TSFM Scaling Laws in 2026: What Seven Families Tell Us About Bigger Time Series Models
For most of the time series foundation model era, bigger has not reliably meant better. By mid-2026 the empirical picture has changed: seven released TSFM families — from 1M-parameter Granite TTM up to 8.3B-parameter Timer-S1 — give the field enough scaling data points to talk seriously about scaling laws. Toto 2.0 and Xihe report monotonic scaling at five sizes each; TimesFM 2.5 went the other way and got smaller; Moirai held mostly at Base. This post walks through what each family proves, fits the data against the published TSFM scaling-law literature, and works out what 'compute-optimal' should actually mean when inference dominates total cost.
For the first two years of the time series foundation model era, the question of whether TSFMs obey LLM-style scaling laws was wide open. The data points were partial and scattered. Moirai shipped Small, Base, and Large in 2024, and most users settled on Base because Large's gains were inconsistent across domains. Chronos released a Tiny-through-Large T5 family, where the biggest variants helped, but the smallest models could be beaten by specialist baselines like PatchTST. TimesFM went from 200M to 500M at version 2.0 — and then back to 200M at version 2.5, deliberately, because longer context bought more than added parameters. The published TSFM benchmarking literature spent the same period documenting cases where smaller models beat larger ones on real data.
By mid-2026 that picture has changed. Seven TSFM families with released per-size data points span more than three orders of magnitude in parameter count, from 1M-parameter Granite TTM up to 8.3B-parameter Timer-S1. Four published scaling-law papers (Edwards et al., Yao et al. ICLR 2025, Shi et al., and the skeptical 2026 reply) sit on top of that empirical base. Two May 2026 releases — Datadog's Toto 2.0 and the Xihe HIBA family — are the first releases to publish clean per-size CRPS-rank tables, with monotonic scaling across the entire family on real out-of-distribution benchmarks.
That is enough material to talk seriously about TSFM scaling laws. This post works through what each of the seven families proves about scaling, fits the picture against the published literature, and pulls out what the result means for production teams.
#The Chinchilla Picture, Briefly
A scaling law is an empirical fit between three quantities — model parameters N, training tokens D, and final loss L — under a fixed compute budget. The LLM headline, from Hoffmann et al. 2022 ("Chinchilla"), is a power-law form:
with α ≈ 0.34, β ≈ 0.28, and an irreducible-loss floor E. The takeaway people remember is the 20:1 tokens-to-parameter ratio for compute-optimal training: for every parameter you add, train on twenty more tokens, because spending the same FLOPs in a different ratio leaves performance on the table.
The shape matters because, if a family fits a clean power law, you can predict the loss of the next size up before training it, and "which size should we serve?" becomes an optimization instead of a guess. Until 2026, neither prediction was reliable for TSFMs.
#Why TSFM Scaling Has Been Hard
Three properties of time series make the LLM scaling recipe non-portable. The first is contamination. With text, training on internet snapshots and evaluating on internet text is at least internally consistent. With time series, the public datasets that drive benchmarks — ETTh, Electricity, Weather, M4 and so on — are tiny relative to even one company's internal corpus and are often included in pretraining mixes. A 1B-parameter TSFM that beats a 100M model on a public benchmark may simply have memorized more of the test distribution. Cleanly scoring whether the architecture scales requires evaluation surfaces the model has not seen.
The second is that out-of-distribution scaling diverges from in-distribution scaling. The ICLR 2025 paper Towards Neural Scaling Laws for Time Series Foundation Models is the clearest statement of this. Yao et al. trained TSFMs across parameter counts, compute budgets, and dataset sizes, and showed that architectural choices which improve in-distribution performance can hurt out-of-distribution scalability. That asymmetry has not been a problem for text scaling laws, where ID and OOD usually move together. For TSFMs it is the whole game.
The third is that the "token" itself is a moving target. In an LLM, D is a count of discrete subword tokens. In a TSFM, D could mean raw timestamps, patches, or value-quantized tokens, and the same physical series produces wildly different token counts depending on the tokenizer. Chronos-style value tokenization, the Kronos hierarchical-BSQ tokenizer, and continuous-patch approaches like Moirai 2.0 all give different effective D for the same data. A Chinchilla-style fit only works once you commit to a unit.
