IBM's March 2026 Time-Series Refresh: Four Models, Three Forecasters, and a Surprise
IBM dropped four time-series foundation models on March 31 — FlowState r1.1, TTM-r3, PatchTST-FM r1, and TSPulse r1. Between them they cover point forecasting, probabilistic forecasting, anomaly detection, classification, and imputation. Here is what changed architecturally and why it matters.
On March 31, 2026, IBM Research released four time-series foundation models in a single drop: FlowState r1.1, TTM-r3, PatchTST-FM r1, and TSPulse r1. The announcement frames these as a unified family, and for good reason: the four models collectively span point forecasting, probabilistic forecasting, anomaly detection, classification, imputation, and similarity search, trained on over 100 billion data points.
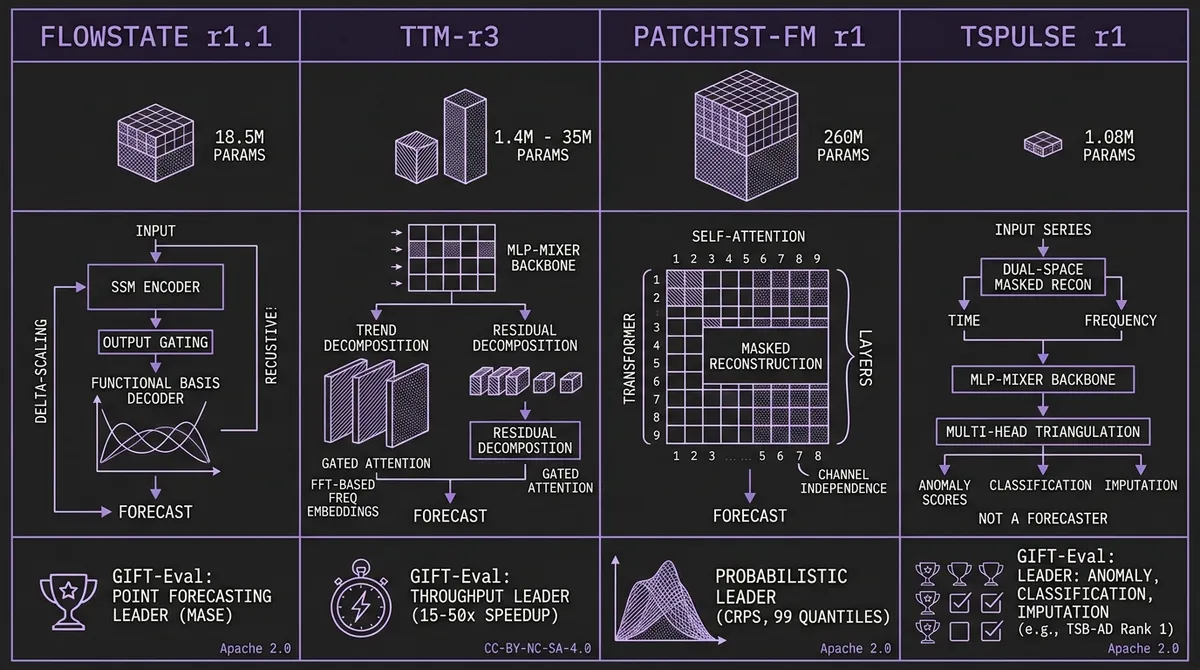
What makes the release technically interesting is not the breadth alone. It is that all three forecasting models now emit quantile forecasts natively — point-only output is no longer the default in IBM's lineup — and that the parameter counts range from 1 million to 260 million, with the GIFT-Eval point-forecasting leader sitting at just 18.5 million. IBM continues to bet that architectural innovation matters more than scale.
