Moirai-MoE: Token-Level Specialization for Time Series Foundation Models
Salesforce's Moirai-MoE replaces Moirai's frequency-specific projection layers with a sparse mixture of experts, enabling automatic token-level specialization. With only 11M activated parameters, Moirai-MoE-Small beats Moirai-Large across 29 Monash benchmarks, and Moirai-MoE-Base outperforms Chronos and TimesFM on zero-shot aggregate metrics.
Every time series foundation model faces a fundamental design question: how do you handle the radical heterogeneity of real-world time series? Retail sales series have different statistical signatures than energy grid readings, hospital vitals, or web traffic. Models that treat all series identically pay an accuracy cost; models that specialize need a way to determine what kind of specialization to apply and when.
The standard answer to date has been frequency-level specialization: treat the sampling frequency as a proxy for pattern type, and maintain separate input/output projection layers for hourly, daily, weekly, and monthly data. Both Moirai and TimesFM use variants of this approach. It is practical and clearly beats having no specialization at all — but it is a human-imposed heuristic that does not match how time series patterns actually distribute.
Moirai-MoE, released by Salesforce AI Research in October 2024, is a direct response to this limitation. It drops frequency-specific projections entirely and instead delegates pattern-matching to a sparse mixture of experts (MoE) inside the transformer, letting the model route each individual token to the two most appropriate experts. The result is automatic, data-driven, token-level specialization — and the benchmarks are striking: Moirai-MoE-Small, with just 11M activated parameters, beats Moirai-Large (310M) in in-distribution evaluation and outperforms Chronos and TimesFM on zero-shot aggregate metrics — even accounting for the fact that some evaluation datasets appear in those models' pretraining corpora.
#The Problem With Frequency-Level Specialization
Moirai solved the multi-frequency problem by maintaining a bank of input and output projection layers — one per frequency band (minutely, hourly, daily, weekly, monthly, yearly). At inference time, you declare the frequency of your series and the model routes it to the matching projection. This reduces the burden on the transformer backbone: each projection layer only needs to learn the tokenization for one frequency family.
The design works reasonably well, but Moirai-MoE's authors identify two structural weaknesses:
Frequency is not a reliable pattern indicator. Two daily series — retail sales and CPU utilization — can look completely different statistically. Conversely, an hourly weather series and a 15-minute energy series might have similar local dynamics. Grouping them by frequency forces the model to handle heterogeneous patterns with the same projection, increasing the effective complexity that the backbone must absorb.
Non-stationarity defeats coarse-grained grouping. Even within a single series, distribution shifts are common. A daily sales series may look trend-dominated for six months, then exhibit strong weekly seasonality after a product launch, then plateau. Frequency-level specialization assigns the same projection to all windows of that series regardless of how its local behavior has changed. The model must handle within-series distribution shifts with no specialization signal at all.
Token-level specialization addresses both problems by making routing a learned function of the data, not a manually specified function of the frequency label.
#Architecture: Single Projection + Sparse MoE
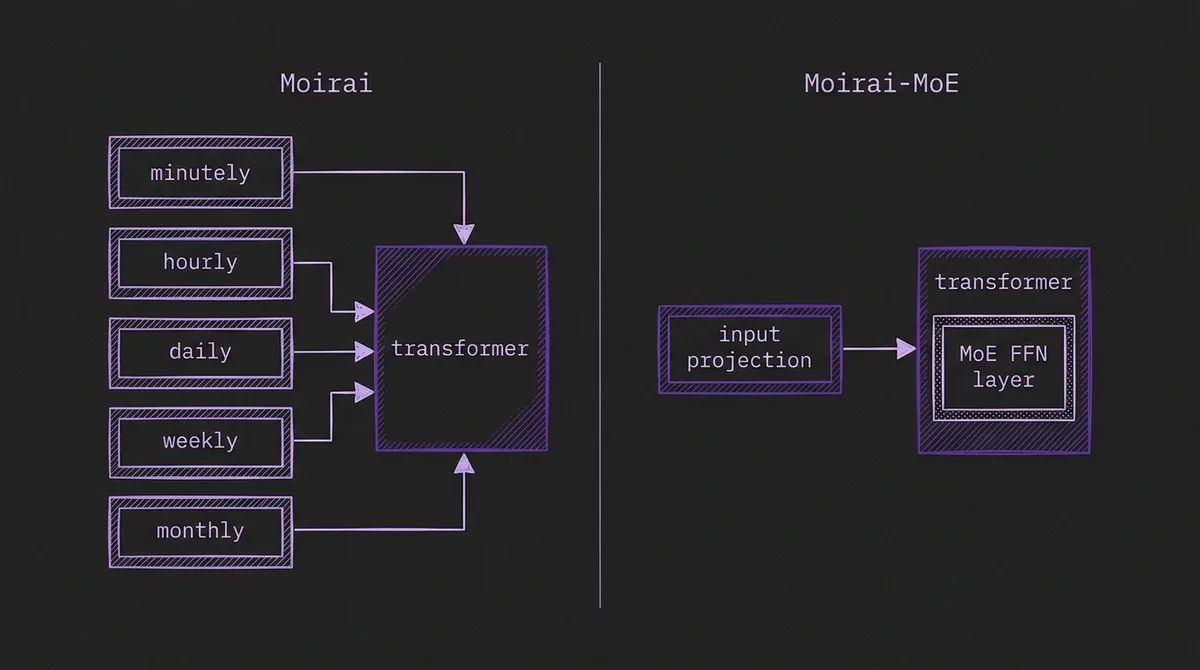
Moirai-MoE inherits Moirai's patching strategy (non-overlapping patches of size P=16) and its mixture-distribution output head (a mixture of location-scale distributions supporting flexible probabilistic forecasts). The two major architectural changes are:
1. Single unified projection layer. Where Moirai uses N frequency-specific projection layers, Moirai-MoE uses one. The burden of handling heterogeneous patterns shifts from the projection to the transformer backbone — specifically, to the MoE layers inside.
2. MoE feed-forward layers. Each transformer block replaces its single FFN with an MoE layer: M=32 expert FFNs and a gating function. For each token, the gating function selects K=2 experts, and the token is processed by only those two. The output is a weighted sum of the two selected experts' outputs, with weights given by the gating scores.
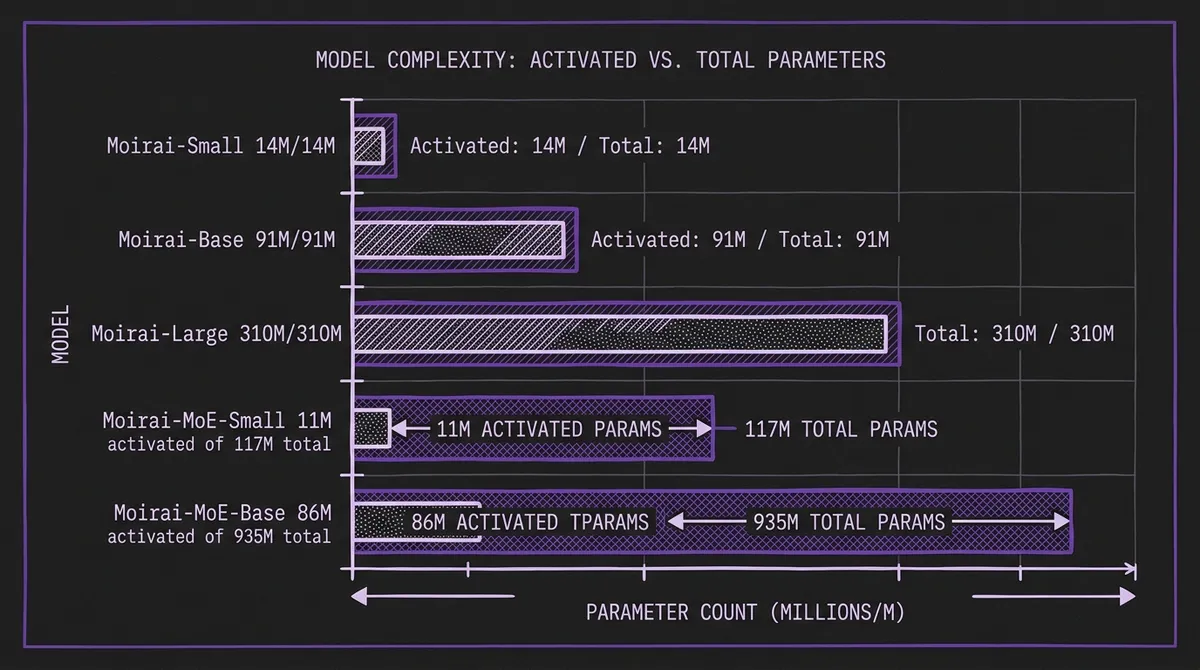
This sparse activation pattern means the model stores 32 expert FFNs but executes only 2 per token. The table below (from the paper) shows how Moirai-MoE achieves near-identical activated parameter counts to the dense Moirai equivalents, while storing substantially more total capacity:
| Model | Activated Params | Total Params | Activated Experts | Total Experts |
|---|---|---|---|---|
| Moirai-Small | 14M | 14M | — | — |
| Moirai-Base | 91M | 91M | — | — |
| Moirai-Large | 310M | 310M | — | — |
| Moirai-MoE-Small | 11M | 117M | 2 | 32 |
| Moirai-MoE-Base | 86M | 935M | 2 | 32 |
The key implication is that inference FLOPs for Moirai-MoE-Small are comparable to Moirai-Small, but the model has access to ten times more total parameters to store learned specializations.