Those three properties explain why "does scaling work for TSFMs?" was a genuinely contested question for so long, and why the answer needs to come from a cluster of families rather than a single hero.
#Seven Families, Seven Scaling Stories
What the field has now is enough released-and-benchmarked TSFM families to read scaling behavior off the released data rather than infer it. The seven worth grounding the discussion in:
| Family | Sizes | Pretraining tokens | Scaling story (paper-time) |
|---|---|---|---|
| Granite TTM (IBM) | 1M – 5M | ~250M → ~1B | "Tiny works." TTM-R2 tops GIFT-Eval point accuracy (MASE) at 1–5M params. |
| Chronos T5 (Amazon) | 8M – 710M | ~84B | Monotonic gains across the family, but smaller variants beaten by specialist baselines. |
| Moirai 1.0 (Salesforce) | 14M / 91M / 311M | ~27B (LOTSA) | Modest gains, Base mostly preferred. Moirai-MoE-Small (11M activated) beats all three dense sizes by 3–14% CRPS. |
| TimesFM (Google) | 200M → 500M → 200M | ~100B real points | Reduction at 2.5 was deliberate: longer context (2K → 16K) bought more than added parameters. |
| Toto 2.0 (Datadog) | 4M – 2.5B | ~2.36T points | Clean monotonic scaling on BOOM and GIFT-Eval. "No sign of saturation at 2.5B." |
| Xihe (HIBA paper) | 9.5M – 1.5B | ~325B points | Clean monotonic CRPS and MASE across the family on GIFT-Eval. |
| Timer-S1 (Tsinghua) | 8.3B total / 0.75B active | ~1T points | MoE scaling: 0.75B activated parameters reach the billion-scale frontier on TimeBench. |
Three distinct scaling stories are visible across these seven families.
Dense-parameter scaling, done badly. Moirai 1.0 is the canonical example. The Small-to-Large dense ladder produced gains that were too inconsistent across domains for most users to bother going past Base. The follow-up was Moirai-MoE, where 11M activated parameters beat 311M dense parameters by 3–14% on CRPS — a clean signal that the architectural prior, not the parameter count, was binding on Moirai 1.0's curve.
Dense-parameter scaling, done cleanly. This is what Toto 2.0 and Xihe finally make available. Both ship five sizes across roughly two orders of magnitude. Both report monotonic CRPS-rank improvement at every size. And — crucially for the contamination point — both report it on benchmarks they deliberately did not see in pretraining. Two architectures that share almost nothing structural (alternating time/variate attention with u-µP vs hierarchical sparse attention with standard parametrization) producing similarly clean curves is the signature of a real scaling phenomenon, not an architectural artifact of one family.
Context- and sparsity-as-scale. TimesFM 2.5 is the cleanest counterexample to "more parameters always wins." Google halved parameter count (500M → 200M) while extending context (2K → 16K) and got the top of GIFT-Eval out of it. Granite TTM at the opposite end shows that 1–5M parameter models can sit on top of GIFT-Eval for point accuracy when the architecture and training corpus are right. Timer-S1 shows that scaling the total parameter count through MoE while keeping activated parameters small still moves the curve — 8.3B total / 0.75B activated delivers MASE down 7.6% and CRPS down 13.2% versus Timer-3 on the same TimeBench corpus. The "scaling axis" that matters is not always raw dense parameter count.
The interesting honest claim is not "TSFMs scale" or "TSFMs do not scale." It is that whether a TSFM family scales depends on whether the architecture is scale-clean enough to let scaling show up. Toto 2.0 and Xihe are scale-clean. Moirai 1.0 was not. TimesFM is on a different scaling axis entirely.
#The Two Cleanest Cases
The two families that ship the cleanest evidence for dense scaling are worth pulling the numbers out for, because they are the data points everything else hangs on.
