Xihe: A Scaling Family Built Around Hierarchical Interleaved Block Attention
Xihe is a five-checkpoint TSFM family (9.5M → 1.5B parameters) built around Hierarchical Interleaved Block Attention (HIBA), a sparse multi-scale attention layout that alternates intra-block and inter-block attention at hierarchical block sizes. The paper reports new top-of-leaderboard zero-shot numbers on GIFT-Eval and a smallest-model line that already beats many incumbents.
For most of the time series foundation model era, the default attention layout has been inherited from language modeling: a stack of dense self-attention layers, sometimes with patching at the input, and a single attention budget that has to capture everything from the last few timesteps to multi-month structure. That layout has been good enough to win benchmarks. It has also been hiding the fact that the right amount of attention at each temporal scale is wildly different from the right amount at every other.
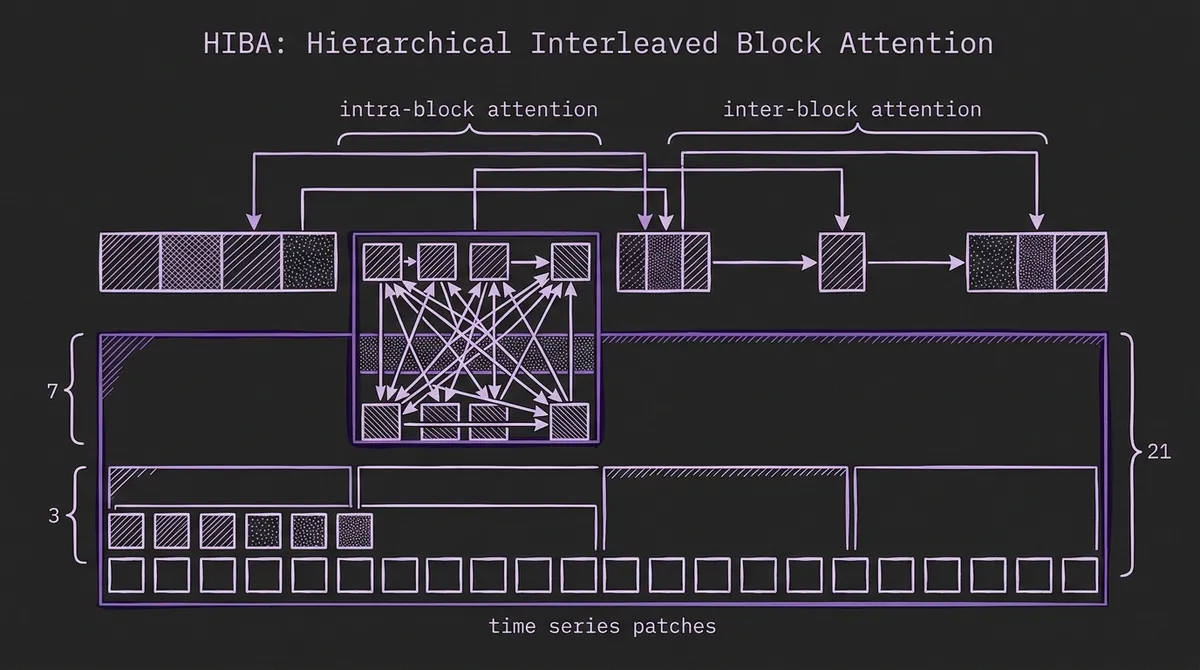
Xihe is a deliberate attempt to break that single-budget assumption. The model introduces Hierarchical Interleaved Block Attention (HIBA), a sparse layout that partitions a patched time series into nested blocks at multiple sizes — the paper uses (3, 7, 21) — and stacks transformer layers that alternate between intra-block attention inside small blocks and inter-block attention across blocks at the same hierarchy level. The released family ranges from a 9.5M-parameter Xihe-tiny to a 1.5B-parameter Xihe-max. On GIFT-Eval, Xihe-max reports the top zero-shot CRPS and MASE at submission time, and the 94M Xihe-lite variant beats most contemporary TSFMs while running at a fraction of their inference cost.