#The Gating Function: Cluster-Initialized Routing
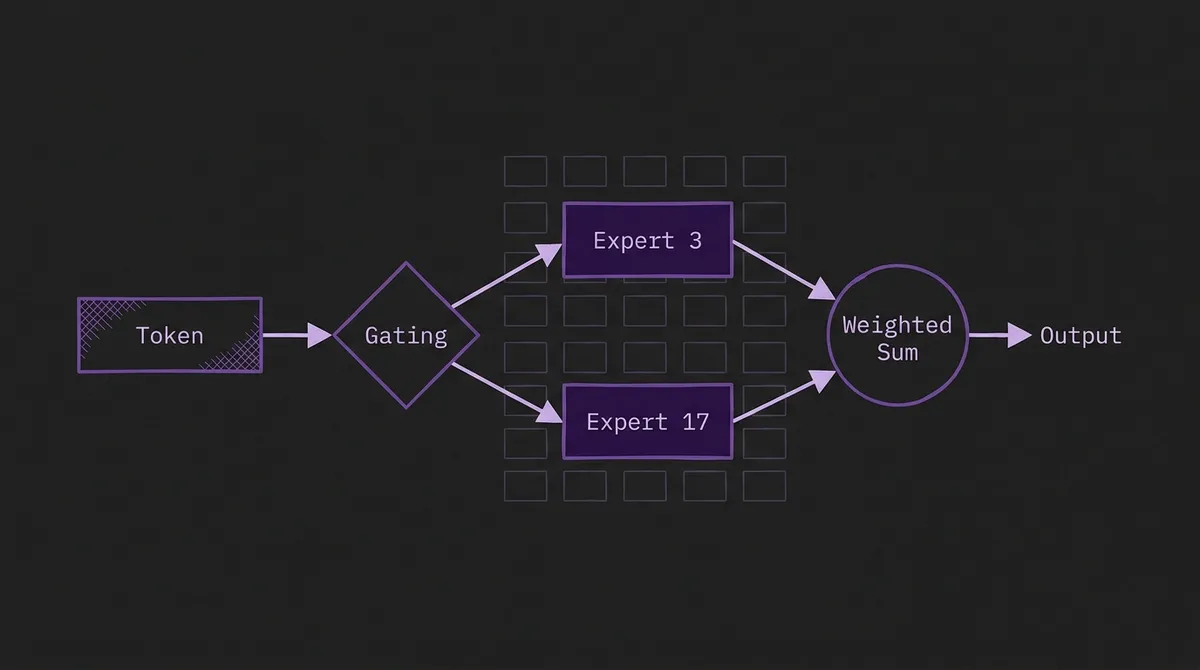
The choice of gating function is consequential for MoE performance. Randomly initialized linear routers are standard in NLP (used by Mixtral, Switch Transformer, DeepSeek-MoE), but they start without any signal about which patterns exist in time series data, which can slow convergence and lead to uneven expert utilization.
Moirai-MoE introduces an alternative: cluster-centroid gating. The approach:
- Run the pretrained Moirai model over a subset of the pretraining corpus and collect the self-attention output representations from each layer.
