iAmTime: Instruction-Conditioned In-Context Learning for Multi-Task Time Series Foundation Models
A new foundation model shows that time series tasks — forecasting, classification, anomaly detection, imputation — can all be specified at inference time through structured input-output demonstrations, without task-specific heads or fine-tuning. The model, iAmTime, achieves best-in-class CRPS on fev-bench and competitive performance on GIFT-Eval using only zero-shot, instruction-conditioned in-context learning.
When in-context learning arrived in language models, the key observation was deceptively simple: if you show a model a few input-output examples, it can generalize the underlying mapping to new inputs — without updating a single weight. The same idea has been making incremental progress in time series, but with a critical limitation: existing approaches use in-context examples only to adapt within a fixed task, almost always forecasting. Show the model related series from your domain, get a better forecast. That is useful, but it leaves a much larger capability on the table.
A March 2026 preprint — arXiv:2603.22586 by Anish Saha and Konstantin Shmakov — proposes a different architecture. Their model, iAmTime, treats the full collection of time series tasks (forecasting, classification, anomaly detection, imputation, source de-mixing) as a single instruction-conditioned in-context learning problem. The task itself is not encoded in model parameters or task-specific heads. It is specified entirely by the structure of the example demonstrations you pass at inference time. Change the demonstrations, change the task — using the same frozen model weights.
#The Core Distinction: Task Specification vs. Domain Adaptation
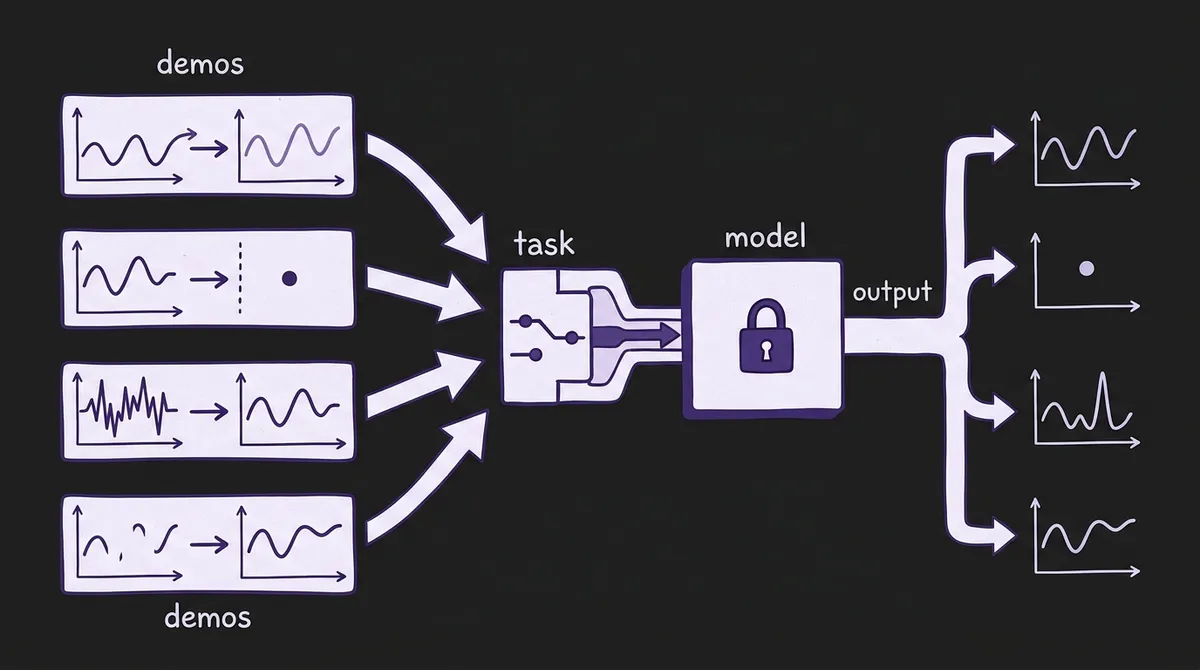
To understand why this matters, it helps to contrast iAmTime with the nearest prior work.