#FlowState r1.1: Output Gating, Double the Context
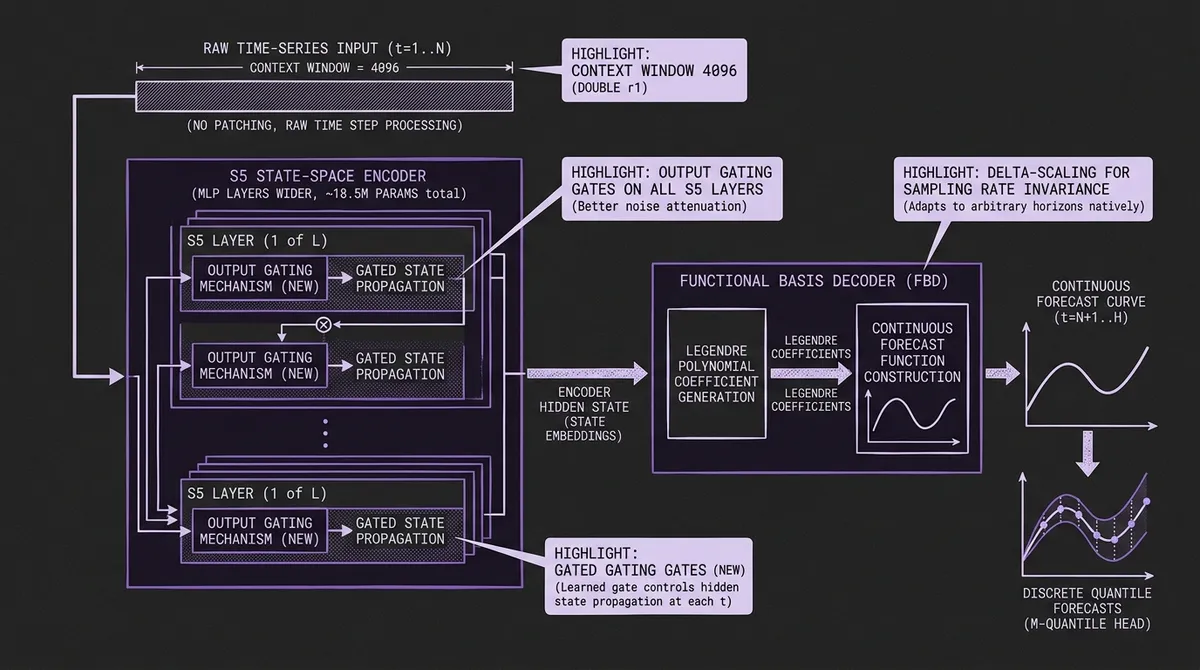
FlowState r1 already sat at the top of the GIFT-Eval zero-shot point-forecasting leaderboard by MASE. Its architecture is unusual among TSFMs: an S5 state-space encoder that processes raw time steps without patching, paired with a Functional Basis Decoder that interprets the encoder output as Legendre polynomial coefficients and constructs a continuous forecast function. The result is a model that adapts to arbitrary sampling rates and forecast horizons through delta-scaling rather than retraining — one checkpoint handles 15-minute, hourly, daily, and weekly data natively.
FlowState r1.1 keeps the full SSM-plus-FBD architecture and adds four things:
Output gating on the S5 encoder. Each S5 layer now includes a learned gate that controls how much of the updated hidden state propagates forward at each time step. The practical effect is better point forecasts on noisy series where r1 could be over-confident — the gate lets the model attenuate spurious state updates rather than integrating every fluctuation into the recurrence.
Context length from 2,048 to 4,096. The pretraining context doubles. For series with long seasonal cycles — monthly data where you need multiple years of history, or hourly data where weekly and annual patterns overlap — seeing more history before producing a forecast translates directly into better accuracy at long horizons.
Parameter count from ~9M to ~18.5M. The MLP layers inside the encoder grow wider. Still dramatically small by TSFM standards: Chronos-Bolt Base is 205M, PatchTST-FM below is 260M, and even Moirai-MoE-Small activates 11M parameters. FlowState leads the point-forecasting leaderboard at a fraction of those sizes.
CauKer synthetic data. The pretraining corpus now includes CauKer-generated synthetic series alongside the existing GIFT-Eval and Chronos training corpora. CauKer extends the KernelSynth approach to synthetic time-series generation, increasing the diversity of patterns the model sees during pretraining.
The training procedure also features an efficient trick: parallel prediction. From a single sequence of length L, the model simultaneously generates forecasts from every context prefix between L_min and L, yielding thousands of training examples per sequence. Combined with causal RevIN normalization to prevent information leakage, this lets IBM train on effectively orders of magnitude more forecast tasks than the raw number of pretraining sequences would suggest.
Status on TSFM.ai: Hosted as ibm-research/granite-timeseries-flowstate-r1.1 alongside the original r1, so you can A/B test before migrating workloads.
#TTM-r3: Five New Heads on the MLP-Mixer
TinyTimeMixer has been IBM's answer to the question of how small a TSFM can be while remaining competitive. The r1 and r2 checkpoints replaced transformer attention with MLP-Mixer blocks and proved that 1M parameters could produce useful forecasts at sub-100ms CPU latency. But they were point-only models — no uncertainty quantification, no probabilistic output.