- Apply k-means clustering to those representations, with k set equal to the number of experts (32).
- Use the resulting cluster centroids as the initial gating targets. Each token's gate score is proportional to its proximity (Euclidean distance) to each centroid.
This initialization gives the router a meaningful prior from the start: tokens that look similar to patterns the pretrained model placed in cluster i are routed to expert i. Ablations in the paper show this improves both final performance and training stability compared to random initialization.
A standard auxiliary load-balancing loss (proportional to the product of fraction of tokens routed to each expert and the router's probability mass assigned to that expert) prevents routing collapse, where most tokens end up at the same two experts.
#Training Objective: Decoder-Only vs. Masked Encoder
Moirai uses a masked encoder training objective: a fraction of input patches are masked, and the model is trained to reconstruct them. This is analogous to BERT in NLP.
Moirai-MoE switches to a decoder-only (autoregressive) objective: each patch predicts the next patch. This is analogous to GPT. The motivation is parallelism: with a decoder-only objective and a masking ratio hyperparameter r=0.3 (30% of each sequence is reserved for normalizer computation, not loss), the model can learn to predict at multiple context lengths within a single forward pass. The masked encoder approach requires separate passes for different context windows.
The ablation in Table 3 of the paper is informative:
| Model Variant | Monash Aggregated MAE |
|---|---|
| Multi-Projection + Masked Encoder (= Moirai-Small) | 0.78 |
| Multi-Projection + Decoder-Only | 0.75 |
| Single Projection + MoE + Decoder-Only (= Moirai-MoE-Small) | 0.65 |
The ablation suggests switching to decoder-only alone yields roughly a 4% gain, with the MoE specialization providing the remaining ~13 percentage points. The two changes are complementary but the MoE is the dominant contributor.
#Benchmark Results
#In-Distribution Evaluation (29 Monash Datasets)
On in-distribution forecasting across 29 Monash benchmark datasets, Moirai-MoE-Small (11M activated parameters) delivers a 17% aggregate MAE improvement over Moirai-Small (14M activated parameters), an 8% improvement over Moirai-Base (91M), and a 7% improvement over Moirai-Large (310M). Moirai-MoE-Base improves a further 3% over Moirai-MoE-Small.
Critically, Moirai could not match Chronos in the original Moirai paper. Moirai-MoE bridges that gap, outperforming Chronos-Small (46M), Chronos-Base (200M), and Chronos-Large (710M) on the same 29 datasets — with up to 65× fewer activated parameters than models it beats.
#Zero-Shot Evaluation (10 Out-of-Distribution Datasets)
On 10 datasets excluded from the LOTSA pretraining corpus, Moirai-MoE-Base achieves the best overall performance across both probabilistic (CRPS) and point forecast (MASE) metrics. This includes outperforming TimesFM and Chronos — even accounting for the fact that some zero-shot evaluation datasets appear in those models' pretraining corpora. Moirai-MoE-Small delivers:
- 3–14% CRPS improvement over all Moirai sizes
- 8–16% MASE improvement over all Moirai sizes
- Achieved with 28× fewer activated parameters than Moirai-Large
These zero-shot gains matter particularly for the benchmarking and production deployment contexts, where the model must generalize to series from domains it has not seen during pretraining.
For practitioners using GIFT-Eval as a primary evaluation framework, Moirai-MoE's zero-shot strength positions it as a strong baseline and a starting point for domain-specific adaptation.
#What the Model Analyses Show
The paper includes interpretability experiments that reveal how Moirai-MoE actually uses its experts. Two findings stand out:
Frequency-invariant representations. Unlike Moirai, which must route hourly series to hourly projections and daily series to daily projections, Moirai-MoE's internal representations are not frequency-stratified. The model learns to represent "trend tokens" and "seasonal tokens" and "noise tokens" — pattern types that cut across frequencies — and routes them accordingly.
Progressive denoising. Expert routing patterns change across transformer layers in a structured way. Early layers route tokens to experts that appear to handle normalization and local context; deeper layers route to experts that specialize in longer-range structure and prediction. This progressive specialization is analogous to what has been observed in well-trained NLP MoE models.
These findings support the paper's core thesis: frequency is a poor proxy for pattern type, and learned token-level routing discovers more meaningful structure.