#The Problem HIBA Tries to Solve
A typical patched TSFM tokenizes a long input window into fixed-length patches — say, 32 timesteps each — and then applies dense self-attention over the resulting token sequence. On a 16K-context input, that is thousands of patch tokens, and dense attention burns quadratic compute on most of the pairs.
That quadratic budget is also spent badly. A daily retail series wants the model to react sharply to the last few days (point dynamics, holiday spikes), softly to the last few weeks (seasonality, trend slope), and broadly to the last few months (regime, macro). Flat dense attention treats all three scales identically. A long-context model like TimesFM 2.5 or Timer-S1 has the raw context length to see all of this history, but no architectural signal about which scale to weight at which layer.
Sparse attention is the standard answer — and the answer most existing TSFMs duck. The problem is that the sparsity pattern has to match the structure of the signal. Random sparsity throws away correlations. Local-only sparsity loses regime context. Strided sparsity misses irregular seasonality. The bet HIBA makes is that the right pattern is hierarchical and explicit: dense attention within short blocks, sparse attention across blocks at successively larger hierarchical scales.
#How HIBA Works
Each transformer layer in Xihe commits to one of two attention regimes. Intra-block layers run dense self-attention inside a small contiguous block. At block size 3, a patch attends to its two immediate neighbors; at 7, to a one-week neighborhood of daily data; at 21, to roughly three weeks. Inter-block layers do the opposite: tokens that summarize one block attend across blocks at the same hierarchical level, which is how the network carries weekly seasonality, multi-week trend, and regime structure without paying for full attention across the whole sequence.
The interleaving is what makes the scheme work. A single layer of intra-block attention by itself is just a local convolution-shaped operator. A single layer of inter-block attention by itself is a coarse global mixer. Stacking them, with the hierarchy expanding as the network deepens, gives the model an explicit route from local to mesoscale to global structure across depth. Hierarchical block sizes mean compute grows with context far more gently than dense attention — closer to linear than quadratic over the (3, 7, 21) range the paper uses.
This is the load-bearing difference between HIBA and earlier sparse-attention work for time series. It is not a single sparsity pattern bolted onto a standard transformer; it is a layered scheme where the layer index tells the network which temporal scale it is currently operating at.
#A Scaling Family, Not a Hero Model
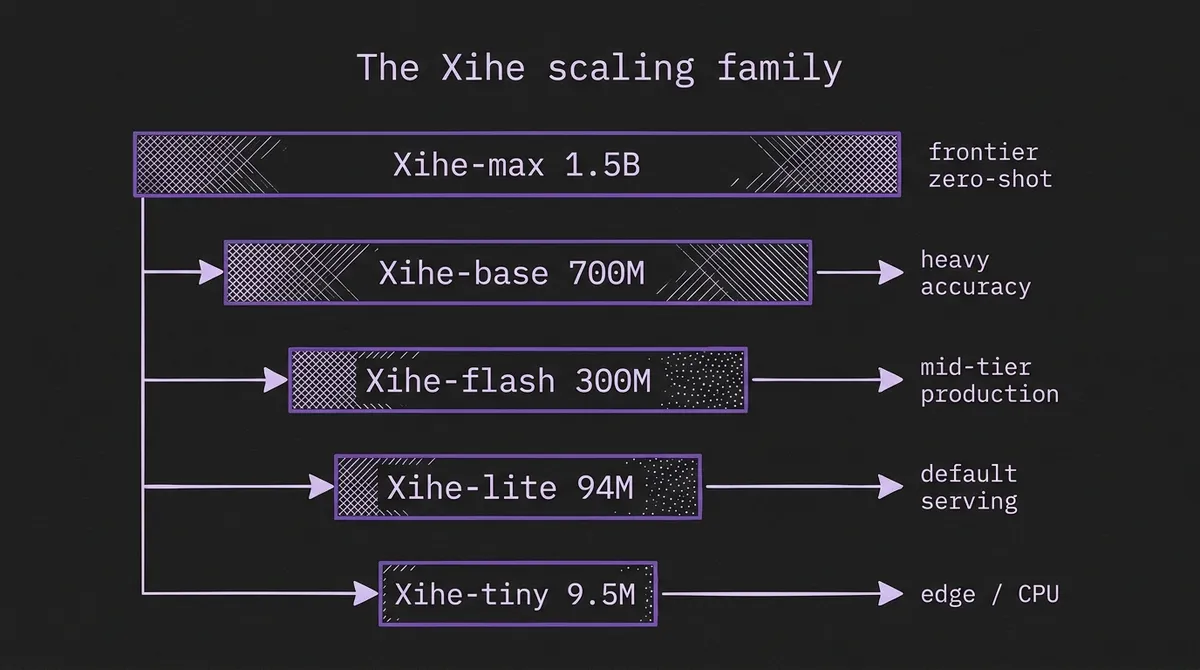
The release ships five sizes spanning two orders of magnitude — Xihe-tiny at 9.5M, Xihe-lite at 94M, Xihe-flash at 300M, Xihe-base at 700M, and Xihe-max at 1.5B. Transformer depth scales from 24 to 96 layers as parameter count grows. Pretraining draws on roughly 325 billion time points assembled from LOTSA, Chronos training subsets, and KernelSynth-style synthetic series. That puts Xihe's pretraining corpus in the same order of magnitude as the largest public TSFM datasets.