TimesFM's In-Context Fine-Tuning (ICF) prepends related series from the same domain before the target, allowing the model to adapt its forecasting behavior to that domain. The demonstrations are domain examples: "here are other traffic series; now forecast this traffic series." The task is always forecasting. ICF is powerful, but it uses context only to shift the model's distribution, not to redefine what the model is trying to do.
iAmTime encodes tasks through the structure of the demonstration futures. If the example futures are standard time series continuations, the model forecasts. If they are constant scalars encoding class labels, the model classifies. If they are denoised versions of corrupted inputs, the model performs anomaly correction. The model learns — during pretraining via amortized meta-learning — to infer the task semantics from whatever input-output mapping the demonstrations imply. At inference, switching from forecasting to anomaly detection requires no retraining, no adapter, no new weights: you simply restructure the demonstrations.
This is the core claim of the paper, and it is not merely theoretical. The empirical results show that the same architecture, with the same weights, achieves best-aggregate-CRPS on the fev-bench benchmark and competitive scores on GIFT-Eval.
#Architecture: Hierarchical T5 with Structured Tokenization
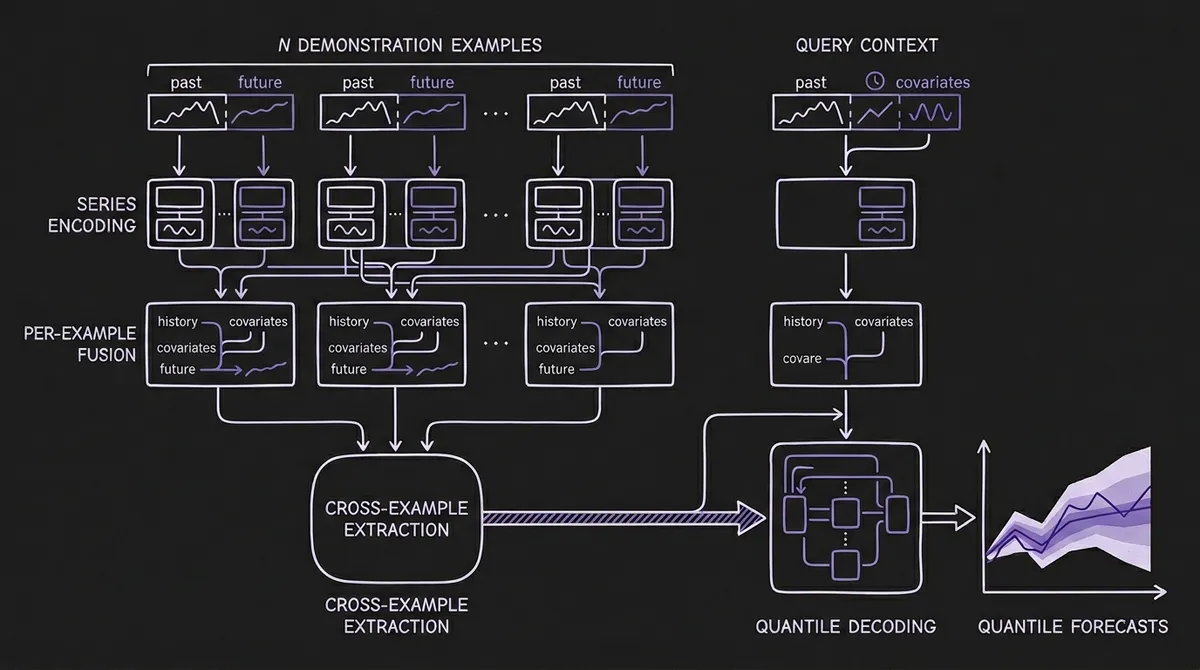
iAmTime is built on a quantile-regression T5 encoder-decoder. The T5 backbone is a natural choice for the encoder-decoder structure: the encoder processes all demonstration examples and the query's historical context; the decoder generates forecast quantiles for the query. But the critical innovation is what sits between the raw time series data and the T5 backbone: a three-stage hierarchical attention stack with explicit semantic role tokenization.