#Comparing With Time-MoE
Time-MoE, from Xiaohongshu, applies MoE to time series from a different motivation: scale efficiency. Time-MoE's 2.4B-parameter model activates only ~200M parameters per token, making a very large model economical at inference. The MoE mechanism is a way to get more total model capacity without proportionally more inference compute.
Moirai-MoE's motivation is specialization quality, not scale. Its total parameter count (117M / 935M) is modest by modern standards. The MoE enables a model with Moirai-Small-scale inference cost to learn domain-specific routing that a dense model of the same activated size cannot efficiently express. The MoE is not primarily a tool for squeezing more capacity into a given inference budget — it is a structural choice about how to represent heterogeneous pattern families.
The practical implication: Time-MoE makes sense when you need the capacity of a large model but are constrained on inference FLOPs. Moirai-MoE makes sense when you want strong zero-shot generalization across heterogeneous domains without manual frequency-handling logic.
#Practical Deployment
Moirai-MoE weights are available on Hugging Face for Small and Base sizes. Both are accessible via the uni2ts library, which provides a unified inference interface for the entire Moirai family:
from uni2ts.model.moirai_moe import MoiraiMoEForecast, MoiraiMoEModule
model = MoiraiMoEForecast(
prediction_length=24,
context_length=200,
patch_size=16,
num_samples=100,
target_dim=1,
feat_dynamic_real_dim=0,
past_feat_dynamic_real_dim=0,
module=MoiraiMoEModule.from_pretrained("Salesforce/moirai-moe-1.0-R-small"),
)
The interface is identical to the base Moirai — switching from Moirai to Moirai-MoE is a one-line change in the module import. This is significant for teams that have already integrated Moirai into their production forecast pipelines: Moirai-MoE can be dropped in as a performance upgrade without pipeline changes.
One notable architectural difference: because Moirai-MoE replaces frequency-specific projections with a single unified projection, the model does not rely on frequency labels to select a projection layer the way the original Moirai does. In practice this may simplify handling of datasets with mixed or uncertain frequencies, though you should verify current API behaviour against the uni2ts docs for your version.
For teams evaluating whether to use LoRA-based fine-tuning versus a stronger zero-shot model, Moirai-MoE's zero-shot performance across the paper's evaluation benchmarks raises the bar for when fine-tuning is actually needed. If Moirai-MoE-Base's zero-shot performance on your domain already meets your accuracy threshold, the maintenance cost of a fine-tuning pipeline may not be justified.
#Limitations and Open Questions
No Large variant. Moirai-MoE-Large was not trained due to computational constraints. Moirai-Large (310M) is still the largest single Moirai variant. The paper leaves open whether MoE gains compound further at Large scale.
MoE inference infrastructure. The theoretical FLOPs advantage of MoE relies on efficient sparse computation. Naive implementations load all 32 expert FFNs and mask unused ones, which does not save memory bandwidth. Efficient MoE inference requires expert parallelism or sparse kernel implementations. The uni2ts library does not yet expose dedicated MoE serving optimizations; production deployments at high throughput may not fully realize the efficiency gains without additional engineering.
Multivariate correlation handling. Like base Moirai, Moirai-MoE handles multivariate inputs by flattening variates into a single sequence and relying on self-attention across variate-time tokens. This is the same channel-mixing strategy used by the original model, and the MoE change does not directly address the quality of cross-variate correlation modeling. Recent work such as CoRA (arXiv:2603.21828) specifically targets this gap for pretrained univariate TSFMs.
#Conclusion
Moirai-MoE demonstrates that the specialization mechanism matters as much as the backbone architecture. Replacing a hand-crafted frequency heuristic with a learned token-level router — while holding inference cost constant — yields 17% in-distribution gains and strong zero-shot results across heterogeneous benchmarks.
For practitioners, the key takeaway is practical: if you are already using Moirai and have not switched to Moirai-MoE, the upgrade is low-friction (same library, same interface, no frequency annotation required) and the accuracy improvement is material. For researchers, the results suggest that the design space of specialization mechanisms in TSFMs — beyond frequency buckets and language-prompt-based conditioning — deserves more exploration.
Primary sources: Moirai-MoE arXiv paper · Salesforce Research blog · uni2ts GitHub repository · Moirai-MoE-Small on Hugging Face