The shape of the family is a deliberate response to a year of production lessons. Xihe-tiny is positioned against TTM and FlowState — the niche where the model has to be small enough to embed in feature stores, per-tenant pipelines, and CPU-bound serving paths. Xihe-max is the frontier-quality variant for offline backtests and high-value individual series. The 94M–300M middle is where most users will live, because Xihe-lite already beats Toto-base on the paper's reported numbers despite being a fraction of the parameter count.
#What GIFT-Eval Says
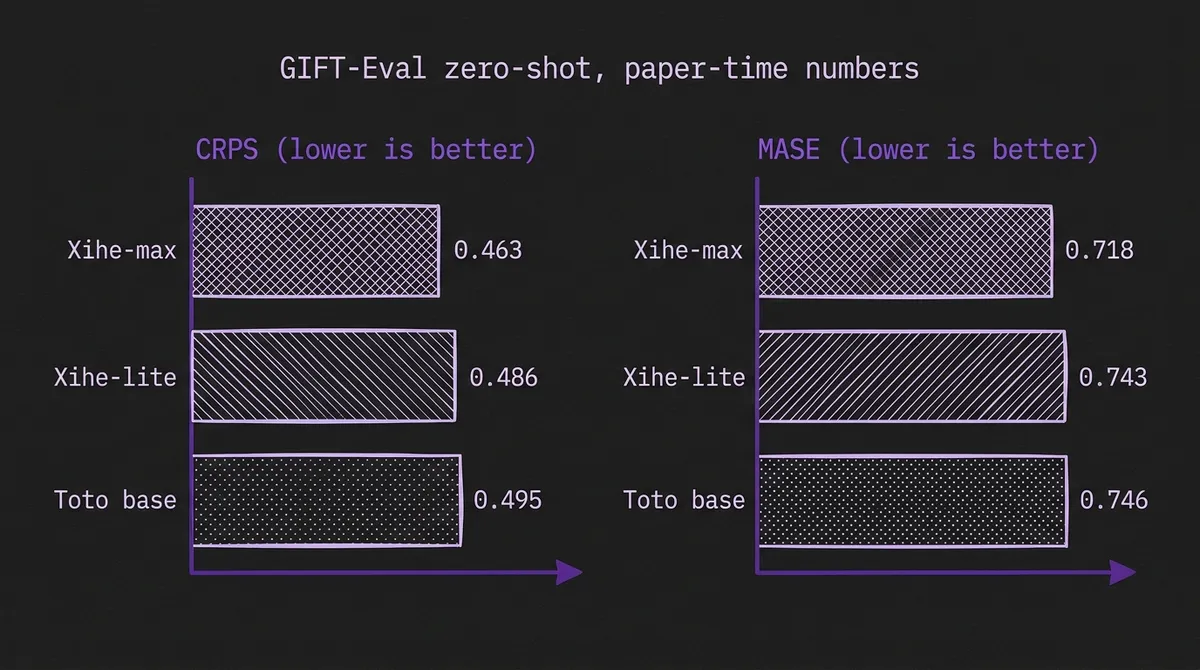
GIFT-Eval is the closest thing the field has to a shared zero-shot scoreboard — 23 dataset groups, 144K+ series, seven domains, ten frequencies — with the usual caveats about contamination and reporting protocol. The Xihe paper reports CRPS 0.463 and MASE 0.718 at Xihe-max, against 0.486 / 0.743 at Xihe-lite and 0.495 / 0.746 at Toto-base. Xihe-lite is a 94M-parameter model coming within roughly 5% on CRPS of a 1.5B model. That gap is small enough that, for most production workloads, Xihe-lite is the more honest default; the 16× parameter difference of Xihe-max only pays back where the marginal accuracy is genuinely worth the inference cost.