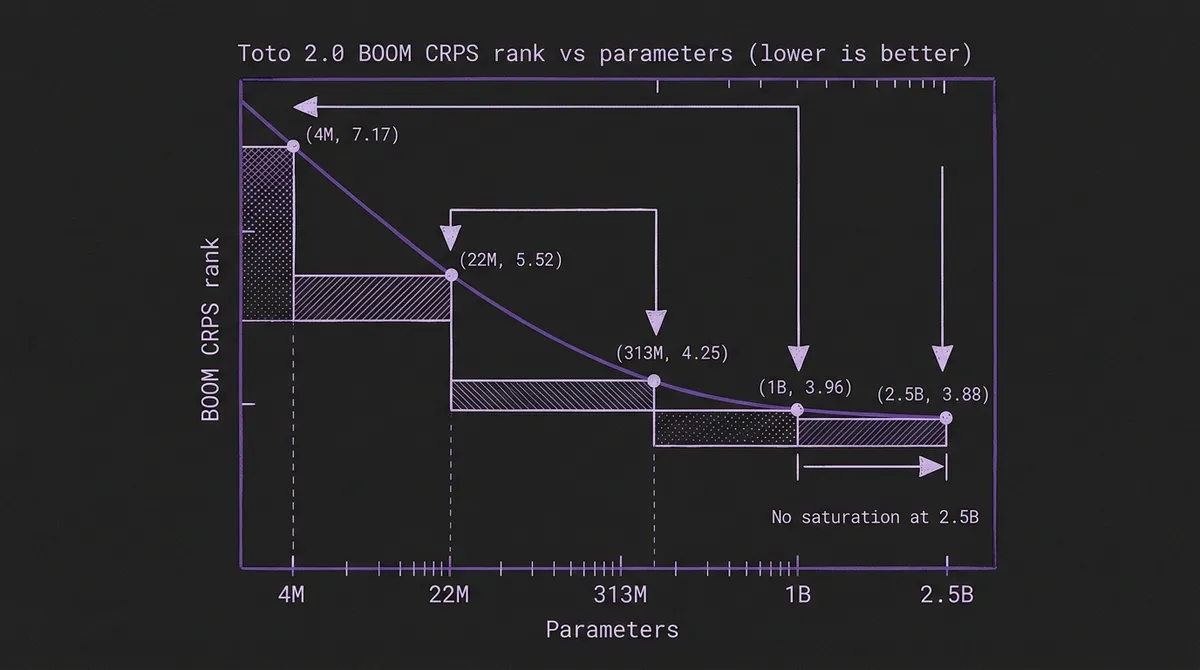
The Toto 2.0 release post and the DataDog/toto repository publish per-size benchmark numbers in plain text. The CRPS-rank tables on the two benchmarks Datadog emphasizes:
| Toto 2.0 size | BOOM CRPS rank ↓ | GIFT-Eval CRPS rank ↓ |
|---|---|---|
| Toto-2.0-2.5B | 3.88 | 19.5 |
| Toto-2.0-1B | 3.96 | 20.3 |
| Toto-2.0-313m | 4.25 | 20.5 |
| Toto-2.0-22m | 5.52 | 25.7 |
| Toto-2.0-4m | 7.17 | — |
The two columns tell consistent stories. On BOOM — the observability-focused benchmark that lives inside Toto's training distribution — the curve is steep and monotonic, and every doubling of parameters meaningfully improves rank. On GIFT-Eval, a general-purpose suite that Toto deliberately did not see in pretraining, the curve is shallower but still monotonic. The TIME benchmark puts the 2.5B, 313m, and 1B variants in its top three positions. Datadog explicitly reports "no sign of saturation at 2.5B" — the curve is still bending downward, not flattening, at the largest size shipped.
The single biggest reason the curve is this clean is u-µP, the Graphcore unit-scaled variant of maximal update parametrization that Datadog adopted. Standard µP keeps activation scales independent of model width so that hyperparameters tuned on a small proxy transfer to the large model; u-µP additionally keeps activations, weights, and gradients at unit scale at initialization. For Toto 2.0, that meant hyperparameters were tuned once on a small proxy and reused at every size up through 2.5B. Every checkpoint was trained at hyperparameters that were supposed to work at that size, rather than re-used from the next size down.
