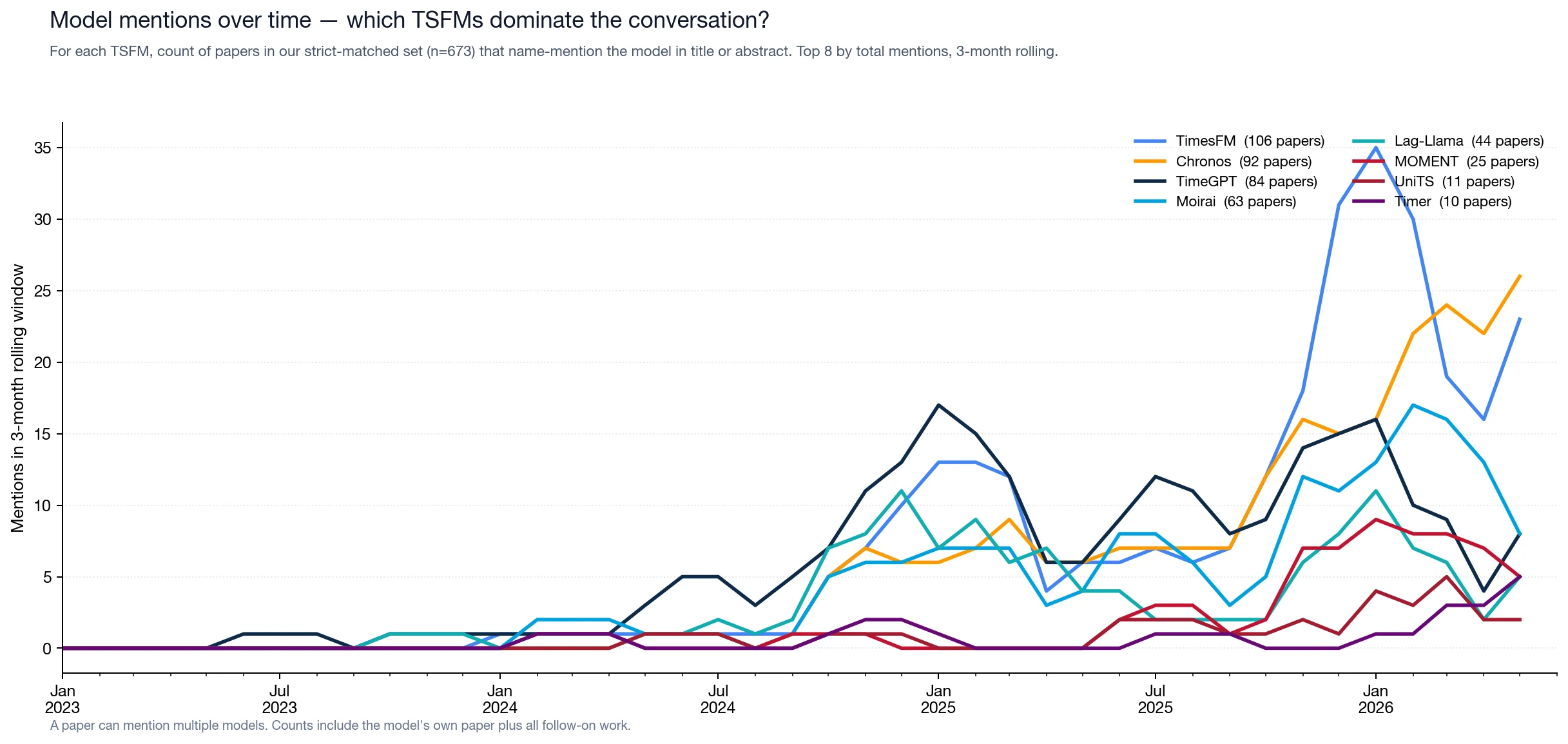
#Which models actually drive the conversation
For each TSFM in our timeline, we counted papers that mention the model by name (or canonical alias) in title or abstract.
| Rank | Model | Mentions |
|---|---|---|
| 1 | TimesFM | 104 |
| 2 | Chronos | 91 |
| 3 | TimeGPT | 84 |
| 4 | Moirai | 63 |
| 5 | Lag-Llama | 44 |
| 6 | MOMENT | 25 |
| 7 | UniTS | 11 |
| 8 | Timer | 10 |
| 9 | Time-MoE | 8 |
| 10 | Sundial | 7 |
The Big Four — TimesFM, Chronos, TimeGPT, Moirai — each appear in roughly 9–15% of our corpus. Anyone evaluating TSFMs against external work, fine-tuning a TSFM for a new domain, or proposing a competing model is comparing against this set. Lag-Llama and MOMENT sit in a clear second tier at 4–6% each.