The absolute numbers are paper-time, not permanent. The live GIFT-Eval leaderboard refreshes regularly and the field moves quickly. Treat any "best at submission" claim as a snapshot. The more durable signal in the Xihe results is the shape of the curve — CRPS and MASE both decrease monotonically with model size across all five checkpoints, which is far less common in TSFM scaling than it should be. We work through that pattern, and the parallel one Datadog reports for Toto 2.0, in our TSFM scaling-laws synthesis.
Inference is reported on a single NVIDIA A100-80G. Xihe-lite and Xihe-tiny achieve what the paper calls "exceptionally high throughput" relative to similarly accurate baselines, which is the throughput payoff HIBA was designed to deliver — sparser attention should win most at long context, and it does.
#Where HIBA Sits Among Other Recent Architectures
HIBA is one of several time-series-native architecture moves landing in the same window, and the differences matter for how it composes with the rest of the stack.
Moirai-MoE and the Time-MoE line make parameters sparse by routing tokens to expert subnetworks; attention itself stays dense. HIBA is the opposite move — dense parameters, sparse attention. The two are orthogonal, and it is reasonable to expect future TSFMs to combine them.
IBM FlowState drops attention entirely for a state-space recurrence that scales linearly with context. HIBA keeps attention but restructures it, betting that explicit hierarchical structure beats linear recurrence at fixed parameter count, with the trade being more involved engineering.
Toto 2.0 and the Cisco Time Series Model partition attention along the variate axis with alternating time-wise and variate-wise blocks. HIBA partitions along the temporal axis. The two factorizations are complementary, and the most interesting near-term experiment is whether they compose into a model that is hierarchical along time and factored along variates.
Alongside the Cisco multiresolution decoder, CORA's correlation-aware adapter, and the IAmTime instruction-conditioned line, what Xihe makes clear is that the TSFM architectural search space is widening, not narrowing. The "treat patches like language tokens" default is not going away, but it no longer represents the frontier.
#Trying Xihe on Your Data
Xihe-lite is the right place to start. It is the cheapest checkpoint that captures most of the family's quality, and HIBA's throughput advantage shows up most clearly at the long context lengths where Xihe-lite is meant to be used. Compare it against whichever zero-shot model is currently in your production path — TimesFM 2.5, Chronos-Bolt, Moirai 2.0 — on CRPS and quantile-loss numbers rather than point error, because that is where Xihe's reported gains concentrate. If your downstream consumer reads quantile bands directly, the difference matters; if it only ever reads the median, much of the advantage will look invisible.
A second thing worth checking: HIBA's sparsity story is only loud when context greatly exceeds horizon. Energy load, retail demand, and observability series fit that regime; short context windows of 64 or 128 points mostly do not. Run a context-length sweep before locking in a model choice — both the architectural difference and the relevant scaling laws change shape at long context.
The deeper signal Xihe carries is that the field is moving past borrowing architectures from text and into time-series-native design. Attention layout, patching strategy, and multi-scale routing are being shaped by autocorrelation, multi-seasonality, regime drift, and irregular sampling rather than by analogies to language modeling. That changes the answer to the TSFM selection question and the architecture of any model router sitting on top of it. The right zero-shot model for long-context multi-seasonal data will be structurally different from the right one for short-context observability streams or sparse retail tails — and HIBA is one of the first widely available architectures to encode "which scale do I weight, when" directly into its attention design.