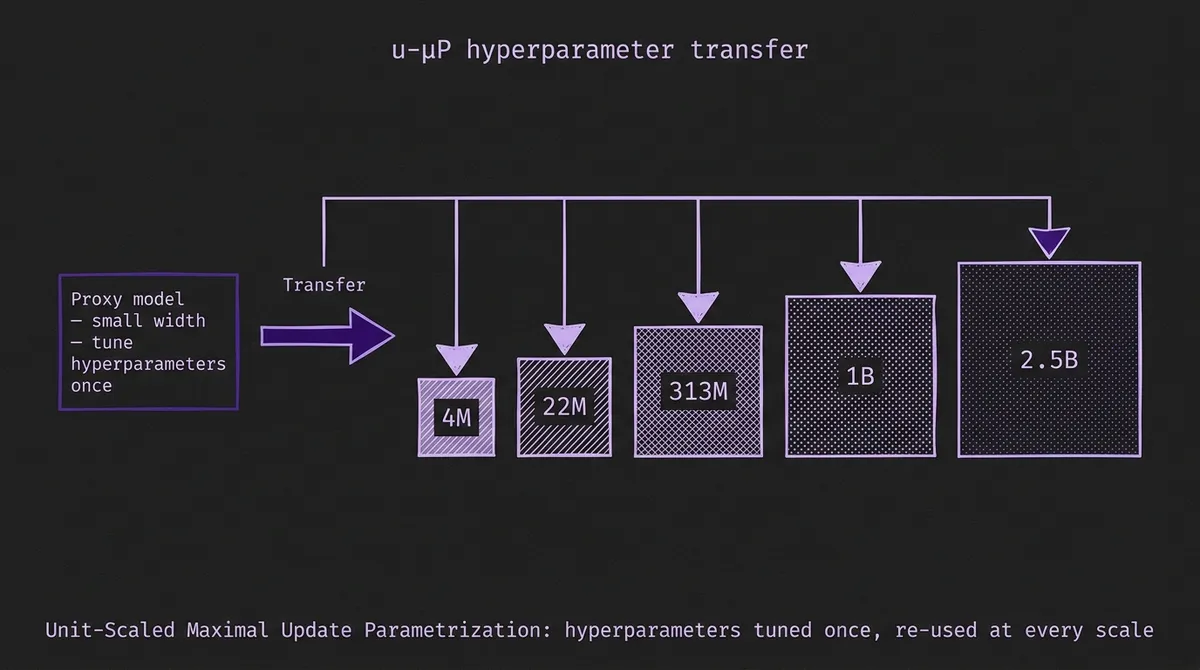
Xihe makes the same case from a completely different direction. The architecture is Hierarchical Interleaved Block Attention (HIBA), a sparse layout with block sizes (3, 7, 21) that alternates intra-block and inter-block attention. There is no u-µP — the paper reports HIBA "preserves the scaling behavior observed in standard Transformers" — and the pretraining corpus is roughly 325 billion time points drawn from LOTSA, Chronos training subsets, and KernelSynth-style synthetic series. The family runs Xihe-tiny at 9.5M through Xihe-max at 1.5B, and CRPS and MASE both decrease monotonically with parameter count across the full range.
That two families with effectively nothing in common architecturally produce the same scaling shape is the load-bearing claim. It is what lets the rest of the discussion talk about TSFM scaling as a phenomenon rather than a Toto property.
#What the Published Scaling-Law Papers Say
Four papers form the published TSFM scaling-law literature, and they line up reasonably well with what the seven-family picture is showing.
Edwards et al. (arXiv:2405.13867) trained decoder-only TSFMs across parameter counts, dataset sizes, and compute budgets covering five orders of magnitude, and reported clean power-law scaling with all three variables. Their headline is that decoder-only TSFMs "exhibit analogous scaling-behavior to LLMs" and that architectural details like aspect ratio and head count have minimal effect over broad ranges. This is the strongest published evidence that a Chinchilla-shaped fit exists for TSFMs at all, and Toto 2.0 / Xihe are exactly the kind of family-level data points that paper's framework predicts should produce clean curves.