A few quieter observations:
Late-2025 entrants do not yet have follow-on mass. Xihe, Chronos-2, Aurora, and TimeGPT-2 are not yet in the rankings — eight months since release is too short for substantial citation accrual. We expect Chronos-2 and Aurora to climb fast through 2026; Xihe will compete directly with Toto on the scaling claim and may take longer to differentiate.
Datadog's Toto is mentioned only 6 times in our 679-paper corpus, despite three released versions. This is a known artifact of our search: Toto's observability framing means many follow-on papers do not use canonical TSFM phrases, and "Toto" is not in our candidate query (only the post-filter). As Toto 2.0's benchmark numbers (BOOM, GIFT-Eval) accumulate, we expect this to self-correct.
#What this evolution implies
Three things follow from the data.
The model menu has stopped growing in kind, but not in quantity. Every TSFM family released in 2025 and 2026 fits within the architectural patterns that existed by April 2024: decoder-only transformer, patched encoder, MoE, MLP-Mixer, SSM, diffusion, or vision-as-time-series. What changes is scale, training recipe, multivariate handling, and adaptation surface area — and these are exactly the dimensions our TSFM scaling-laws synthesis digs into. Picking a single TSFM and committing for the next 24 months is no longer obvious — and it was obvious in early 2024.
Benchmarks now matter more than model announcements. When five papers a week introduce a variant or adapter, the right level of abstraction is the family or the trend, not the artifact. Benchmark releases compress hundreds of model claims into a small number of comparable numbers. A new model that omits GIFT-Eval, FEV-Bench, BOOM, QuitoBench, or Impermanent is harder to compare and easier to discount.
Citation mass accumulates slowly. TimeGPT, Chronos, TimesFM, and Moirai together earned the bulk of their mention mass during 2024 and 2025. The 2025–2026 entrants will likely take 12–18 months to enter the citation mainstream regardless of merit. Whether the same lag applies to production deployments is a separate question — one we cannot answer from publication data; it would need download counts, package telemetry, or customer surveys.
#Caveats and data
A few important limits before treating any of this as definitive:
- The corpus is a phrase- and alias-matched subset, not a census. A paper introducing a TSFM under a name we did not anticipate, in an abstract that does not use any of our search phrases, is missed. Coverage is strong for 2024 onwards and weaker for 2021–2022.
- OpenAlex indexes new arXiv submissions and conference proceedings with a 2–8 week lag. May 2026's partial count will rise; ICLR 2026 proceedings finish indexing around late June and we expect the 2026 numbers to revise upward by an estimated 30–50 papers.
- The category classifier is heuristic and not formally validated. Specific category counts are approximate; the trend shapes are likely robust to classifier noise but we have not proven that. A classifier audit is the top methodology priority for the next iteration.
- "Release record" is not "distinct model." The 43 release records count version increments, checkpoint variants, and major successors separately. The count of distinct foundation-model families is closer to 20.
- Paper count is not field health. Monthly volume reflects effort and attention, not quality, novelty, or downstream usefulness. Our benchmarking-challenges post covers the related concern.
The full inclusion rules, alias list, classification rules, and known coverage gaps are in methodology.md and aliases.json. Raw chart data: v3_counts.json, models.json, model_mentions.json, classifications_v2.json. This snapshot is dated 2026-05-21; we will refresh after ICLR proceedings finish indexing.
Citations: arXiv:2309.07207 (EarthPT), arXiv:2310.03589 (TimeGPT-1), arXiv:2310.08278 (Lag-Llama), arXiv:2310.10688 (TimesFM), arXiv:2402.02592 (Moirai), arXiv:2402.03885 (MOMENT), arXiv:2403.07815 (Chronos). Data source: OpenAlex Works API. Analysis date: 2026-05-21.