#Structured Tokenization
Each example and query is serialized using a set of specialized semantic role tokens: [START], [TARGET_SERIES], [EXOG], [MID], [FUTURE_EXOG], [END]. These tokens explicitly partition the representation into:
- Historical target series — the input to be analyzed
- Historical covariates — past-only exogenous variables
- Future covariates — known-in-advance exogenous variables (calendar, pricing plans)
- Future targets (in examples only) — what the model should learn to produce
Without these explicit boundary markers, attention layers would mix content across examples and roles, a phenomenon the authors call "representation leakage." A model that cannot distinguish where one example ends and another begins, or which segment is the target history versus the covariate, cannot reliably extract a task-defining input-output mapping.
The paper demonstrates this empirically: naïve concatenation of multiple series without semantic tokens degrades performance below zero-shot baselines — the same failure mode observed in the TimesFM ICF paper when separator tokens are removed.
#Three-Stage Hierarchical Fusion
Once serialized, the representations flow through three attention stages:
Stage 1: Individual series encoding. Each one-dimensional component (target or covariate) is independently encoded by a shared T5 encoder stack, capturing intra-series temporal dependencies. Patch-based representations are used throughout (consistent with Chronos, TimesFM, and Moirai), with patch size p and instance-wise z-score normalization applied per component.
Stage 2: Per-example fusion. Within each demonstration example, the encoded target and covariate representations are concatenated with their semantic role token embeddings and processed by a shared example-level T5 encoder. This stage lets the model build a coherent representation of each individual input-output pair — what the history looked like, what covariates were available, and what the future outcome was.
Stage 3: Cross-example ICL rule extraction. The per-example representations are pooled and aggregated across all N demonstrations using mean pooling (permutation-invariant, parameter-free, robust to variable example counts). The resulting "ICL rule vector" rq is then concatenated with the query representation and processed by a third, cross-example T5 encoder. This is the stage where the model extracts the implicit task mapping from the ensemble of demonstrations and conditions the query decoding on it.
The decoder uses a mixture-of-experts cross-attention mechanism that maps the encoded query representation to 9 quantile predictions across the full forecast horizon in a single non-autoregressive forward pass, avoiding the error accumulation of autoregressive rollouts.
#Amortized Meta-Learning: Five Task Classes
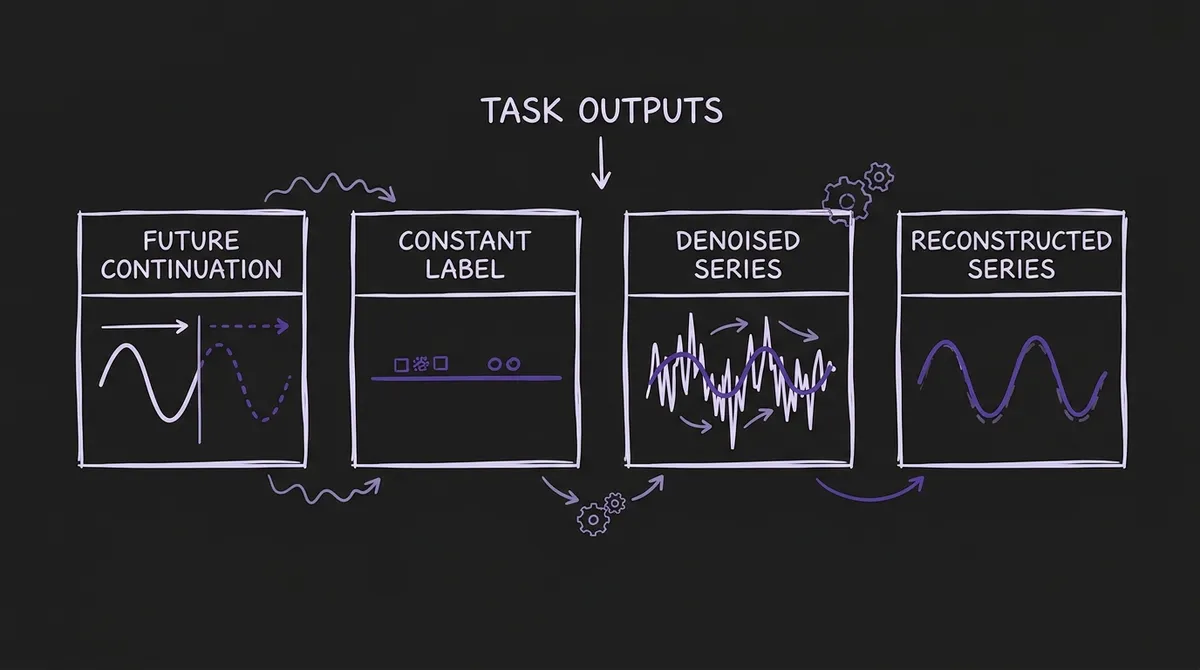
The training procedure is the other major contribution. iAmTime does not train on forecasting alone, then test on other tasks. It trains on a mixture of five structurally distinct task classes, each formulated as an in-context learning episode with examples and a query:
| Task | Example Future | NLP Analogue |
|---|---|---|
| Forecasting | Future continuation of target series | Next-token prediction |
| Imputation / Reconstruction | Clean version of masked input | Masked span prediction |
| Anomaly Detection | Denoised version of corrupted input | Denoising objective |
| Classification | Constant series encoding a class label | Sequence classification |
| Source De-mixing | Residual component from a linear mixture | Unshuffling / separation |
The key insight is that classification and anomaly detection are expressed as time series outputs rather than scalar or discrete predictions. A class label is encoded as a constant-valued series; the model predicts that constant. An anomaly-corrected series is the target output for anomaly detection demonstrations. This avoids the need for task-specific output heads — the same quantile regression decoder handles all five tasks, with task semantics encoded entirely in the demonstration structure.
Training uses curriculum learning: the model starts on shorter contexts with forecasting and imputation, then progressively introduces classification and anomaly detection as the training stabilizes. This mirrors findings in the LLM literature (Garg et al. 2022) that curriculum ordering meaningfully improves in-context learning quality.
The training corpus is roughly 66 million time series: 30M from the Chronos pretraining corpus, 2.5M from the GIFT-Eval pretraining corpus, ~30M generated via TSMixup augmentation, ~10M from KernelSynth (Gaussian-process synthetic generation), and ~50M multivariate series with structured endogenous-exogenous dependencies synthesized using linear, nonlinear, lagged, and cointegration relationships. Test set contamination is carefully avoided: no dataset appearing in fev-bench or GIFT-Eval test splits is included in pretraining.
#Benchmark Results
On fev-bench — 100 forecasting tasks across diverse domains and frequencies — iAmTime achieves the best aggregate CRPS and MASE scores among all evaluated zero-shot models, outperforming Chronos-2, TiRex, TimesFM-2.5, Toto-1.0, Moirai-2.0, TabPFN-TS, and Chronos-Bolt. Classical statistical baselines (AutoARIMA, AutoETS, AutoTheta) perform substantially worse. This is a fully zero-shot evaluation: no fev-bench data appears in iAmTime's training corpus.
On GIFT-Eval — 97 evaluation settings across 24 datasets with short, medium, and long forecast horizons — iAmTime again achieves the lowest aggregate CRPS among fully zero-shot models, with competitive MASE. It outperforms Chronos-2 and TiRex, and substantially outperforms classical baselines, while remaining competitive with models that have partial in-domain training overlap (Moirai 2.0 at 19%, TimesFM-2.5 at 10%).
The paper also evaluates classification and anomaly detection tasks using the same unified model and inference procedure, reporting competitive performance without any task-specific fine-tuning. This is a novel empirical claim: that the same model weights, with appropriate demonstration construction, can serve as a classification model for time series with no architectural changes.