Yao et al. (arXiv:2410.12360, ICLR 2025) compared encoder-only and decoder-only TSFM variants and reported two practically important results: encoder-only TSFMs scale better than decoder-only variants on TSFM workloads, and architectural enhancements that improve in-distribution performance can hurt out-of-distribution scalability. That second finding is exactly the warning that gives the Moirai 1.0 story its shape — the dense-architecture choices that helped in-distribution did not deliver corresponding OOD scaling, which is why Moirai-MoE then beat the dense versions with a fraction of the activated parameters.
Shi et al. (arXiv:2405.15124) proposed a scaling-law form that explicitly accounts for time series granularity and look-back horizon — variables that do not appear in the LLM Chinchilla form. Their headline finding is that optimal look-back length grows with dataset size, and ignoring this term causes the standard power law to under-predict gains from longer context. That is precisely the TimesFM 2.5 story expressed as a scaling law: the right move at 200M parameters with the right context length beats the wrong move at 500M with shorter context.
Does Scaling Law Apply in Time Series Forecasting? (arXiv:2505.10172) is the skeptical reply, arguing that the picture is more conditional than Edwards et al. imply — scaling laws hold cleanly only when pretraining diversity is high and the evaluation distribution overlaps the training corpus in well-controlled ways. The Moirai 1.0 → Moirai-MoE shift is consistent with that view: the dense Moirai family did not have an architecture clean enough to let scaling show up, and adding a sparse-experts layer changed the relevant question entirely.
Stitched together, the picture is that TSFMs scale with power-law-shaped curves comparable to LLMs in functional form. But the exponents depend on architecture, the OOD curve can diverge from the ID curve, and the relevant axis is not always raw dense parameter count.
#How TSFM Scaling Diverges From LLM Scaling
Four divergences are worth keeping in view, because they shape research priorities through the rest of 2026.
The first is that tokens-to-parameter ratios are much higher in TSFM-land. Chinchilla's 20:1 is the LLM compute-optimum; TSFM pretraining corpora are typically far larger relative to model size. Toto 1.0's 2.36T points feeding into a 151M model is closer to 15,000:1, and even at Toto 2.0's 2.5B scale the ratio is around 1000:1 if all the pretraining mass is reused. Timer-S1's ~1T points against 0.75B activated parameters sits around 1300:1. Granite TTM at 1–5M parameters trained on ~1B samples is even higher per-parameter. The corpus story matters far more than the parameter-count story for any team building a domain-specific TSFM.
The second is that architecture sensitivity is higher. LLM scaling laws are roughly architecture-invariant once you fix the family (decoder-only transformer). TSFM scaling laws are not: Yao et al. found encoder-only beats decoder-only on TSFM workloads, but Toto 2.0 and Xihe both ship as decoder-style families that scale cleanly anyway. The reconciliation is that attention layout — alternating time/variate in Toto, hierarchical sparse in Xihe — matters at least as much as encoder-vs-decoder. That is a structural-prior story, not a parameter-count story, and it explains why families with apparently similar architectures (Moirai 1.0 dense vs Moirai-MoE) produce very different scaling curves.
The third is that OOD is the real test. No major LLM benchmark suite is OOD relative to internet-scale pretraining; there is nothing pristine left to test on. TSFMs have the opposite problem, where contamination is easy to introduce and hard to detect. Toto 2.0 explicitly does not see public forecasting data during pretraining, and Datadog is upfront about it. That is the protocol the field needs to converge on if scaling claims are going to be portable. Initiatives like QuitoBench and the BOOM split between train-eligible and held-out data are the early infrastructure.
The fourth is that look-back horizon is its own scaling axis. The Shi et al. scaling law makes explicit what LLM scaling laws ignore: how much history you give the model is itself a tunable, and the optimum grows with data and model size. Context-length engineering is a first-class problem for TSFMs in a way it never was for chat LLMs. TimesFM 2.5's 16K context is the clearest demonstration that, on the inference-aware side of the ledger, more context can dominate more parameters.