TTM-r3 changes that. The MLP-Mixer backbone remains (model_type: tinytimemixer), but IBM adds five architectural components on top:
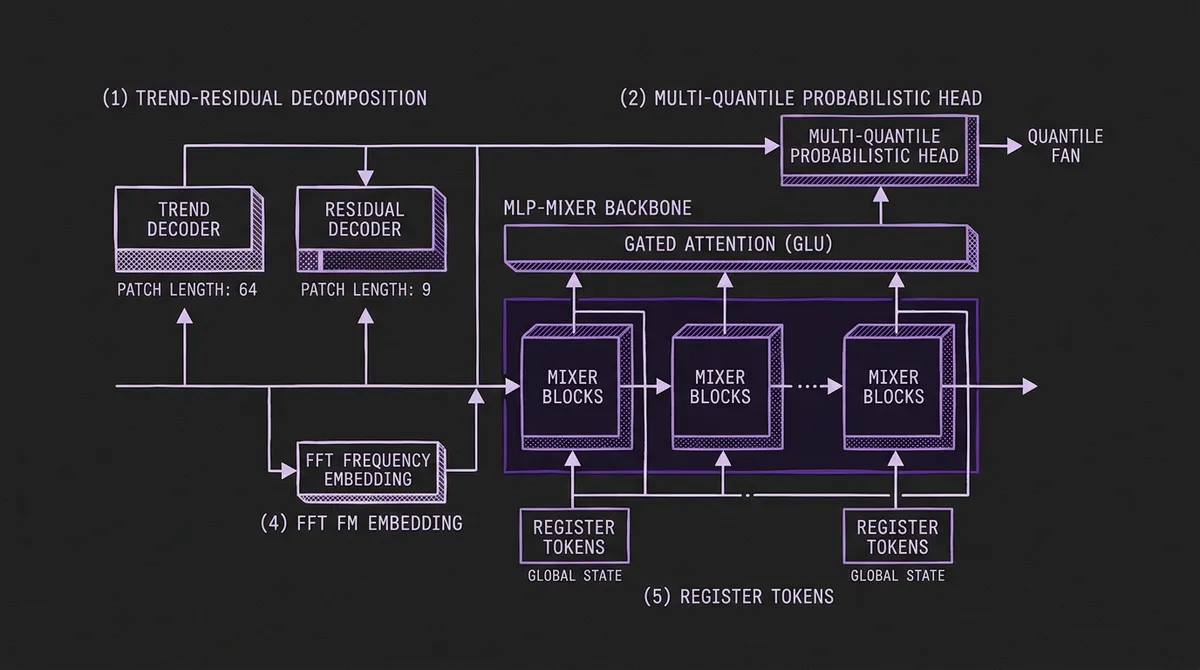
Trend-residual decomposition. The model explicitly separates trend and residual components with separate heads, separate patch lengths (64 for trend, 9 for residuals), and separate decoders. This is more aggressive than the typical decomposition approach: most models use the same resolution for both components. IBM uses a three-stage pretraining process — trend first, then residual, then joint — to let each head specialize before they learn to cooperate.
Multi-quantile probabilistic head. TTM-r3 produces quantile forecasts jointly with the mean objective, using refined loss weighting to balance the trend, residual, and quantile objectives. This is the first TTM variant with probabilistic output, bringing the family into the same prediction interval conversation as Chronos-Bolt and PatchTST-FM.
Gated attention. Despite the MLP-Mixer heritage, r3 adds a gated attention mechanism (GLU-style) on top of the mixer layers. The goal is better information flow on long horizons where the fixed mixing patterns of pure MLP-Mixer layers can underfit complex temporal dependencies — while avoiding the quadratic cost of full self-attention.
FFT-based frequency embeddings. An FFT embedding path gives the model direct access to the frequency domain. Periodic structure that is hard to detect at the patch level — a 168-hour weekly cycle in hourly data, for instance — becomes explicit in the spectral representation.
Register tokens. Two learnable sequence-level tokens provide a place for global, content-addressable state, a pattern borrowed from the vision transformer literature. These act as a compressed summary of the full input that every layer can attend to.
The throughput numbers are striking: ~7,500 samples/sec on GPU for the full variant, ~18,000/sec for the lite variant. On CPU the lite variant manages ~800 samples/sec. This is the source of IBM's claimed 15 to 50x speedup over state-of-the-art forecasters — typical SOTA models achieve 20-500 samples/sec on GPU. Parameter counts range from 1.4M (lite) to 35M (full). On GIFT-Eval, the fine-tuned full variant achieves MASE 0.713 and CRPS 0.512.
Status on TSFM.ai: Hosted as ibm-research/ttm-r3. Note that TTM-r3 ships under a non-commercial research license (CC-BY-NC-SA-4.0). For commercial workloads, the Apache-2.0-licensed TTM-r2 remains hosted and is an excellent alternative for the MLP-mixer-with-small-footprint use case.
#PatchTST-FM r1: The Largest Probabilistic Model in the Catalog
PatchTST-FM r1 is co-developed with Rensselaer Polytechnic Institute under the IBM-RPI FCRC collaboration (arXiv:2602.06909). At ~260M parameters it is by far the largest model in IBM's time-series lineup, and it takes a fundamentally different approach to forecasting than either FlowState or TTM.
