KairosHope: A Dual-Memory TSFM Built for Classification, Not Forecasting
KairosHope shifts the TSFM conversation from forecasting-first models to specialized classification, combining dual neural memory with classical time-series features, but public checkpoints are not available yet.
Most time series foundation models are still designed around forecasting. The input is a history window, the output is a continuation, and every other task is either a side effect of the learned representation or a separate head attached after pretraining. That framing works for demand planning, infrastructure capacity, and energy load. It is less natural for activity recognition, device-state classification, ECG labeling, fault diagnosis, and other workloads where the primary question is not "what happens next?" but "what kind of sequence is this?"
KairosHope, a May 2026 technical report from the University of Granada and University of Cordoba, takes that classification-first problem seriously. The paper proposes a TSFM architecture built around three ideas: a dual-memory HOPE encoder, a hybrid decision head that fuses neural embeddings with deterministic statistical features, and a staged linear-probing-to-full-fine-tuning protocol for adapting a pretrained backbone to UCR-style classification tasks.
The short version: KairosHope is an interesting classification architecture, especially for domains with real temporal causality such as human activity recognition, sensors, ECG, and motion data. It is not yet a model we can host as a public endpoint. As of May 19, 2026, the paper does not provide a GitHub repository, Hugging Face model, checkpoint link, or artifact-availability section. Searches across Hugging Face Models, Hugging Face Datasets, GitHub repositories, and Papers with Code do not surface public KairosHope weights. We should treat it as a paper to watch, not a deployable model release.
#Why Classification Needs Its Own TSFM Design
Forecasting-oriented TSFMs learn to extrapolate. Classification-oriented TSFMs need to compress an entire observed sequence into a robust label decision. That distinction changes the architecture pressure.
A forecasting model can often survive with a decoder-style next-patch objective, because future generation forces the backbone to learn local continuity, seasonality, and distributional shape. Classification puts more weight on discriminative cues: a short transient, a repeated motion primitive, a frequency-domain signature, or a global contour may determine the label even when it is not the easiest part of the sequence to forecast.
This is why multi-task models such as MOMENT and iAmTime matter. They move beyond pure forecasting and show that shared time-series representations can support classification, anomaly detection, imputation, and other tasks. KairosHope is narrower but more direct: instead of treating classification as one task among many, it makes classification the main adaptation target.
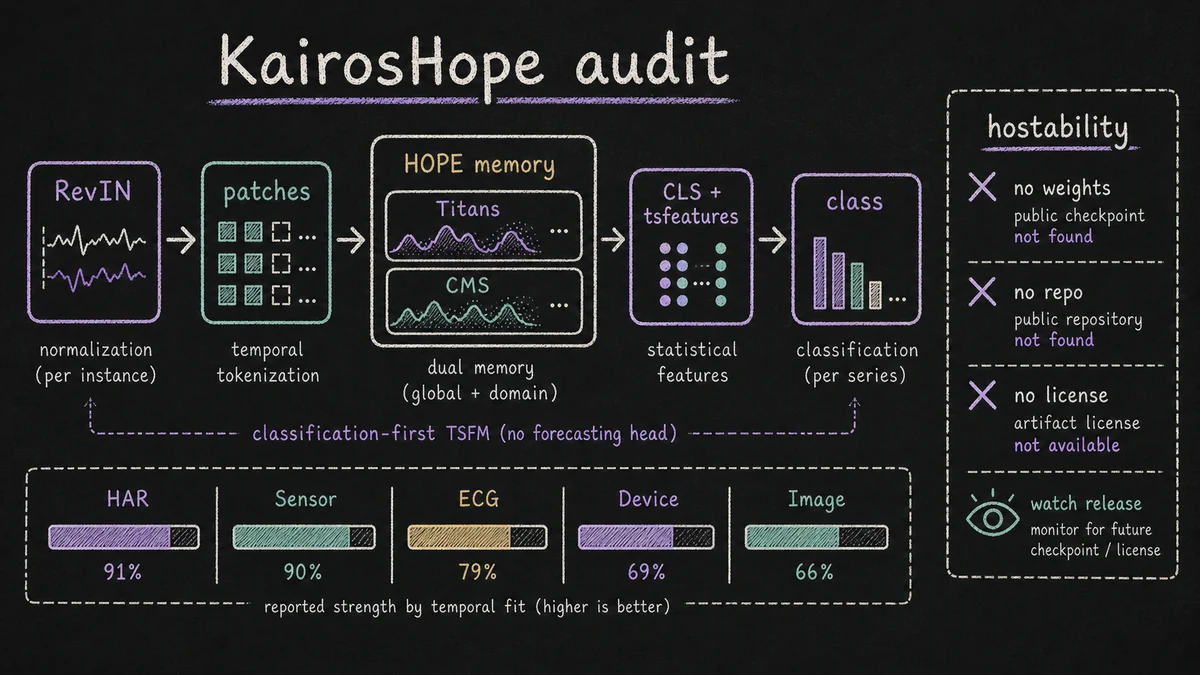
The paper's design starts from a familiar TSFM input path:
| Stage | KairosHope choice | Purpose |
|---|---|---|
| Normalization | RevIN | Remove instance-level distribution shift while preserving invertibility |
| Tokenization | Non-overlapping patches | Reduce sequence length and capture local temporal semantics |
| Sequence representation | [CLS] token plus positional encoding | Produce a sequence-level representation for classification |
| Encoder | HOPE blocks with Titans and CMS memory | Replace quadratic attention with dual memory |
| Decision head | Neural [CLS] embedding plus tsfeatures statistics | Combine learned representation with statistical priors |
The headline difference is not patching; patching is now standard across many TSFMs, as discussed in our tokenization strategy guide. The difference is that KairosHope does not rely on a transformer attention stack as the sole carrier of long-range context.