#Compute-Optimal — and What "Optimal" Means for a Forecasting System
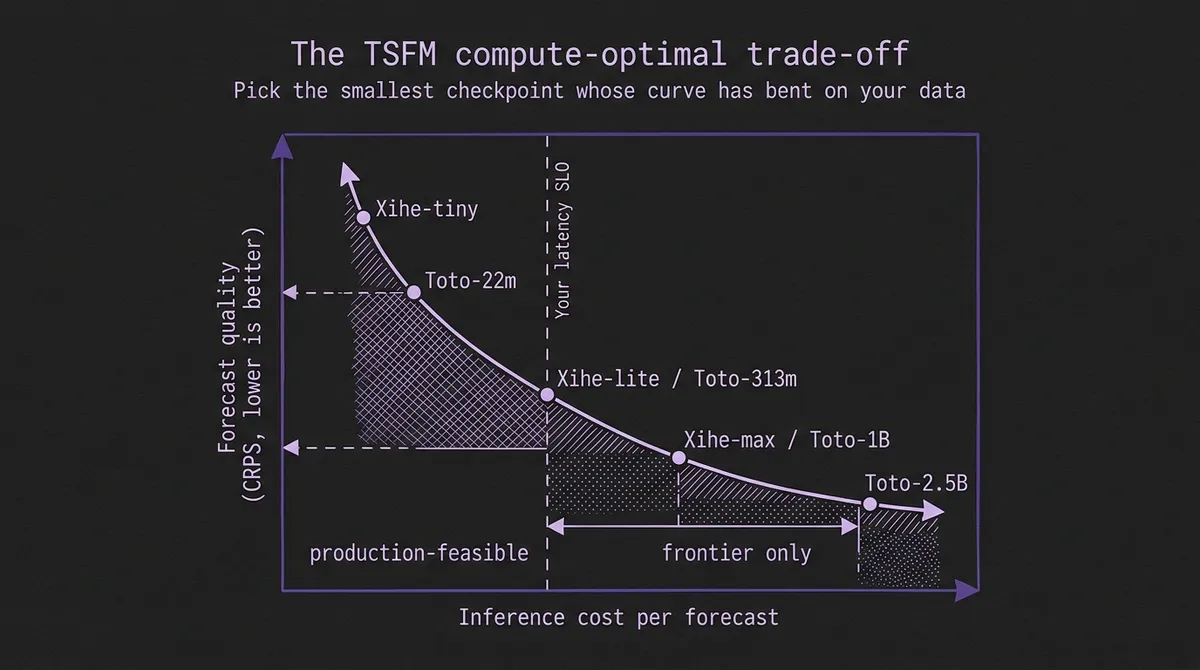
LLM teams talk about "Chinchilla-optimal" as a property of the model. For TSFMs the right framing is "compute-optimal for what you serve," and three production realities make the calculation different.
Inference dominates total cost. A typical LLM application sends a handful of requests per second per user; a typical TSFM application sweeps over thousands of series every forecast cycle, often every minute. Inference compute easily exceeds training compute within months, which is why the "smaller, longer-trained model" argument from Sardana et al.'s inference-aware scaling laws applies more strongly to TSFMs than to LLMs. If a 94M-parameter Xihe-lite trained for an extra epoch serves at five times the throughput of Xihe-base, the extra training is almost always the right trade.
Latency floors are hard rather than soft. Operational forecasting pipelines often live inside SLO budgets — a CPU-utilization forecast that takes 500ms is useless if the alerting pipeline budgets it 50ms. Toto-2.0-22m exists precisely for those floors; Granite TTM at 1–5M parameters exists for floors below that. The benchmark gap to bigger checkpoints is real, but so is the latency gap, and a substantial fraction of production deployments will pick a smaller variant for the latency reason alone.
The practical reading of "no sign of saturation at 2.5B" is that the right size is the smallest size whose curve has bent on your data. If an evaluation curve flattens at 313m, then 313m is the right size — pay for 1B only if it actually closes the gap. If the curve still bends at 1B, the next checkpoint up is worth a serious benchmark slot. The same reasoning applies to Xihe: Xihe-lite at 94M is within roughly 5% of Xihe-max at 1.5B on reported CRPS, which for most production pipelines is not worth a 16× parameter difference, but for a portfolio risk model where the tail matters might be the only thing that matters.