#What This Means for Practitioners
For teams running forecasting at scale. The immediate value is in the fev-bench and GIFT-Eval results: iAmTime provides state-of-the-art zero-shot forecasting performance. As with TiRex's enhanced in-context learning, the model benefits from providing related in-domain series as examples, but the improvement is no longer limited to domain adaptation — the examples shape the entire inference strategy.
For teams needing multiple task types. The more disruptive implication is operational. Currently, deploying anomaly detection, classification, and forecasting on the same time series data requires separate models, separate training pipelines, and separate evaluation frameworks. iAmTime proposes a unified inference interface: structure your demonstrations for the task you need, call the same model endpoint. This mirrors how LLM APIs work in practice: one model, many behaviors, governed by the prompt.
For adaptation without fine-tuning. iAmTime extends the in-context adaptation paradigm beyond domain shift. If your time series has a specific seasonal anomaly pattern you want the model to recognize, you can construct anomaly detection demonstrations that show that exact pattern — no labeled training data beyond the demonstrations, no weight updates. The adaptation generalizes via the model's learned ability to extract task mappings from examples.
Architecture decision implications. The choice of an encoder-decoder (T5) over a decoder-only backbone is deliberate. Decoder-only architectures process examples and query in a single causal sequence, which limits the model's ability to distinguish where examples end and the query begins. The encoder-decoder separation, combined with explicit semantic role tokens, gives the model clean structural boundaries and prevents representation leakage across the ICL prompt. This is a meaningful architectural counterpoint to the decoder-only trend represented by TimesFM, TiRex, and Lag-Llama.
#Connections to Related Work
iAmTime sits at the intersection of several active research threads in the TSFM ecosystem:
-
UniTS (Gao et al., NeurIPS 2024) also proposed a unified multi-task model using task tokenization, but relied on task-specific tokens injected into the input rather than extracting task semantics from input-output demonstration structure. UniTS requires pretraining on each task class; iAmTime's inference-time task specification is more flexible.
-
Chronos-2 uses cross-learning (conditioning on groups of related series), which is a form of multivariate in-context conditioning but does not extend to non-forecasting tasks.
-
TabPFN-TS (Hoo et al., 2025), included as a baseline, represents the tabular prior-fitting approach to time series. Like iAmTime, it exploits in-context examples from the same dataset, but is not trained with amortized meta-learning across multiple task types.
The amortized meta-learning framing connects to MetaICL (Min et al., 2022) in the NLP literature, where training on structured demonstration-query episodes substantially improved in-context learning ability. iAmTime is the first systematic application of this training paradigm to time series across multiple task types.
#Practical Limits and Open Questions
The paper evaluates inference-time classification and anomaly detection but notes that imputation and source de-mixing are not directly evaluated as standalone inference tasks. The reason is practical: these tasks require demonstration construction that is difficult to specify in real-world settings without labeled clean/corrupted pairs. This limits the immediately deployable task set to forecasting, classification, and anomaly detection.
The model also requires that demonstrations be from related time series — the same domain, frequency, and covariate structure as the query. Constructing good demonstrations for a novel domain is a design problem the paper does not fully resolve, though it notes that even self-generated demonstrations (historical windows of the query series itself) provide meaningful improvement over pure zero-shot.
Finally, the inference cost scales with the number and length of demonstrations. A prompt with 10 examples of 512 steps each is substantially larger than a standard zero-shot prompt. The hierarchical attention design reduces cost compared to full cross-attention across the entire concatenated sequence, but practitioners operating at high throughput should budget for the increased context length.
#Looking Ahead
iAmTime represents a genuine architectural shift in how TSFM practitioners should think about model capabilities. The question is no longer only "how accurately does this model forecast?" but "how flexibly can this model adapt its behavior to different tasks at inference time?" The instruction-conditioned ICL framework — tasks defined by demonstration structure, not by model parameters — offers a path toward truly general-purpose time series foundation models.
You can find the full technical details in the paper on arXiv. For current model performance comparisons across forecasting benchmarks, explore our FEV Bench and GIFT-Eval rankings, and try zero-shot and few-shot inference across available models in the TSFM.ai playground.