#The HOPE Encoder: Short-Term Adaptation Meets Long-Term Memory
KairosHope replaces standard self-attention with a HOPE block built from two memory primitives.
Titans memory handles short- to medium-range retention. The paper positions it as a working-memory mechanism that updates as chunks of patches arrive, allowing the model to respond to local volatility and recent dynamics without materializing a full attention matrix over every previous patch. This builds on the Titans line of work, which frames memory as something the model can modify at test time rather than a static cache of key-value states.
Continuum Memory System (CMS) handles longer-range abstraction. Where Titans is local and adaptive, CMS compresses historical representations across hierarchical levels. In the reported configuration, KairosHope uses four CMS hierarchy levels, five HOPE blocks, an input length of 256, patch size 8, and latent dimension 128.
The intended split is straightforward: Titans tracks the "what just happened" dynamics; CMS preserves the "what kind of sequence is this over a longer horizon" context. For classification tasks such as activity recognition or sensor-state detection, that distinction is useful. A model may need to recognize a short gesture burst while also preserving the surrounding cadence or operating regime.
This is a different answer from the usual architecture tradeoffs we see across encoder-only, decoder-only, and encoder-decoder TSFMs. KairosHope's claim is not that one transformer orientation is best. Its claim is that classification benefits from explicit memory hierarchy, because the discriminative signal can live at multiple temporal scales.
#The Hybrid Decision Head: Neural Features Are Not Enough
The most pragmatic part of KairosHope is its decision head. The model does not ask the neural encoder to discover every useful statistic from scratch. It concatenates the learned [CLS] representation with deterministic features extracted by tsfeatures, including quantities such as autocorrelation, spectral entropy, and seasonal strength.
That design choice is unfashionable in foundation-model circles, but it is defensible. Time-series classification often happens in low-data regimes, and many datasets have strong hand-measurable structure. A fault waveform, a motion signal, or a device trace may be partly separable by simple statistical properties. If those properties are known to matter, forcing the model to rediscover them only through gradient descent is unnecessary.
KairosHope's final representation is:
z = [h_cls || f_ts]
where h_cls is the HOPE encoder's sequence-level embedding and f_ts is the deterministic feature vector. The concatenated representation then passes through normalization, dropout, and a linear classifier.
This puts KairosHope closer to a production-minded hybrid system than a pure scaling paper. It also makes the model's failure modes easier to reason about. If the statistical features carry real semantics, the head helps. If the features are meaningless for the data geometry, the head can become a liability.
#Training: Forecasting Data First, Classification Data Second
KairosHope uses a two-stage training plan.
First, the model is pretrained on a subset of the Monash Time Series Forecasting Archive: m4_hourly, weather, electricity, traffic, and tourism_monthly. This is a forecasting-oriented corpus, but the pretraining objectives are representation-learning objectives rather than direct supervised forecasting:
| Objective | Paper configuration | Intended effect |
|---|---|---|
| Masked Time Series Modeling | Randomly mask 40% of patches and reconstruct them | Learn local and global structure without labels |
| Contrastive learning | InfoNCE over augmented views with 2% Gaussian noise and random scaling | Make representations robust to perturbation |
Second, the pretrained model is adapted to the UCR Time Series Classification Archive through an LP-FT protocol: linear probing first, then full fine-tuning. During linear probing, the HOPE encoder is frozen and only the hybrid decision head is trained. During full fine-tuning, all parameters are unlocked with lower learning rates for the backbone than for the classifier.
This is the same basic stability logic covered in our fine-tuning vs. zero-shot and LoRA/PEFT guides: do not immediately throw noisy task gradients into a pretrained representation unless you have a reason to believe the downstream data is large and clean enough. KairosHope uses full fine-tuning rather than a parameter-efficient adapter, but the staging is similar. Train the head first, then carefully specialize the backbone.