#The Frontier, Through the Rest of 2026
A reasonable forecast — pun acknowledged — for the next twelve months runs along several axes at once. The most likely near-term result is a Chinchilla-style fit grounded in family-level data, because it is now actually possible: an open scaling family (Toto 2.0, Xihe, or whatever Salesforce ships next after Moirai 2.0) trained at multiple compute budgets gives the data points to fit the equation directly. The first paper to publish loss-vs-(N, D) exponents grounded in that data will be the field's reference for years.
Inference-aware compute optima for TSFMs are the more practically urgent follow-up. The Sardana et al. work for LLMs needs a TSFM-specific port that accounts for sweep-style serving, with thousands of forecasts per cycle. The conclusion will likely be that production-deployed TSFMs should be even smaller relative to their training corpus than Chinchilla suggests.
MoE and sparse-parameter scaling is the other open direction. Time-MoE, Moirai-MoE, and Timer-S1 show that sparse-parameter scaling works for TSFMs. The interaction between active-parameter scaling and the TSFM token economy is still mostly unexplored.
Multimodal scaling will eventually have to be added on top. Aurora and the broader multimodal TSFM line sit outside the unimodal scaling story. Once these models start shipping as families, the scaling-law question becomes higher-dimensional: how does loss scale with parameters when modality count is also a variable?
OOD-faithful benchmarks are what makes the rest of the picture credible. QuitoBench, fev-bench, ImpermaNent, and any new entrants will need to publish per-size CRPS tables, the way Datadog and the Xihe authors are starting to, to make cross-family scaling comparisons honest.
#What Production Teams Should Actually Do
The combination of clean scaling curves and inference-aware compute-optimality changes the production workflow in concrete ways. The first move is to audit the current model against the scaling family at matched compute. If Chronos-Bolt-Small is in production today, the right comparison is not "is Toto 2.0 better?" — it is whether Toto-2.0-22m wins at the same memory footprint, or whether Toto-2.0-313m wins at acceptable extra cost. Run the comparison on a held-out distribution, and use conformal calibration for any quantile-band comparisons so the intervals stay honest across model sizes.
The second move is to reconsider the smallest size in production. Toto-2.0-4m, Xihe-tiny (9.5M), and Granite TTM at 1–5M make a class of workloads tractable that previously required either statistical baselines or a much larger model — per-tenant operational metrics, edge devices, real-time alerting. The right benchmark for those checkpoints is not "do they beat the giants?" (they will not) but "do they beat per-series ARIMA at a fraction of the operational complexity?" Often the answer is yes.
The third move is to plan for routing. If a platform serves forecasts across operational telemetry, finance, agriculture, and energy, no single point on the scaling curve is right for all of them. The new generation of TSFM routers treats checkpoint selection as a function of input distribution: Toto-2.0-313m for observability, Kronos-base for finance, Xihe-lite for general-purpose long-context. That is the production architecture the scaling families enable, and it is the part of the scaling story that pays off in real serving costs rather than benchmark numbers.
#The Short Version
The TSFM field reached its scaling moment in 2026 the way most fields do — not through a single paper, but through enough families shipping enough size variants on enough benchmarks that the curves became visible. Toto 2.0 and Xihe show clean monotonic dense scaling. Granite TTM and TimesFM 2.5 show that the small end and the context-length axis still matter. Moirai 1.0 and Moirai-MoE show that the architecture has to be clean enough to let scaling show up. Timer-S1 shows that the MoE axis works.
The practical consequence is that "which TSFM should we use?" is no longer the right question. The right question is "which point on which scaling axis fits our workload's cost, latency, and accuracy budget?" — and the answer for most teams is a small or mid-sized checkpoint, served behind a router, retrained or fine-tuned only when the OOD curve says it is necessary. The frontier checkpoints will keep moving the leaderboards. The deployment story will live, durably, in the middle of the family ladder.