The architecture is transformer-based: patch length 16, d_model 1024, with channel independence — each variable in a multivariate series is processed as an independent univariate stream. But the interesting design decision is how forecasting works. PatchTST-FM casts the forecasting problem as masked reconstruction. During training and inference, the model receives an input series with the forecast period masked out (using both contiguous masking for the forecast horizon and random masking for regularization), and reconstructs the full series including the masked region. The forecast is simply the reconstructed values in the masked window.
This framing yields a clean bonus: native missing-value handling. If your input series has gaps, those gaps are just additional masked positions. The model reconstructs them simultaneously with the forecast period, performing imputation and forecasting in a single forward pass. No special preprocessing, no fill-forward, no separate imputation step.
The output head produces 99 quantile levels, giving dense probabilistic coverage across the full predictive distribution. Combined with an 8,192-token context window — the longest in IBM's time-series lineup — PatchTST-FM leads the GIFT-Eval leaderboard for probabilistic forecasting by CRPS.
If you are choosing between PatchTST-FM and FlowState r1.1 for a forecasting workload, the trade-off is roughly: PatchTST-FM offers denser probabilistic coverage (99 quantiles), longer context (8,192 vs 4,096), and native imputation. FlowState offers sampling-rate invariance, a dramatically smaller footprint (18.5M vs 260M), and the best point-forecasting accuracy. Both are available under Apache 2.0.
Status on TSFM.ai: Hosted as ibm-research/granite-timeseries-patchtst-fm-r1.
#TSPulse r1: Not a Forecaster
The most architecturally novel model in the release does not forecast at all. TSPulse r1 (arXiv:2505.13033, accepted at ICLR 2026) is a ~1.08M-parameter MLP-Mixer designed for time-series understanding: anomaly detection, classification, imputation, and similarity search.
The core innovation is dual-space masked reconstruction. TSPulse learns three disentangled embedding views — temporal, spectral (frequency domain), and semantic — and trains by reconstructing masked patches in both the time and frequency domains simultaneously. This dual-space approach forces the model to learn representations that are meaningful in both domains, producing embeddings that are robust to time shifts, magnitude changes, and noise.
For anomaly detection, TSPulse uses multi-head triangulation: it fuses reconstruction deviations from multiple prediction heads to produce robust anomaly scores. For classification and similarity search, the semantic embeddings provide content-based retrieval that works across heterogeneous datasets without fine-tuning.
The benchmark results against models 10 to 100 times larger are striking:
| Task | Improvement | Benchmark |
|---|---|---|
| Anomaly detection | +20% | TSB-AD (Rank 1, univariate and multivariate) |
| Classification | +5-16% | UEA benchmarks |
| Zero-shot imputation | +50% | Standard imputation benchmarks |
| Similarity search | +25% | Semantic similarity benchmarks |
All at 1.08M parameters with GPU-free inference capable of thousands of inferences per second.
Status on TSFM.ai: Tracked in the catalog but not hosted on our inference runtime. Our API is forecasting-centric — every hosted model goes through a predict(values, horizon, quantiles) contract — and TSPulse does not fit that shape. The catalog page links directly to IBM's Hugging Face repository for teams who want to run it for anomaly detection, classification, or imputation.
#What This Release Tells Us
Three signals worth watching:
Quantile heads are becoming the default. FlowState r1.1, TTM-r3, and PatchTST-FM all produce quantile forecasts as part of their primary training objective. Point-only forecasting is becoming the exception in IBM's lineup, and the benchmarks we track are increasingly weighted toward probabilistic metrics like CRPS. If you are still evaluating models on point accuracy alone, you are leaving information on the table.
Small footprints keep winning. The GIFT-Eval point-forecasting leader is 18.5M parameters. The probabilistic throughput champion runs at 18,000 samples/sec on GPU at 1.4M parameters. TSPulse achieves state-of-the-art anomaly detection at 1.08M. IBM continues to demonstrate that architectural innovation outperforms parameter scaling for time series — a sharp contrast with the LLM world's trajectory.
The toolkit is splitting by task. This release does not try to build one model that does everything. FlowState owns point accuracy. PatchTST-FM owns probabilistic density. TTM-r3 owns throughput. TSPulse owns understanding. The era of expecting a single foundation model to be best at all time-series tasks may be ending, replaced by a catalog of purpose-built models selected by workload characteristics — which is exactly the approach the TSFM.ai model catalog was designed around.
All three forecasting models — FlowState r1.1, TTM-r3, and PatchTST-FM r1 — are live in the catalog today. Explore them in the playground or call them directly through the API.