#What the Results Actually Say
The paper evaluates KairosHope on a filtered subset of UCR/BakeOff classification datasets: fewer than eight classes and fewer than 400 time steps per instance. Across that subset, it reports:
| Metric | Reported result |
|---|---|
| Mean test accuracy | 80.11% |
| Mean F1-score | 0.786 |
The category-level breakdown is more informative:
| Dataset type | Mean accuracy |
|---|---|
| HAR | 91.333% |
| SENSOR | 89.600% |
| SPECTRO | 83.671% |
| MOTION | 81.609% |
| ECG | 79.252% |
| SIMULATED | 79.469% |
| DEVICE | 68.551% |
| IMAGE | 66.211% |
This split supports the paper's core inductive-bias argument. KairosHope performs best when the input is a genuine temporal process: body movement over time, sensor measurements, spectrogram-like traces, ECG waveforms. It performs worst on image-derived one-dimensional contours, where the sequence is not really causal. A contour unrolled into a 1D series has arbitrary start and direction choices; the temporal order is a representation trick, not a physical time axis.
That negative result is valuable. It says the model is not a universal sequence classifier. It is a temporal classifier whose memory architecture and statistical head are aligned with real temporal dynamics. For production use, that distinction matters more than a single averaged accuracy number.
#What Is Missing Before This Is Hostable
The paper is a technical report, not a release package. For TSFM.ai hosting, we would need at least four things:
| Requirement | Current status |
|---|---|
| Public checkpoint | Not found |
| Inference code | Not found |
| Model config / preprocessing recipe | Described in the paper, not packaged |
| License and artifact terms | Not provided for weights, because weights are not released |
The paper's arXiv source includes the manuscript, bibliography, and one architecture figure, but no checkpoint manifest, code repository URL, Hugging Face model card, or reproducibility bundle. The absence of a checkpoint is especially important here because KairosHope is not just a simple head on an existing hosted backbone. The HOPE encoder depends on Titans and CMS memory modules, and the hybrid head depends on deterministic tsfeatures extraction. Reimplementing it from the paper would be possible, but hosting that reimplementation would not be the same as hosting the authors' trained model.
There is also a benchmarking gap. The report gives absolute KairosHope results, but the deployment question is comparative: does it beat strong classification baselines, MOMENT-style linear probes, ROCKET/InceptionTime families, or current multi-task TSFMs under the same train/test splits? Without a released checkpoint or a full reproducibility package, that comparison would require rebuilding the model and rerunning the benchmark ourselves.
#How to Think About It Practically
KairosHope is worth tracking because it points at a real gap in the TSFM ecosystem: classification-native foundation models are underdeveloped relative to forecasting models. The architecture is especially relevant for domains where:
| Workload | Why KairosHope's design fits |
|---|---|
| Human activity recognition | Local motion bursts plus longer activity context both matter |
| Industrial sensor state classification | Statistical features and temporal causality are meaningful |
| ECG or biomedical signal labeling | Shape, rhythm, and longer-range context interact |
| Device fault detection | Short transients need to be interpreted against operating regime |
It is less obviously useful for image-contour datasets, arbitrary serialized spatial data, or cases where sequence order is imposed by preprocessing rather than by time. In those settings, a model with geometric invariance or shape-aware inductive bias may be a better fit.
The broader lesson is that "time series" is not one modality. Some sequences are causal temporal processes. Some are spatial contours serialized as time series. Some are multivariate panels where cross-channel structure dominates. A single TSFM architecture can cover several of these regimes, but not all of them equally. KairosHope's strongest contribution is making that alignment explicit.
#Bottom Line
KairosHope is a credible classification-first TSFM proposal: patching and RevIN for robust input handling, dual memory for multi-scale temporal context, self-supervised pretraining for reusable representations, LP-FT for stable specialization, and a hybrid head that brings classical time-series statistics back into the loop.
But it is not hostable today. There are no public checkpoints or inference artifacts I can find, and the paper itself does not point to a repository or model card. The right next step is to monitor for an official release, not to add it to a production model catalog. If the authors release weights, KairosHope should be evaluated immediately on classification-heavy workloads where our current hosted models are least native: HAR, sensors, ECG, and device-state labeling.
Until then, the practical takeaway is architectural: classification-native TSFMs probably should not be treated as forecasting models with a classifier bolted on. KairosHope argues for memory hierarchy plus statistical priors, and the reported category split suggests that the idea is strongest exactly where real temporal causality is strongest.
Primary sources: KairosHope arXiv paper · Titans arXiv paper · tsfeatures documentation · Monash Time Series Forecasting Archive · UCR Time Series Classification Archive